 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInexact Column Generation for Bayesian Network Structure Learning via Difference-of-Submodular Optimization
May 16, 2025In this paper, we consider a score-based Integer Programming (IP) approach for solving the Bayesian Network Structure Learning (BNSL) problem. State-of-the-art BNSL IP formulations suffer from the exponentially large number of variables and constraints. A standard approach in IP to address such challenges is to employ row and column generation techniques, which dynamically generate rows and columns, while the complex pricing problem remains a computational bottleneck for BNSL. For the general class of $\ell_0$-penalized likelihood scores, we show how the pricing problem can be reformulated as a difference of submodular optimization problem, and how the Difference of Convex Algorithm (DCA) can be applied as an inexact method to efficiently solve the pricing problems. Empirically, we show that, for continuous Gaussian data, our row and column generation approach yields solutions with higher quality than state-of-the-art score-based approaches, especially when the graph density increases, and achieves comparable performance against benchmark constraint-based and hybrid approaches, even when the graph size increases.
Explore the LiDAR-Camera Dynamic Adjustment Fusion for 3D Object Detection
Jul 22, 2024Camera and LiDAR serve as informative sensors for accurate and robust autonomous driving systems. However, these sensors often exhibit heterogeneous natures, resulting in distributional modality gaps that present significant challenges for fusion. To address this, a robust fusion technique is crucial, particularly for enhancing 3D object detection. In this paper, we introduce a dynamic adjustment technology aimed at aligning modal distributions and learning effective modality representations to enhance the fusion process. Specifically, we propose a triphase domain aligning module. This module adjusts the feature distributions from both the camera and LiDAR, bringing them closer to the ground truth domain and minimizing differences. Additionally, we explore improved representation acquisition methods for dynamic fusion, which includes modal interaction and specialty enhancement. Finally, an adaptive learning technique that merges the semantics and geometry information for dynamical instance optimization. Extensive experiments in the nuScenes dataset present competitive performance with state-of-the-art approaches. Our code will be released in the future.
Mobius: A High Efficient Spatial-Temporal Parallel Training Paradigm for Text-to-Video Generation Task
Jul 12, 2024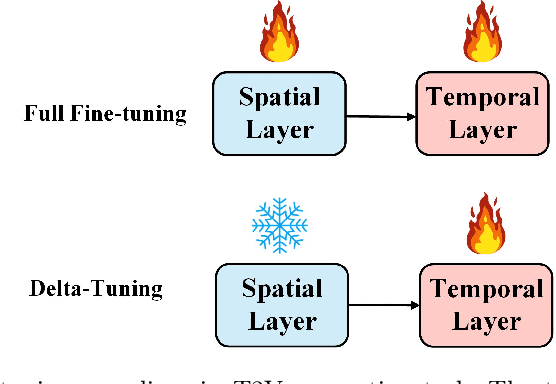
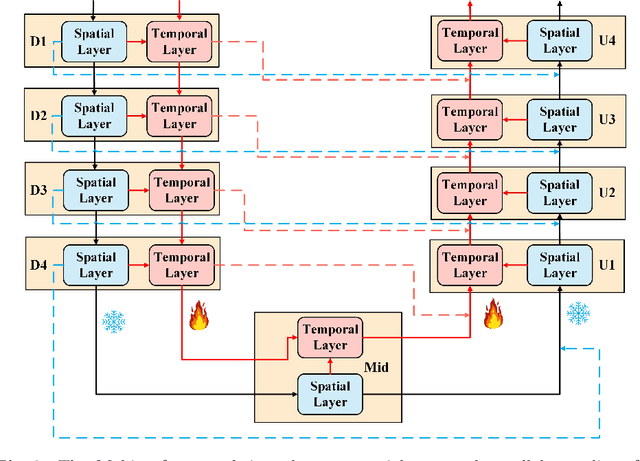

Inspired by the success of the text-to-image (T2I) generation task, many researchers are devoting themselves to the text-to-video (T2V) generation task. Most of the T2V frameworks usually inherit from the T2I model and add extra-temporal layers of training to generate dynamic videos, which can be viewed as a fine-tuning task. However, the traditional 3D-Unet is a serial mode and the temporal layers follow the spatial layers, which will result in high GPU memory and training time consumption according to its serial feature flow. We believe that this serial mode will bring more training costs with the large diffusion model and massive datasets, which are not environmentally friendly and not suitable for the development of the T2V. Therefore, we propose a highly efficient spatial-temporal parallel training paradigm for T2V tasks, named Mobius. In our 3D-Unet, the temporal layers and spatial layers are parallel, which optimizes the feature flow and backpropagation. The Mobius will save 24% GPU memory and 12% training time, which can greatly improve the T2V fine-tuning task and provide a novel insight for the AIGC community. We will release our codes in the future.
Mobius: An High Efficient Spatial-Temporal Parallel Training Paradigm for Text-to-Video Generation Task
Jul 09, 2024Inspired by the success of the text-to-image (T2I) generation task, many researchers are devoting themselves to the text-to-video (T2V) generation task. Most of the T2V frameworks usually inherit from the T2I model and add extra-temporal layers of training to generate dynamic videos, which can be viewed as a fine-tuning task. However, the traditional 3D-Unet is a serial mode and the temporal layers follow the spatial layers, which will result in high GPU memory and training time consumption according to its serial feature flow. We believe that this serial mode will bring more training costs with the large diffusion model and massive datasets, which are not environmentally friendly and not suitable for the development of the T2V. Therefore, we propose a highly efficient spatial-temporal parallel training paradigm for T2V tasks, named Mobius. In our 3D-Unet, the temporal layers and spatial layers are parallel, which optimizes the feature flow and backpropagation. The Mobius will save 24% GPU memory and 12% training time, which can greatly improve the T2V fine-tuning task and provide a novel insight for the AIGC community. We will release our codes in the future.