 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Multi-Reference-Point Modeling Framework for Monostatic Background Channel: Toward 3GPP ISAC Standardization
Nov 05, 2025Integrated Sensing and Communication (ISAC) has been identified as a key 6G application by ITU and 3GPP. A realistic, standard-compatible channel model is essential for ISAC system design. To characterize the impact of Sensing Targets (STs), 3GPP defines ISAC channel as a combination of target and background channels, comprising multipath components related to STs and those originating solely from the environment, respectively. Although the background channel does not carry direct ST information, its accurate modeling is critical for evaluating sensing performance, especially in complex environments. Existing communication standards characterize propagation between separated transmitter (Tx) and receiver (Rx). However, modeling background channels in the ISAC monostatic mode, where the Tx and Rx are co-located, remains a pressing challenge. In this paper, we firstly conduct ISAC monostatic background channel measurements for an indoor scenario at 28 GHz. Realistic channel parameters are extracted, revealing pronounced single-hop propagation and discrete multipath distribution. Inspired by these properties, a novel stochastic model is proposed to characterizing the ISAC monostatic background channel as the superposition of sub-channels between the monostatic Tx&Rx and multiple communication Rx-like Reference Points (RPs). This model is compatible with standardizations, and a 3GPP-extended implementation framework is introduced. Finally, a genetic algorithm-based method is proposed to extract the optimal number and placement of multi-RPs. The optimization approach and modeling framework are validated by comparing measured and simulated channel parameters. Results demonstrate that the proposed model effectively captures monostatic background channel characteristics, addresses a critical gap in ISAC channel modeling, and supports 6G standardization.
F2RVLM: Boosting Fine-grained Fragment Retrieval for Multi-Modal Long-form Dialogue with Vision Language Model
Aug 25, 2025Traditional dialogue retrieval aims to select the most appropriate utterance or image from recent dialogue history. However, they often fail to meet users' actual needs for revisiting semantically coherent content scattered across long-form conversations. To fill this gap, we define the Fine-grained Fragment Retrieval (FFR) task, requiring models to locate query-relevant fragments, comprising both utterances and images, from multimodal long-form dialogues. As a foundation for FFR, we construct MLDR, the longest-turn multimodal dialogue retrieval dataset to date, averaging 25.45 turns per dialogue, with each naturally spanning three distinct topics. To evaluate generalization in real-world scenarios, we curate and annotate a WeChat-based test set comprising real-world multimodal dialogues with an average of 75.38 turns. Building on these resources, we explore existing generation-based Vision-Language Models (VLMs) on FFR and observe that they often retrieve incoherent utterance-image fragments. While optimized for generating responses from visual-textual inputs, these models lack explicit supervision to ensure semantic coherence within retrieved fragments. To this end, we propose F2RVLM, a generative retrieval model trained in a two-stage paradigm: (1) supervised fine-tuning to inject fragment-level retrieval knowledge, and (2) GRPO-based reinforcement learning with multi-objective rewards promoting semantic precision, relevance, and contextual coherence. To handle varying intra-fragment complexity, from locally dense to sparsely distributed, we introduce difficulty-aware curriculum sampling that ranks training instances by model-predicted difficulty and gradually exposes the model to harder samples. This boosts reasoning ability in long, multi-turn contexts. F2RVLM outperforms popular VLMs in both in-domain and real-domain settings, demonstrating superior retrieval performance.
A Unified Deterministic Channel Model for Multi-Type RIS with Reflective, Transmissive, and Polarization Operations
May 12, 2025Reconfigurable Intelligent Surface (RIS) technologies have been considered as a promising enabler for 6G, enabling advantageous control of electromagnetic (EM) propagation. RIS can be categorized into multiple types based on their reflective/transmissive modes and polarization control capabilities, all of which are expected to be widely deployed in practical environments. A reliable RIS channel model is essential for the design and development of RIS communication systems. While deterministic modeling approaches such as ray-tracing (RT) offer significant benefits, a unified model that accommodates all RIS types is still lacking. This paper addresses this gap by developing a high-precision deterministic channel model based on RT, supporting multiple RIS types: reflective, transmissive, hybrid, and three polarization operation modes. To achieve this, a unified EM response model for the aforementioned RIS types is developed. The reflection and transmission coefficients of RIS elements are derived using a tensor-based equivalent impedance approach, followed by calculating the scattered fields of the RIS to establish an EM response model. The performance of different RIS types is compared through simulations in typical scenarios. During this process, passive and lossless constraints on the reflection and transmission coefficients are incorporated to ensure fairness in the performance evaluation. Simulation results validate the framework's accuracy in characterizing the RIS channel, and specific cases tailored for dual-polarization independent control and polarization rotating RISs are highlighted as insights for their future deployment. This work can be helpful for the evaluation and optimization of RIS-enabled wireless communication systems.
Control-CLIP: Decoupling Category and Style Guidance in CLIP for Specific-Domain Generation
Feb 17, 2025Text-to-image diffusion models have shown remarkable capabilities of generating high-quality images closely aligned with textual inputs. However, the effectiveness of text guidance heavily relies on the CLIP text encoder, which is trained to pay more attention to general content but struggles to capture semantics in specific domains like styles. As a result, generation models tend to fail on prompts like "a photo of a cat in Pokemon style" in terms of simply producing images depicting "a photo of a cat". To fill this gap, we propose Control-CLIP, a novel decoupled CLIP fine-tuning framework that enables the CLIP model to learn the meaning of category and style in a complement manner. With specially designed fine-tuning tasks on minimal data and a modified cross-attention mechanism, Control-CLIP can precisely guide the diffusion model to a specific domain. Moreover, the parameters of the diffusion model remain unchanged at all, preserving the original generation performance and diversity. Experiments across multiple domains confirm the effectiveness of our approach, particularly highlighting its robust plug-and-play capability in generating content with various specific styles.
Semantic to Structure: Learning Structural Representations for Infringement Detection
Feb 11, 2025Structural information in images is crucial for aesthetic assessment, and it is widely recognized in the artistic field that imitating the structure of other works significantly infringes on creators' rights. The advancement of diffusion models has led to AI-generated content imitating artists' structural creations, yet effective detection methods are still lacking. In this paper, we define this phenomenon as "structural infringement" and propose a corresponding detection method. Additionally, we develop quantitative metrics and create manually annotated datasets for evaluation: the SIA dataset of synthesized data, and the SIR dataset of real data. Due to the current lack of datasets for structural infringement detection, we propose a new data synthesis strategy based on diffusion models and LLM, successfully training a structural infringement detection model. Experimental results show that our method can successfully detect structural infringements and achieve notable improvements on annotated test sets.
Channel Sounding Using Multiplicative Arrays Based on Successive Interference Cancellation Principle
Jan 19, 2025



Ultra-massive multiple-input and multiple-output (MIMO) systems have been seen as the key radio technology for the advancement of wireless communication systems, due to its capability to better utilize the spatial dimension of the propagation channels. Channel sounding is essential for developing accurate and realistic channel models for the massive MIMO systems. However, channel sounding with large-scale antenna systems has faced significant challenges in practice. The real antenna array based (RAA) sounder suffers from high complexity and cost, while virtual antenna array (VAA) solutions are known for its long measurement time. Notably, these issues will become more pronounced as the antenna array configuration gets larger for future radio systems. In this paper, we propose the concept of multiplicative array (MA) for channel sounding applications to achieve large antenna aperture size with reduced number of required antenna elements. The unique characteristics of the MA are exploited for wideband spatial channel sounding purposes, supported by both one-path and multi-path numerical simulations. To address the fake paths and distortion in the angle delay profile issues inherent for MA in multipath channel sounding, a novel channel parameter estimation algorithm for MA based on successive interference cancellation (SIC) principle is proposed. Both numerical simulations and experimental validation results are provided to demonstrate the effectiveness and robustness of the proposed SIC algorithm for the MA. This research contributes significantly to the channel sounding and characterization of massive MIMO systems for future applications.
ILDiff: Generate Transparent Animated Stickers by Implicit Layout Distillation
Dec 30, 2024



High-quality animated stickers usually contain transparent channels, which are often ignored by current video generation models. To generate fine-grained animated transparency channels, existing methods can be roughly divided into video matting algorithms and diffusion-based algorithms. The methods based on video matting have poor performance in dealing with semi-open areas in stickers, while diffusion-based methods are often used to model a single image, which will lead to local flicker when modeling animated stickers. In this paper, we firstly propose an ILDiff method to generate animated transparent channels through implicit layout distillation, which solves the problems of semi-open area collapse and no consideration of temporal information in existing methods. Secondly, we create the Transparent Animated Sticker Dataset (TASD), which contains 0.32M high-quality samples with transparent channel, to provide data support for related fields. Extensive experiments demonstrate that ILDiff can produce finer and smoother transparent channels compared to other methods such as Matting Anything and Layer Diffusion. Our code and dataset will be released at link https://xiaoyuan1996.github.io.
WalkVLM:Aid Visually Impaired People Walking by Vision Language Model
Dec 30, 2024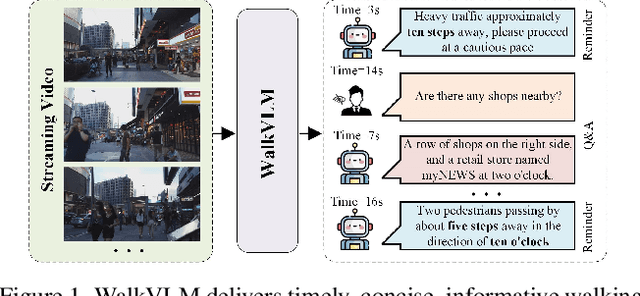



Approximately 200 million individuals around the world suffer from varying degrees of visual impairment, making it crucial to leverage AI technology to offer walking assistance for these people. With the recent progress of vision-language models (VLMs), employing VLMs to improve this field has emerged as a popular research topic. However, most existing methods are studied on self-built question-answering datasets, lacking a unified training and testing benchmark for walk guidance. Moreover, in blind walking task, it is necessary to perform real-time streaming video parsing and generate concise yet informative reminders, which poses a great challenge for VLMs that suffer from redundant responses and low inference efficiency. In this paper, we firstly release a diverse, extensive, and unbiased walking awareness dataset, containing 12k video-manual annotation pairs from Europe and Asia to provide a fair training and testing benchmark for blind walking task. Furthermore, a WalkVLM model is proposed, which employs chain of thought for hierarchical planning to generate concise but informative reminders and utilizes temporal-aware adaptive prediction to reduce the temporal redundancy of reminders. Finally, we have established a solid benchmark for blind walking task and verified the advantages of WalkVLM in stream video processing for this task compared to other VLMs. Our dataset and code will be released at anonymous link https://walkvlm2024.github.io.
TRANSAGENT: An LLM-Based Multi-Agent System for Code Translation
Sep 30, 2024Code translation converts code from one programming language to another while maintaining its original functionality, which is crucial for software migration, system refactoring, and cross-platform development. Traditional rule-based methods rely on manually-written rules, which can be time-consuming and often result in less readable code. To overcome this, learning-based methods have been developed, leveraging parallel data to train models for automated code translation. More recently, the advance of Large Language Models (LLMs) further boosts learning-based code translation. Although promising, LLM-translated program still suffers from diverse quality issues (e.g., syntax errors and semantic errors). In particular, it can be challenging for LLMs to self-debug these errors when simply provided with the corresponding error messages. In this work, we propose a novel LLM-based multi-agent system TRANSAGENT, which enhances LLM-based code translation by fixing the syntax errors and semantic errors with the synergy between four LLM-based agents, including Initial Code Translator, Syntax Error Fixer, Code Aligner, and Semantic Error Fixer. The main insight of TRANSAGENT is to first localize the error code block in the target program based on the execution alignment between the target and source program, which can narrow down the fixing space and thus lower down the fixing difficulties. To evaluate TRANSAGENT, we first construct a new benchmark from recent programming tasks to mitigate the potential data leakage issue. On our benchmark, TRANSAGENT outperforms the latest LLM-based code translation technique UniTrans in both translation effectiveness and efficiency; additionally, our evaluation on different LLMs show the generalization of TRANSAGENT and our ablation study shows the contribution of each agent.
Near-Field Channel Characterization for Mid-band ELAA Systems: Sounding, Parameter Estimation, and Modeling
May 10, 2024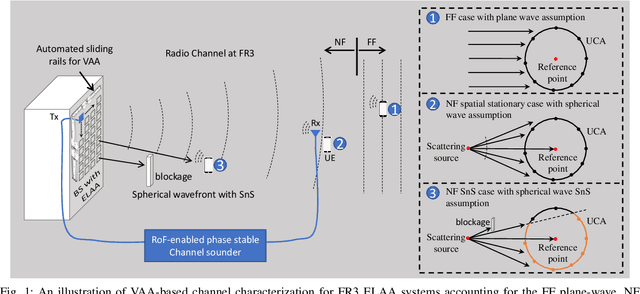
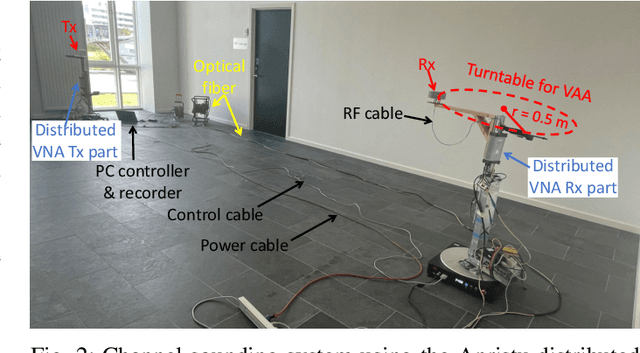
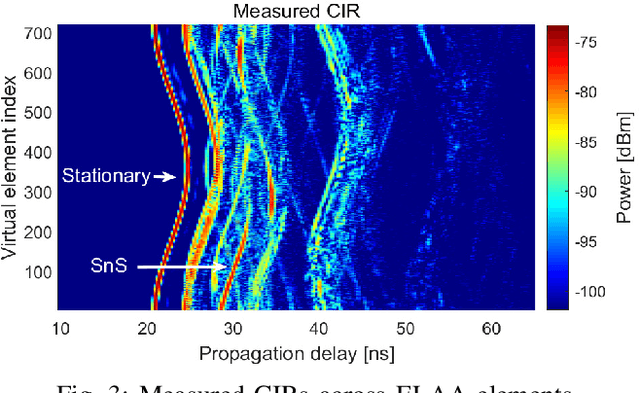
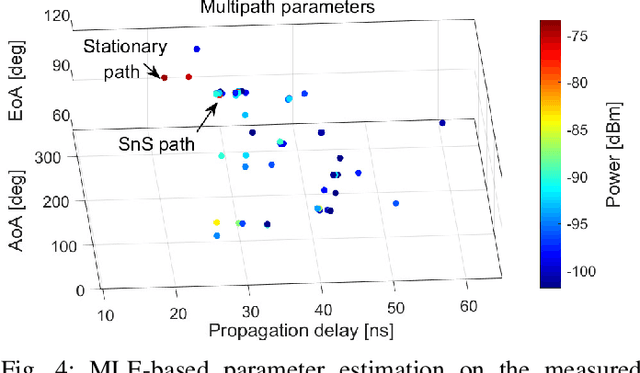
6G communication will greatly benefit from using extremely large-scale antenna arrays (ELAAs) and new mid-band spectrums (7-24 GHz). These techniques require a thorough exploration of the challenges and potentials of the associated near-field (NF) phenomena. It is crucial to develop accurate NF channel models that include spherical wave propagation and spatial non-stationarity (SnS). However, channel measurement campaigns for mid-band ELAA systems have rarely been reported in the state-of-the-art. To this end, this work develops a channel sounder dedicated to mid-band ELAA systems based on a distributed modular vector network analyzer incorporating radio-over-fiber (RoF), phase compensation, and virtual antenna array schemes. This novel channel-sounding testbed based on off-the-shelf VNA has the potential to enable large-scale experimentation due to its generic and easy-accessible nature. The main challenges and solutions for developing NF channel models for mid-band ELAA systems are discussed, including channel sounders, multipath parameter estimation algorithms, and channel modeling frameworks. Besides, the study reports a measurement campaign in an indoor scenario using a 720-element virtual uniform circular array ELAA operating at {16-20} GHz, highlighting the presence of spherical wavefronts and spatial non-stationary effects. The effectiveness of the proposed near-field channel parameter estimator and channel modeling framework is also demonstrated using the measurement data.