 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Distillation: A Unified Approach to Visual Characteristics Transfer
Feb 27, 2025Recent advances in generative diffusion models have shown a notable inherent understanding of image style and semantics. In this paper, we leverage the self-attention features from pretrained diffusion networks to transfer the visual characteristics from a reference to generated images. Unlike previous work that uses these features as plug-and-play attributes, we propose a novel attention distillation loss calculated between the ideal and current stylization results, based on which we optimize the synthesized image via backpropagation in latent space. Next, we propose an improved Classifier Guidance that integrates attention distillation loss into the denoising sampling process, further accelerating the synthesis and enabling a broad range of image generation applications. Extensive experiments have demonstrated the extraordinary performance of our approach in transferring the examples' style, appearance, and texture to new images in synthesis. Code is available at https://github.com/xugao97/AttentionDistillation.
EMHI: A Multimodal Egocentric Human Motion Dataset with HMD and Body-Worn IMUs
Aug 30, 2024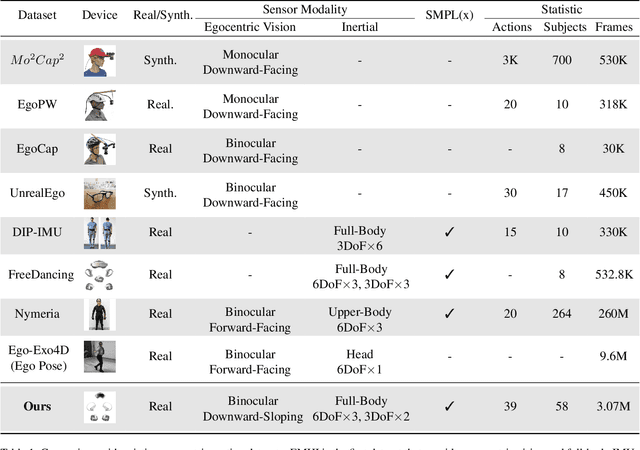
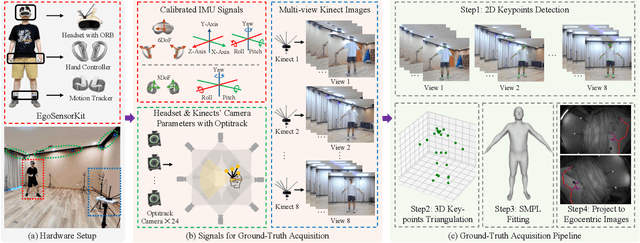
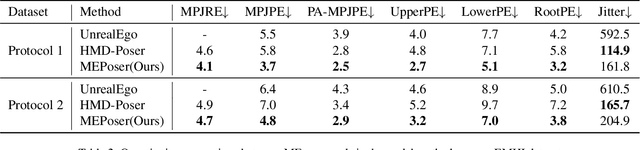
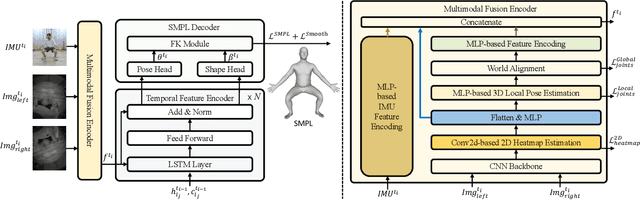
Egocentric human pose estimation (HPE) using wearable sensors is essential for VR/AR applications. Most methods rely solely on either egocentric-view images or sparse Inertial Measurement Unit (IMU) signals, leading to inaccuracies due to self-occlusion in images or the sparseness and drift of inertial sensors. Most importantly, the lack of real-world datasets containing both modalities is a major obstacle to progress in this field. To overcome the barrier, we propose EMHI, a multimodal \textbf{E}gocentric human \textbf{M}otion dataset with \textbf{H}ead-Mounted Display (HMD) and body-worn \textbf{I}MUs, with all data collected under the real VR product suite. Specifically, EMHI provides synchronized stereo images from downward-sloping cameras on the headset and IMU data from body-worn sensors, along with pose annotations in SMPL format. This dataset consists of 885 sequences captured by 58 subjects performing 39 actions, totaling about 28.5 hours of recording. We evaluate the annotations by comparing them with optical marker-based SMPL fitting results. To substantiate the reliability of our dataset, we introduce MEPoser, a new baseline method for multimodal egocentric HPE, which employs a multimodal fusion encoder, temporal feature encoder, and MLP-based regression heads. The experiments on EMHI show that MEPoser outperforms existing single-modal methods and demonstrates the value of our dataset in solving the problem of egocentric HPE. We believe the release of EMHI and the method could advance the research of egocentric HPE and expedite the practical implementation of this technology in VR/AR products.
Explore the LiDAR-Camera Dynamic Adjustment Fusion for 3D Object Detection
Jul 22, 2024Camera and LiDAR serve as informative sensors for accurate and robust autonomous driving systems. However, these sensors often exhibit heterogeneous natures, resulting in distributional modality gaps that present significant challenges for fusion. To address this, a robust fusion technique is crucial, particularly for enhancing 3D object detection. In this paper, we introduce a dynamic adjustment technology aimed at aligning modal distributions and learning effective modality representations to enhance the fusion process. Specifically, we propose a triphase domain aligning module. This module adjusts the feature distributions from both the camera and LiDAR, bringing them closer to the ground truth domain and minimizing differences. Additionally, we explore improved representation acquisition methods for dynamic fusion, which includes modal interaction and specialty enhancement. Finally, an adaptive learning technique that merges the semantics and geometry information for dynamical instance optimization. Extensive experiments in the nuScenes dataset present competitive performance with state-of-the-art approaches. Our code will be released in the future.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023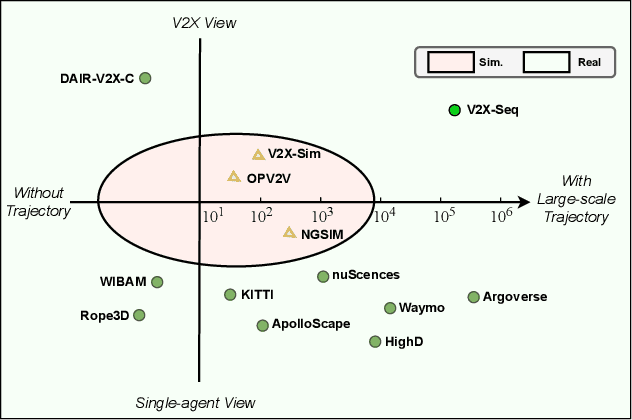
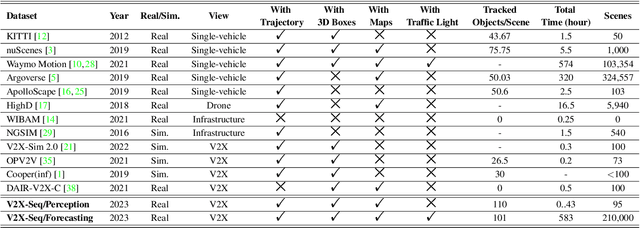
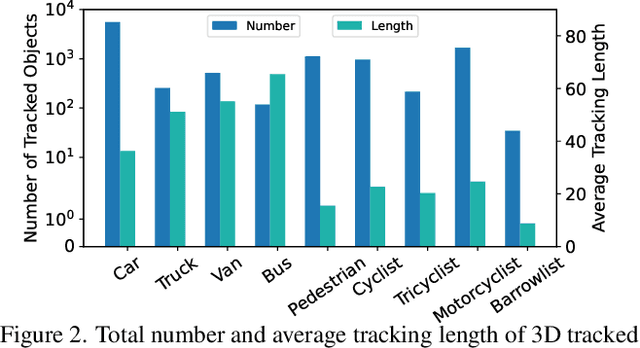
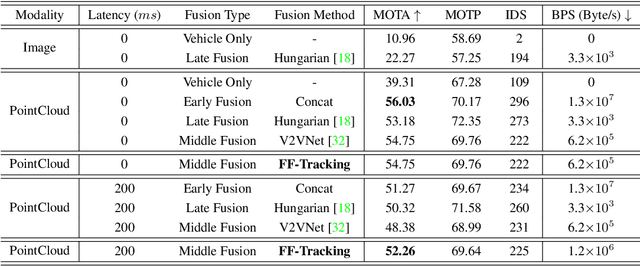
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
A High Fidelity Simulation Framework for Potential Safety Benefits Estimation of Cooperative Pedestrian Perception
Oct 18, 2022
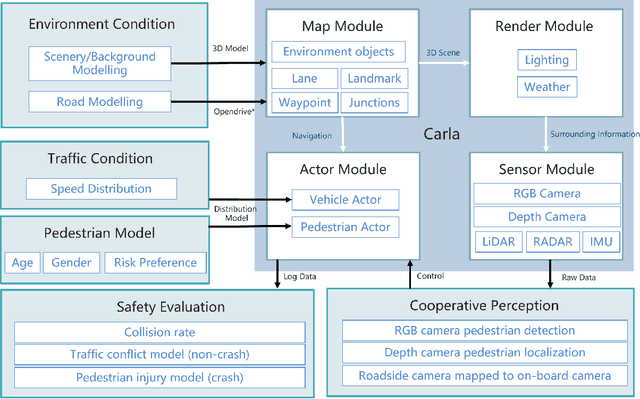
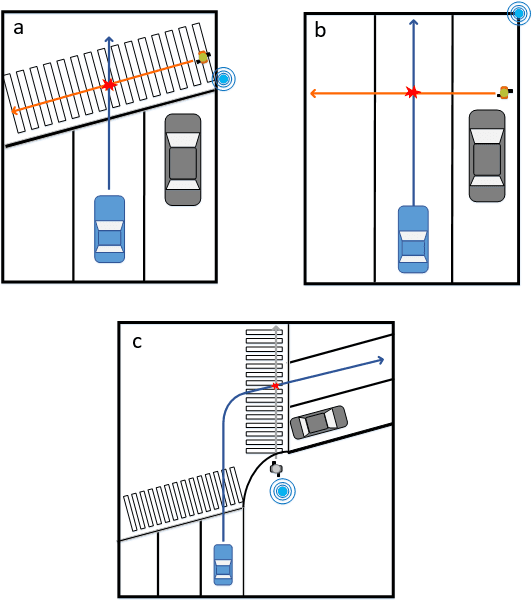
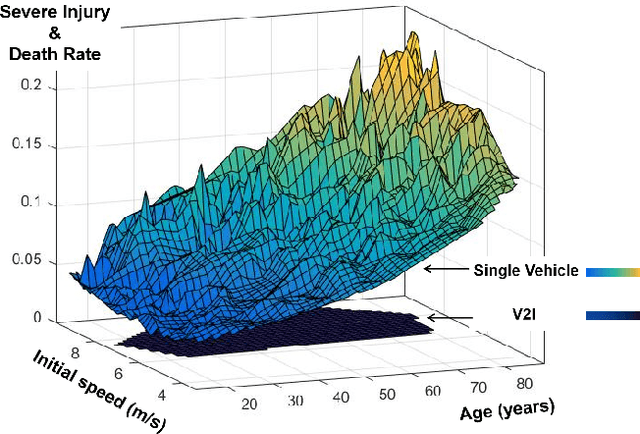
This paper proposes a high-fidelity simulation framework that can estimate the potential safety benefits of vehicle-to-infrastructure (V2I) pedestrian safety strategies. This simulator can support cooperative perception algorithms in the loop by simulating the environmental conditions, traffic conditions, and pedestrian characteristics at the same time. Besides, the benefit estimation model applied in our framework can systematically quantify both the risk conflict (non-crash condition) and the severity of the pedestrian's injuries (crash condition). An experiment was conducted in this paper that built a digital twin of a crowded urban intersection in China. The result shows that our framework is efficient for safety benefit estimation of V2I pedestrian safety strategies.