 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Distillation: A Unified Approach to Visual Characteristics Transfer
Feb 27, 2025Recent advances in generative diffusion models have shown a notable inherent understanding of image style and semantics. In this paper, we leverage the self-attention features from pretrained diffusion networks to transfer the visual characteristics from a reference to generated images. Unlike previous work that uses these features as plug-and-play attributes, we propose a novel attention distillation loss calculated between the ideal and current stylization results, based on which we optimize the synthesized image via backpropagation in latent space. Next, we propose an improved Classifier Guidance that integrates attention distillation loss into the denoising sampling process, further accelerating the synthesis and enabling a broad range of image generation applications. Extensive experiments have demonstrated the extraordinary performance of our approach in transferring the examples' style, appearance, and texture to new images in synthesis. Code is available at https://github.com/xugao97/AttentionDistillation.
StyleBlend: Enhancing Style-Specific Content Creation in Text-to-Image Diffusion Models
Feb 13, 2025Synthesizing visually impressive images that seamlessly align both text prompts and specific artistic styles remains a significant challenge in Text-to-Image (T2I) diffusion models. This paper introduces StyleBlend, a method designed to learn and apply style representations from a limited set of reference images, enabling content synthesis of both text-aligned and stylistically coherent. Our approach uniquely decomposes style into two components, composition and texture, each learned through different strategies. We then leverage two synthesis branches, each focusing on a corresponding style component, to facilitate effective style blending through shared features without affecting content generation. StyleBlend addresses the common issues of text misalignment and weak style representation that previous methods have struggled with. Extensive qualitative and quantitative comparisons demonstrate the superiority of our approach.
Deformable One-shot Face Stylization via DINO Semantic Guidance
Mar 04, 2024This paper addresses the complex issue of one-shot face stylization, focusing on the simultaneous consideration of appearance and structure, where previous methods have fallen short. We explore deformation-aware face stylization that diverges from traditional single-image style reference, opting for a real-style image pair instead. The cornerstone of our method is the utilization of a self-supervised vision transformer, specifically DINO-ViT, to establish a robust and consistent facial structure representation across both real and style domains. Our stylization process begins by adapting the StyleGAN generator to be deformation-aware through the integration of spatial transformers (STN). We then introduce two innovative constraints for generator fine-tuning under the guidance of DINO semantics: i) a directional deformation loss that regulates directional vectors in DINO space, and ii) a relative structural consistency constraint based on DINO token self-similarities, ensuring diverse generation. Additionally, style-mixing is employed to align the color generation with the reference, minimizing inconsistent correspondences. This framework delivers enhanced deformability for general one-shot face stylization, achieving notable efficiency with a fine-tuning duration of approximately 10 minutes. Extensive qualitative and quantitative comparisons demonstrate our superiority over state-of-the-art one-shot face stylization methods. Code is available at https://github.com/zichongc/DoesFS
Segway DRIVE Benchmark: Place Recognition and SLAM Data Collected by A Fleet of Delivery Robots
Jul 08, 2019
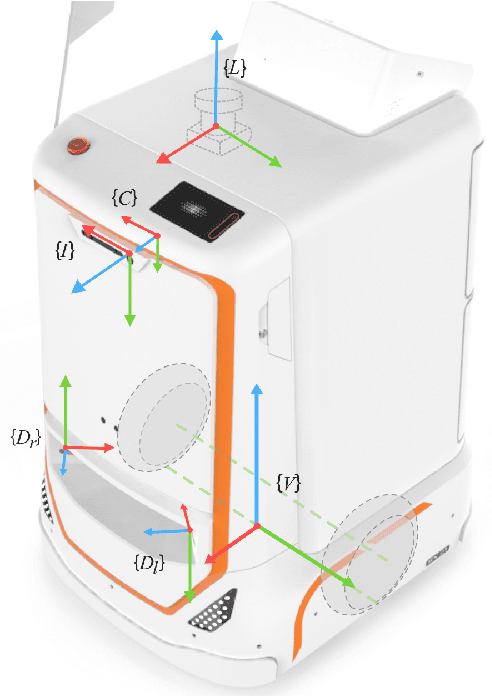
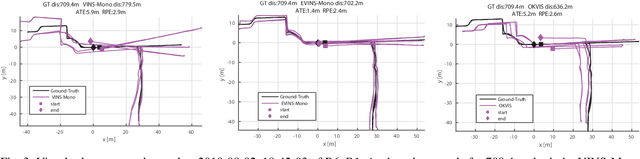

Visual place recognition and simultaneous localization and mapping (SLAM) have recently begun to be used in real-world autonomous navigation tasks like food delivery. Existing datasets for SLAM research are often not representative of in situ operations, leaving a gap between academic research and real-world deployment. In response, this paper presents the Segway DRIVE benchmark, a novel and challenging dataset suite collected by a fleet of Segway delivery robots. Each robot is equipped with a global-shutter fisheye camera, a consumer-grade IMU synced to the camera on chip, two low-cost wheel encoders, and a removable high-precision lidar for generating reference solutions. As they routinely carry out tasks in office buildings and shopping malls while collecting data, the dataset spanning a year is characterized by planar motions, moving pedestrians in scenes, and changing environment and lighting. Such factors typically pose severe challenges and may lead to failures for SLAM algorithms. Moreover, several metrics are proposed to evaluate metric place recognition algorithms. With these metrics, sample SLAM and metric place recognition methods were evaluated on this benchmark. The first release of our benchmark has hundreds of sequences, covering more than 50 km of indoor floors. More data will be added as the robot fleet continues to operate in real life. The benchmark is available at http://drive.segwayrobotics.com/#/dataset/download.