 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Legendre Memory Unit with A Multi-Slice Compensation Model for Short-Term Wind Speed Forecasting Based on Wind Farm Cluster Data
Feb 04, 2026With more wind farms clustered for integration, the short-term wind speed prediction of such wind farm clusters is critical for normal operation of power systems. This paper focuses on achieving accurate, fast, and robust wind speed prediction by full use of cluster data with spatial-temporal correlation. First, weighted mean filtering (WMF) is applied to denoise wind speed data at the single-farm level. The Legendre memory unit (LMU) is then innovatively applied for the wind speed prediction, in combination with the Compensating Parameter based on Kendall rank correlation coefficient (CPK) of wind farm cluster data, to construct the multi-slice LMU (MSLMU). Finally, an innovative ensemble model WMF-CPK-MSLMU is proposed herein, with three key blocks: data pre-processing, forecasting, and multi-slice compensation. Advantages include: 1) LMU jointly models linear and nonlinear dependencies among farms to capture spatial-temporal correlations through backpropagation; 2) MSLMU enhances forecasting by using CPK-derived weights instead of random initialization, allowing spatial correlations to fully activate hidden nodes across clustered wind farms.; 3) CPK adaptively weights the compensation model in MSLMU and complements missing data spatially, to facilitate the whole model highly accurate and robust. Test results on different wind farm clusters indicate the effectiveness and superiority of proposed ensemble model WMF-CPK-MSLMU in the short-term prediction of wind farm clusters compared to the existing models.
Autoregressive, Yet Revisable: In Decoding Revision for Secure Code Generation
Feb 01, 2026Large Language Model (LLM) based code generation is predominantly formulated as a strictly monotonic process, appending tokens linearly to an immutable prefix. This formulation contrasts to the cognitive process of programming, which is inherently interleaved with forward generation and on-the-fly revision. While prior works attempt to introduce revision via post-hoc agents or external static tools, they either suffer from high latency or fail to leverage the model's intrinsic semantic reasoning. In this paper, we propose Stream of Revision, a paradigm shift that elevates code generation from a monotonic stream to a dynamic, self-correcting trajectory by leveraging model's intrinsic capabilities. We introduce specific action tokens that enable the model to seamlessly backtrack and edit its own history within a single forward pass. By internalizing the revision loop, our framework Stream of Revision allows the model to activate its latent capabilities just-in-time without external dependencies. Empirical results on secure code generation show that Stream of Revision significantly reduces vulnerabilities with minimal inference overhead.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
GeoLoom: High-quality Geometric Diagram Generation from Textual Input
Dec 09, 2025High-quality geometric diagram generation presents both a challenge and an opportunity: it demands strict spatial accuracy while offering well-defined constraints to guide generation. Inspired by recent advances in geometry problem solving that employ formal languages and symbolic solvers for enhanced correctness and interpretability, we propose GeoLoom, a novel framework for text-to-diagram generation in geometric domains. GeoLoom comprises two core components: an autoformalization module that translates natural language into a specifically designed generation-oriented formal language GeoLingua, and a coordinate solver that maps formal constraints to precise coordinates using the efficient Monte Carlo optimization. To support this framework, we introduce GeoNF, a dataset aligning natural language geometric descriptions with formal GeoLingua descriptions. We further propose a constraint-based evaluation metric that quantifies structural deviation, offering mathematically grounded supervision for iterative refinement. Empirical results demonstrate that GeoLoom significantly outperforms state-of-the-art baselines in structural fidelity, providing a principled foundation for interpretable and scalable diagram generation.
SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
Sep 26, 2025Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
PromptAL: Sample-Aware Dynamic Soft Prompts for Few-Shot Active Learning
Jul 22, 2025Active learning (AL) aims to optimize model training and reduce annotation costs by selecting the most informative samples for labeling. Typically, AL methods rely on the empirical distribution of labeled data to define the decision boundary and perform uncertainty or diversity estimation, subsequently identifying potential high-quality samples. In few-shot scenarios, the empirical distribution often diverges significantly from the target distribution, causing the decision boundary to shift away from its optimal position. However, existing methods overlook the role of unlabeled samples in enhancing the empirical distribution to better align with the target distribution, resulting in a suboptimal decision boundary and the selection of samples that inadequately represent the target distribution. To address this, we propose a hybrid AL framework, termed \textbf{PromptAL} (Sample-Aware Dynamic Soft \textbf{Prompts} for Few-Shot \textbf{A}ctive \textbf{L}earning). This framework accounts for the contribution of each unlabeled data point in aligning the current empirical distribution with the target distribution, thereby optimizing the decision boundary. Specifically, PromptAL first leverages unlabeled data to construct sample-aware dynamic soft prompts that adjust the model's predictive distribution and decision boundary. Subsequently, based on the adjusted decision boundary, it integrates uncertainty estimation with both global and local diversity to select high-quality samples that more accurately represent the target distribution. Experimental results on six in-domain and three out-of-domain datasets show that PromptAL achieves superior performance over nine baselines. Our codebase is openly accessible.
VisioMath: Benchmarking Figure-based Mathematical Reasoning in LMMs
Jun 07, 2025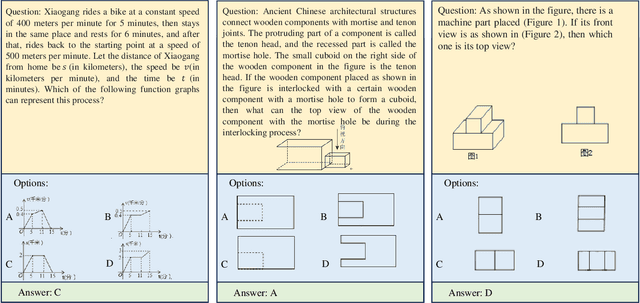
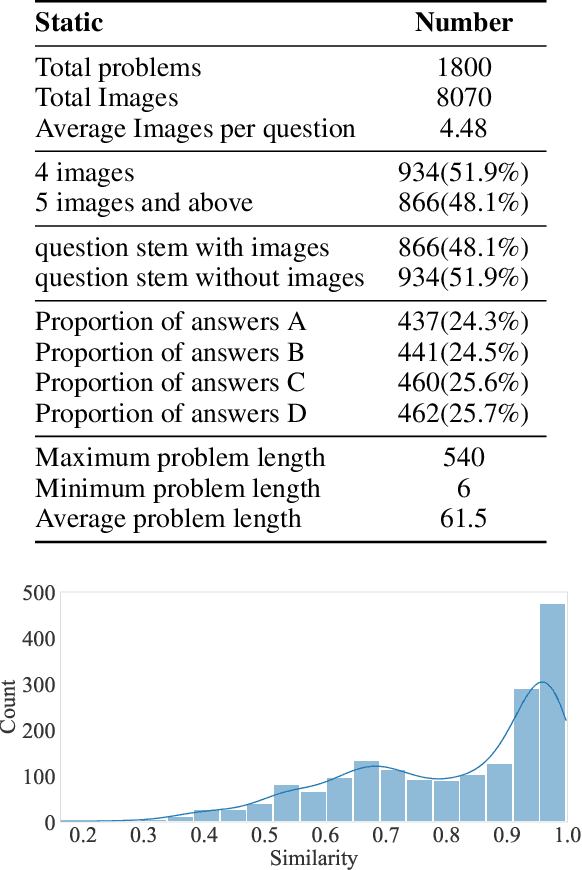
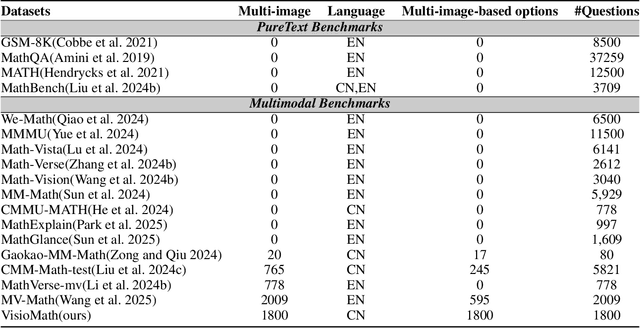
Large Multimodal Models (LMMs) have demonstrated remarkable problem-solving capabilities across various domains. However, their ability to perform mathematical reasoning when answer options are represented as images--an essential aspect of multi-image comprehension--remains underexplored. To bridge this gap, we introduce VisioMath, a benchmark designed to evaluate mathematical reasoning in multimodal contexts involving image-based answer choices. VisioMath comprises 8,070 images and 1,800 multiple-choice questions, where each answer option is an image, presenting unique challenges to existing LMMs. To the best of our knowledge, VisioMath is the first dataset specifically tailored for mathematical reasoning in image-based-option scenarios, where fine-grained distinctions between answer choices are critical for accurate problem-solving. We systematically evaluate state-of-the-art LMMs on VisioMath and find that even the most advanced models struggle with this task. Notably, GPT-4o achieves only 45.9% accuracy, underscoring the limitations of current models in reasoning over visually similar answer choices. By addressing a crucial gap in existing benchmarks, VisioMath establishes a rigorous testbed for future research, driving advancements in multimodal reasoning.
An LLM-as-Judge Metric for Bridging the Gap with Human Evaluation in SE Tasks
May 27, 2025



Large Language Models (LLMs) and other automated techniques have been increasingly used to support software developers by generating software artifacts such as code snippets, patches, and comments. However, accurately assessing the correctness of these generated artifacts remains a significant challenge. On one hand, human evaluation provides high accuracy but is labor-intensive and lacks scalability. On the other hand, other existing automatic evaluation metrics are scalable and require minimal human effort, but they often fail to accurately reflect the actual correctness of generated software artifacts. In this paper, we present SWE-Judge, the first evaluation metric for LLM-as-Ensemble-Judge specifically designed to accurately assess the correctness of generated software artifacts. SWE-Judge first defines five distinct evaluation strategies, each implemented as an independent judge. A dynamic team selection mechanism then identifies the most appropriate subset of judges to produce a final correctness score through ensembling. We evaluate SWE-Judge across a diverse set of software engineering (SE) benchmarks, including CoNaLa, Card2Code, HumanEval-X, APPS, APR-Assess, and Summary-Assess. These benchmarks span three SE tasks: code generation, automated program repair, and code summarization. Experimental results demonstrate that SWE-Judge consistently achieves a higher correlation with human judgments, with improvements ranging from 5.9% to 183.8% over existing automatic metrics. Furthermore, SWE-Judge reaches agreement levels with human annotators that are comparable to inter-annotator agreement in code generation and program repair tasks. These findings underscore SWE-Judge's potential as a scalable and reliable alternative to human evaluation.
SMART: Self-Generating and Self-Validating Multi-Dimensional Assessment for LLMs' Mathematical Problem Solving
May 22, 2025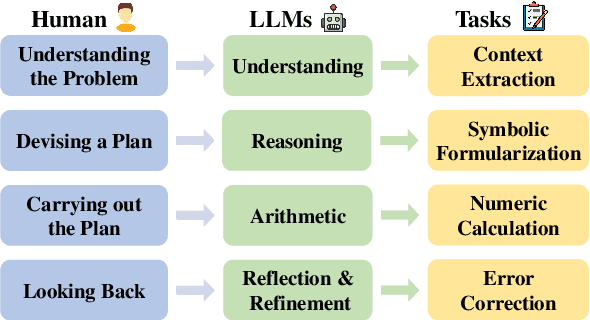
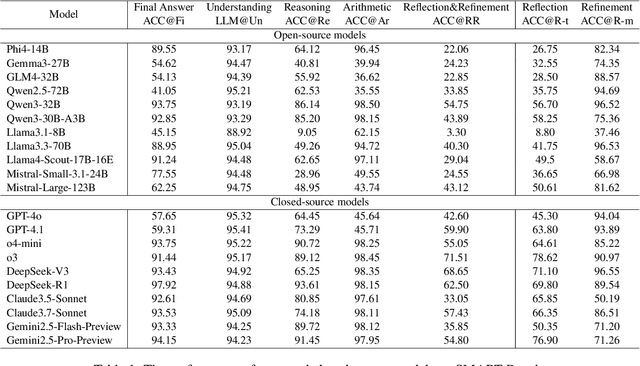

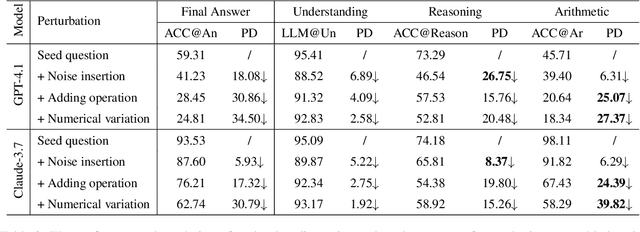
Large Language Models have achieved remarkable results on a variety of mathematical benchmarks. However, concerns remain as to whether these successes reflect genuine mathematical reasoning or superficial pattern recognition. Common evaluation metrics, such as final answer accuracy, fail to disentangle the underlying competencies involved, offering limited diagnostic value. To address these limitations, we introduce SMART: a Self-Generating and Self-Validating Multi-Dimensional Assessment Framework. SMART decomposes mathematical problem solving into four distinct dimensions: understanding, reasoning, arithmetic, and reflection \& refinement. Each dimension is evaluated independently through tailored tasks, enabling interpretable and fine-grained analysis of LLM behavior. Crucially, SMART integrates an automated self-generating and self-validating mechanism to produce and verify benchmark data, ensuring both scalability and reliability. We apply SMART to 21 state-of-the-art open- and closed-source LLMs, uncovering significant discrepancies in their abilities across different dimensions. Our findings demonstrate the inadequacy of final answer accuracy as a sole metric and motivate a new holistic metric to better capture true problem-solving capabilities. Code and benchmarks will be released upon acceptance.