 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleDecoupler: Generalizable Artistic Style Disentanglement
Jan 25, 2026Representing artistic style is challenging due to its deep entanglement with semantic content. We propose StyleDecoupler, an information-theoretic framework that leverages a key insight: multi-modal vision models encode both style and content, while uni-modal models suppress style to focus on content-invariant features. By using uni-modal representations as content-only references, we isolate pure style features from multi-modal embeddings through mutual information minimization. StyleDecoupler operates as a plug-and-play module on frozen Vision-Language Models without fine-tuning. We also introduce WeART, a large-scale benchmark of 280K artworks across 152 styles and 1,556 artists. Experiments show state-of-the-art performance on style retrieval across WeART and WikiART, while enabling applications like style relationship mapping and generative model evaluation. We release our method and dataset at this url.
F2RVLM: Boosting Fine-grained Fragment Retrieval for Multi-Modal Long-form Dialogue with Vision Language Model
Aug 25, 2025Traditional dialogue retrieval aims to select the most appropriate utterance or image from recent dialogue history. However, they often fail to meet users' actual needs for revisiting semantically coherent content scattered across long-form conversations. To fill this gap, we define the Fine-grained Fragment Retrieval (FFR) task, requiring models to locate query-relevant fragments, comprising both utterances and images, from multimodal long-form dialogues. As a foundation for FFR, we construct MLDR, the longest-turn multimodal dialogue retrieval dataset to date, averaging 25.45 turns per dialogue, with each naturally spanning three distinct topics. To evaluate generalization in real-world scenarios, we curate and annotate a WeChat-based test set comprising real-world multimodal dialogues with an average of 75.38 turns. Building on these resources, we explore existing generation-based Vision-Language Models (VLMs) on FFR and observe that they often retrieve incoherent utterance-image fragments. While optimized for generating responses from visual-textual inputs, these models lack explicit supervision to ensure semantic coherence within retrieved fragments. To this end, we propose F2RVLM, a generative retrieval model trained in a two-stage paradigm: (1) supervised fine-tuning to inject fragment-level retrieval knowledge, and (2) GRPO-based reinforcement learning with multi-objective rewards promoting semantic precision, relevance, and contextual coherence. To handle varying intra-fragment complexity, from locally dense to sparsely distributed, we introduce difficulty-aware curriculum sampling that ranks training instances by model-predicted difficulty and gradually exposes the model to harder samples. This boosts reasoning ability in long, multi-turn contexts. F2RVLM outperforms popular VLMs in both in-domain and real-domain settings, demonstrating superior retrieval performance.
Enhancing Visual Reliance in Text Generation: A Bayesian Perspective on Mitigating Hallucination in Large Vision-Language Models
May 26, 2025Large Vision-Language Models (LVLMs) usually generate texts which satisfy context coherence but don't match the visual input. Such a hallucination issue hinders LVLMs' applicability in the real world. The key to solving hallucination in LVLM is to make the text generation rely more on the visual content. Most previous works choose to enhance/adjust the features/output of a specific modality (i.e., visual or textual) to alleviate hallucinations in LVLM, which do not explicitly or systematically enhance the visual reliance. In this paper, we comprehensively investigate the factors which may degenerate the visual reliance in text generation of LVLM from a Bayesian perspective. Based on our observations, we propose to mitigate hallucination in LVLM from three aspects. Firstly, we observe that not all visual tokens are informative in generating meaningful texts. We propose to evaluate and remove redundant visual tokens to avoid their disturbance. Secondly, LVLM may encode inappropriate prior information, making it lean toward generating unexpected words. We propose a simple yet effective way to rectify the prior from a Bayesian perspective. Thirdly, we observe that starting from certain steps, the posterior of next-token prediction conditioned on visual tokens may collapse to a prior distribution which does not depend on any informative visual tokens at all. Thus, we propose to stop further text generation to avoid hallucination. Extensive experiments on three benchmarks including POPE, CHAIR, and MME demonstrate that our method can consistently mitigate the hallucination issue of LVLM and performs favorably against previous state-of-the-arts.
Can Large Language Models Help Multimodal Language Analysis? MMLA: A Comprehensive Benchmark
Apr 24, 2025Multimodal language analysis is a rapidly evolving field that leverages multiple modalities to enhance the understanding of high-level semantics underlying human conversational utterances. Despite its significance, little research has investigated the capability of multimodal large language models (MLLMs) to comprehend cognitive-level semantics. In this paper, we introduce MMLA, a comprehensive benchmark specifically designed to address this gap. MMLA comprises over 61K multimodal utterances drawn from both staged and real-world scenarios, covering six core dimensions of multimodal semantics: intent, emotion, dialogue act, sentiment, speaking style, and communication behavior. We evaluate eight mainstream branches of LLMs and MLLMs using three methods: zero-shot inference, supervised fine-tuning, and instruction tuning. Extensive experiments reveal that even fine-tuned models achieve only about 60%~70% accuracy, underscoring the limitations of current MLLMs in understanding complex human language. We believe that MMLA will serve as a solid foundation for exploring the potential of large language models in multimodal language analysis and provide valuable resources to advance this field. The datasets and code are open-sourced at https://github.com/thuiar/MMLA.
Exploiting Prefix-Tree in Structured Output Interfaces for Enhancing Jailbreak Attacking
Feb 19, 2025The rise of Large Language Models (LLMs) has led to significant applications but also introduced serious security threats, particularly from jailbreak attacks that manipulate output generation. These attacks utilize prompt engineering and logit manipulation to steer models toward harmful content, prompting LLM providers to implement filtering and safety alignment strategies. We investigate LLMs' safety mechanisms and their recent applications, revealing a new threat model targeting structured output interfaces, which enable attackers to manipulate the inner logit during LLM generation, requiring only API access permissions. To demonstrate this threat model, we introduce a black-box attack framework called AttackPrefixTree (APT). APT exploits structured output interfaces to dynamically construct attack patterns. By leveraging prefixes of models' safety refusal response and latent harmful outputs, APT effectively bypasses safety measures. Experiments on benchmark datasets indicate that this approach achieves higher attack success rate than existing methods. This work highlights the urgent need for LLM providers to enhance security protocols to address vulnerabilities arising from the interaction between safety patterns and structured outputs.
Control-CLIP: Decoupling Category and Style Guidance in CLIP for Specific-Domain Generation
Feb 17, 2025Text-to-image diffusion models have shown remarkable capabilities of generating high-quality images closely aligned with textual inputs. However, the effectiveness of text guidance heavily relies on the CLIP text encoder, which is trained to pay more attention to general content but struggles to capture semantics in specific domains like styles. As a result, generation models tend to fail on prompts like "a photo of a cat in Pokemon style" in terms of simply producing images depicting "a photo of a cat". To fill this gap, we propose Control-CLIP, a novel decoupled CLIP fine-tuning framework that enables the CLIP model to learn the meaning of category and style in a complement manner. With specially designed fine-tuning tasks on minimal data and a modified cross-attention mechanism, Control-CLIP can precisely guide the diffusion model to a specific domain. Moreover, the parameters of the diffusion model remain unchanged at all, preserving the original generation performance and diversity. Experiments across multiple domains confirm the effectiveness of our approach, particularly highlighting its robust plug-and-play capability in generating content with various specific styles.
Semantic to Structure: Learning Structural Representations for Infringement Detection
Feb 11, 2025Structural information in images is crucial for aesthetic assessment, and it is widely recognized in the artistic field that imitating the structure of other works significantly infringes on creators' rights. The advancement of diffusion models has led to AI-generated content imitating artists' structural creations, yet effective detection methods are still lacking. In this paper, we define this phenomenon as "structural infringement" and propose a corresponding detection method. Additionally, we develop quantitative metrics and create manually annotated datasets for evaluation: the SIA dataset of synthesized data, and the SIR dataset of real data. Due to the current lack of datasets for structural infringement detection, we propose a new data synthesis strategy based on diffusion models and LLM, successfully training a structural infringement detection model. Experimental results show that our method can successfully detect structural infringements and achieve notable improvements on annotated test sets.
WalkVLM:Aid Visually Impaired People Walking by Vision Language Model
Dec 30, 2024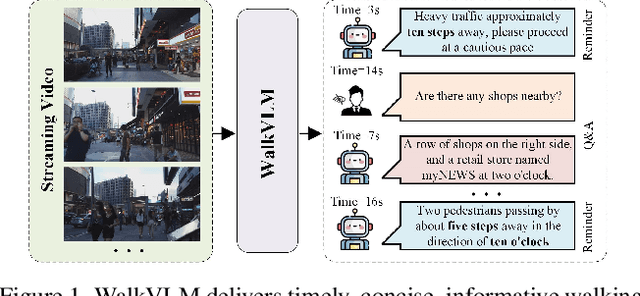



Approximately 200 million individuals around the world suffer from varying degrees of visual impairment, making it crucial to leverage AI technology to offer walking assistance for these people. With the recent progress of vision-language models (VLMs), employing VLMs to improve this field has emerged as a popular research topic. However, most existing methods are studied on self-built question-answering datasets, lacking a unified training and testing benchmark for walk guidance. Moreover, in blind walking task, it is necessary to perform real-time streaming video parsing and generate concise yet informative reminders, which poses a great challenge for VLMs that suffer from redundant responses and low inference efficiency. In this paper, we firstly release a diverse, extensive, and unbiased walking awareness dataset, containing 12k video-manual annotation pairs from Europe and Asia to provide a fair training and testing benchmark for blind walking task. Furthermore, a WalkVLM model is proposed, which employs chain of thought for hierarchical planning to generate concise but informative reminders and utilizes temporal-aware adaptive prediction to reduce the temporal redundancy of reminders. Finally, we have established a solid benchmark for blind walking task and verified the advantages of WalkVLM in stream video processing for this task compared to other VLMs. Our dataset and code will be released at anonymous link https://walkvlm2024.github.io.
ILDiff: Generate Transparent Animated Stickers by Implicit Layout Distillation
Dec 30, 2024



High-quality animated stickers usually contain transparent channels, which are often ignored by current video generation models. To generate fine-grained animated transparency channels, existing methods can be roughly divided into video matting algorithms and diffusion-based algorithms. The methods based on video matting have poor performance in dealing with semi-open areas in stickers, while diffusion-based methods are often used to model a single image, which will lead to local flicker when modeling animated stickers. In this paper, we firstly propose an ILDiff method to generate animated transparent channels through implicit layout distillation, which solves the problems of semi-open area collapse and no consideration of temporal information in existing methods. Secondly, we create the Transparent Animated Sticker Dataset (TASD), which contains 0.32M high-quality samples with transparent channel, to provide data support for related fields. Extensive experiments demonstrate that ILDiff can produce finer and smoother transparent channels compared to other methods such as Matting Anything and Layer Diffusion. Our code and dataset will be released at link https://xiaoyuan1996.github.io.
MedDiT: A Knowledge-Controlled Diffusion Transformer Framework for Dynamic Medical Image Generation in Virtual Simulated Patient
Aug 22, 2024Medical education relies heavily on Simulated Patients (SPs) to provide a safe environment for students to practice clinical skills, including medical image analysis. However, the high cost of recruiting qualified SPs and the lack of diverse medical imaging datasets have presented significant challenges. To address these issues, this paper introduces MedDiT, a novel knowledge-controlled conversational framework that can dynamically generate plausible medical images aligned with simulated patient symptoms, enabling diverse diagnostic skill training. Specifically, MedDiT integrates various patient Knowledge Graphs (KGs), which describe the attributes and symptoms of patients, to dynamically prompt Large Language Models' (LLMs) behavior and control the patient characteristics, mitigating hallucination during medical conversation. Additionally, a well-tuned Diffusion Transformer (DiT) model is incorporated to generate medical images according to the specified patient attributes in the KG. In this paper, we present the capabilities of MedDiT through a practical demonstration, showcasing its ability to act in diverse simulated patient cases and generate the corresponding medical images. This can provide an abundant and interactive learning experience for students, advancing medical education by offering an immersive simulation platform for future healthcare professionals. The work sheds light on the feasibility of incorporating advanced technologies like LLM, KG, and DiT in education applications, highlighting their potential to address the challenges faced in simulated patient-based medical education.