 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobius: An High Efficient Spatial-Temporal Parallel Training Paradigm for Text-to-Video Generation Task
Paper and Code
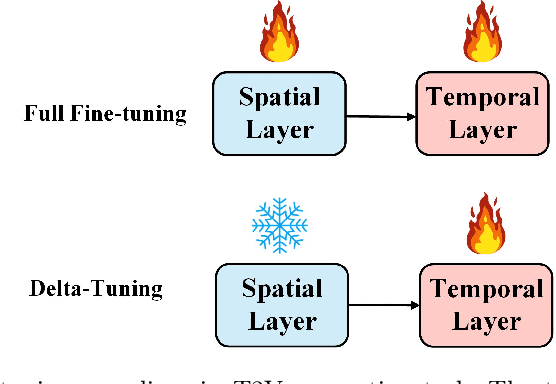
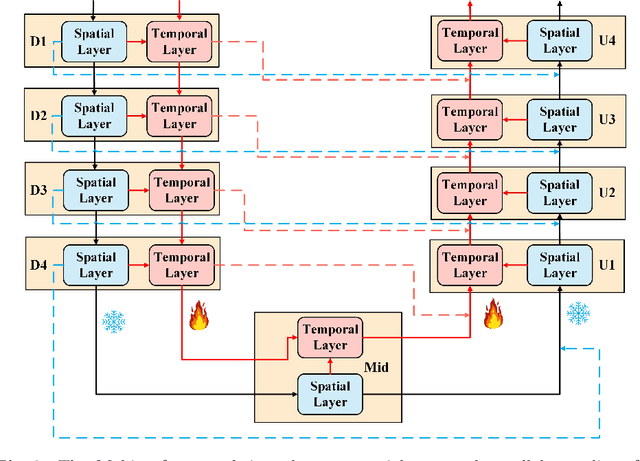

Inspired by the success of the text-to-image (T2I) generation task, many researchers are devoting themselves to the text-to-video (T2V) generation task. Most of the T2V frameworks usually inherit from the T2I model and add extra-temporal layers of training to generate dynamic videos, which can be viewed as a fine-tuning task. However, the traditional 3D-Unet is a serial mode and the temporal layers follow the spatial layers, which will result in high GPU memory and training time consumption according to its serial feature flow. We believe that this serial mode will bring more training costs with the large diffusion model and massive datasets, which are not environmentally friendly and not suitable for the development of the T2V. Therefore, we propose a highly efficient spatial-temporal parallel training paradigm for T2V tasks, named Mobius. In our 3D-Unet, the temporal layers and spatial layers are parallel, which optimizes the feature flow and backpropagation. The Mobius will save 24% GPU memory and 12% training time, which can greatly improve the T2V fine-tuning task and provide a novel insight for the AIGC community. We will release our codes in the future.