 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving
Jan 29, 2026Autonomous driving is an important and safety-critical task, and recent advances in LLMs/VLMs have opened new possibilities for reasoning and planning in this domain. However, large models demand substantial GPU memory and exhibit high inference latency, while conventional supervised fine-tuning (SFT) often struggles to bridge the capability gaps of small models. To address these limitations, we propose Drive-KD, a framework that decomposes autonomous driving into a "perception-reasoning-planning" triad and transfers these capabilities via knowledge distillation. We identify layer-specific attention as the distillation signal to construct capability-specific single-teacher models that outperform baselines. Moreover, we unify these single-teacher settings into a multi-teacher distillation framework and introduce asymmetric gradient projection to mitigate cross-capability gradient conflicts. Extensive evaluations validate the generalization of our method across diverse model families and scales. Experiments show that our distilled InternVL3-1B model, with ~42 times less GPU memory and ~11.4 times higher throughput, achieves better overall performance than the pretrained 78B model from the same family on DriveBench, and surpasses GPT-5.1 on the planning dimension, providing insights toward efficient autonomous driving VLMs.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
Expertise need not monopolize: Action-Specialized Mixture of Experts for Vision-Language-Action Learning
Oct 16, 2025Vision-Language-Action (VLA) models are experiencing rapid development and demonstrating promising capabilities in robotic manipulation tasks. However, scaling up VLA models presents several critical challenges: (1) Training new VLA models from scratch demands substantial computational resources and extensive datasets. Given the current scarcity of robot data, it becomes particularly valuable to fully leverage well-pretrained VLA model weights during the scaling process. (2) Real-time control requires carefully balancing model capacity with computational efficiency. To address these challenges, We propose AdaMoE, a Mixture-of-Experts (MoE) architecture that inherits pretrained weights from dense VLA models, and scales up the action expert by substituting the feedforward layers into sparsely activated MoE layers. AdaMoE employs a decoupling technique that decouples expert selection from expert weighting through an independent scale adapter working alongside the traditional router. This enables experts to be selected based on task relevance while contributing with independently controlled weights, allowing collaborative expert utilization rather than winner-takes-all dynamics. Our approach demonstrates that expertise need not monopolize. Instead, through collaborative expert utilization, we can achieve superior performance while maintaining computational efficiency. AdaMoE consistently outperforms the baseline model across key benchmarks, delivering performance gains of 1.8% on LIBERO and 9.3% on RoboTwin. Most importantly, a substantial 21.5% improvement in real-world experiments validates its practical effectiveness for robotic manipulation tasks.
SenseExpo: Efficient Autonomous Exploration with Prediction Information from Lightweight Neural Networks
Mar 20, 2025This paper proposes SenseExpo, an efficient autonomous exploration framework based on a lightweight prediction network, which addresses the limitations of traditional methods in computational overhead and environmental generalization. By integrating Generative Adversarial Networks (GANs), Transformer, and Fast Fourier Convolution (FFC), we designed a lightweight prediction model with merely 709k parameters. Our smallest model achieves better performance on the KTH dataset than U-net (24.5M) and LaMa (51M), delivering PSNR 9.026 and SSIM 0.718, particularly representing a 38.7% PSNR improvement over the 51M-parameter LaMa model. Cross-domain testing demonstrates its strong generalization capability, with an FID score of 161.55 on the HouseExpo dataset, significantly outperforming comparable methods. Regarding exploration efficiency, on the KTH dataset,SenseExpo demonstrates approximately a 67.9% time reduction in exploration time compared to MapEx. On the MRPB 1.0 dataset, SenseExpo achieves 77.1% time reduction roughly compared to MapEx. Deployed as a plug-and-play ROS node, the framework seamlessly integrates with existing navigation systems, providing an efficient solution for resource-constrained devices.
An Atomic Skill Library Construction Method for Data-Efficient Embodied Manipulation
Jan 25, 2025



Embodied manipulation is a fundamental ability in the realm of embodied artificial intelligence. Although current embodied manipulation models show certain generalizations in specific settings, they struggle in new environments and tasks due to the complexity and diversity of real-world scenarios. The traditional end-to-end data collection and training manner leads to significant data demands, which we call ``data explosion''. To address the issue, we introduce a three-wheeled data-driven method to build an atomic skill library. We divide tasks into subtasks using the Vision-Language Planning (VLP). Then, atomic skill definitions are formed by abstracting the subtasks. Finally, an atomic skill library is constructed via data collection and Vision-Language-Action (VLA) fine-tuning. As the atomic skill library expands dynamically with the three-wheel update strategy, the range of tasks it can cover grows naturally. In this way, our method shifts focus from end-to-end tasks to atomic skills, significantly reducing data costs while maintaining high performance and enabling efficient adaptation to new tasks. Extensive experiments in real-world settings demonstrate the effectiveness and efficiency of our approach.
UnitedVLN: Generalizable Gaussian Splatting for Continuous Vision-Language Navigation
Nov 25, 2024
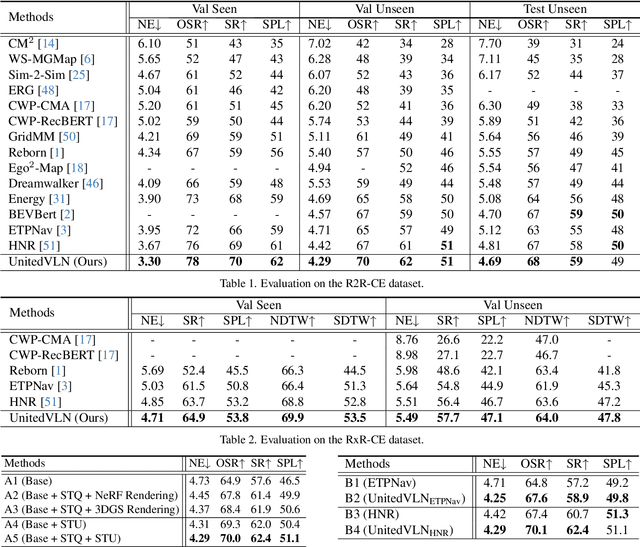
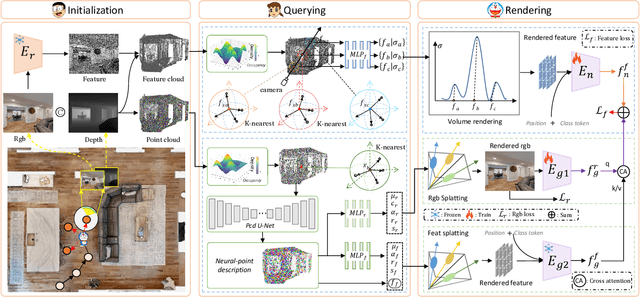
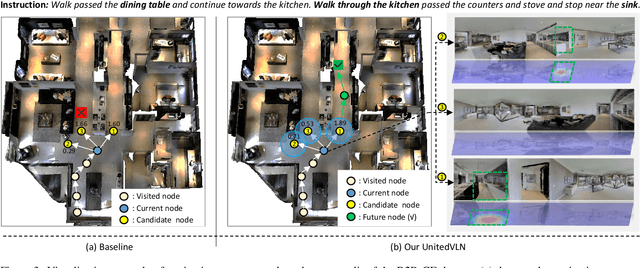
Vision-and-Language Navigation (VLN), where an agent follows instructions to reach a target destination, has recently seen significant advancements. In contrast to navigation in discrete environments with predefined trajectories, VLN in Continuous Environments (VLN-CE) presents greater challenges, as the agent is free to navigate any unobstructed location and is more vulnerable to visual occlusions or blind spots. Recent approaches have attempted to address this by imagining future environments, either through predicted future visual images or semantic features, rather than relying solely on current observations. However, these RGB-based and feature-based methods lack intuitive appearance-level information or high-level semantic complexity crucial for effective navigation. To overcome these limitations, we introduce a novel, generalizable 3DGS-based pre-training paradigm, called UnitedVLN, which enables agents to better explore future environments by unitedly rendering high-fidelity 360 visual images and semantic features. UnitedVLN employs two key schemes: search-then-query sampling and separate-then-united rendering, which facilitate efficient exploitation of neural primitives, helping to integrate both appearance and semantic information for more robust navigation. Extensive experiments demonstrate that UnitedVLN outperforms state-of-the-art methods on existing VLN-CE benchmarks.
Segway DRIVE Benchmark: Place Recognition and SLAM Data Collected by A Fleet of Delivery Robots
Jul 08, 2019
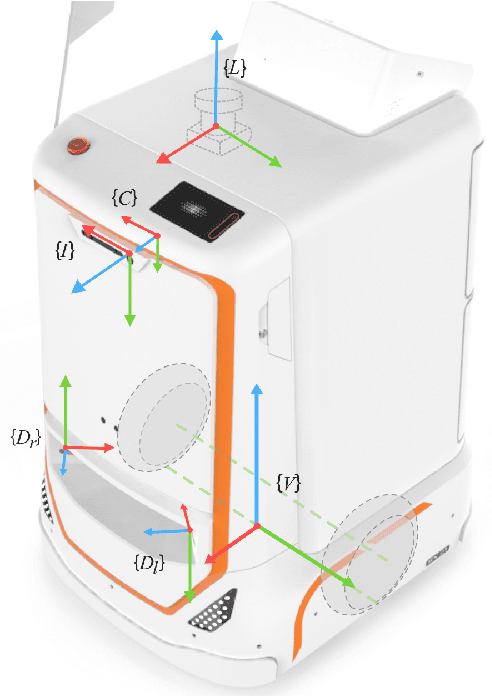
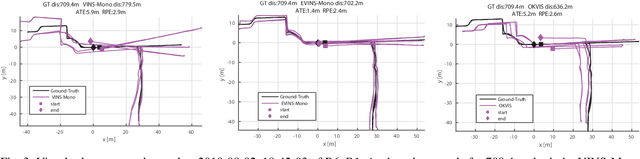

Visual place recognition and simultaneous localization and mapping (SLAM) have recently begun to be used in real-world autonomous navigation tasks like food delivery. Existing datasets for SLAM research are often not representative of in situ operations, leaving a gap between academic research and real-world deployment. In response, this paper presents the Segway DRIVE benchmark, a novel and challenging dataset suite collected by a fleet of Segway delivery robots. Each robot is equipped with a global-shutter fisheye camera, a consumer-grade IMU synced to the camera on chip, two low-cost wheel encoders, and a removable high-precision lidar for generating reference solutions. As they routinely carry out tasks in office buildings and shopping malls while collecting data, the dataset spanning a year is characterized by planar motions, moving pedestrians in scenes, and changing environment and lighting. Such factors typically pose severe challenges and may lead to failures for SLAM algorithms. Moreover, several metrics are proposed to evaluate metric place recognition algorithms. With these metrics, sample SLAM and metric place recognition methods were evaluated on this benchmark. The first release of our benchmark has hundreds of sequences, covering more than 50 km of indoor floors. More data will be added as the robot fleet continues to operate in real life. The benchmark is available at http://drive.segwayrobotics.com/#/dataset/download.