 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess or More: Towards Glanceable Explanations for LLM Recommendations Using Ultra-Small Devices
Feb 26, 2025Large Language Models (LLMs) have shown remarkable potential in recommending everyday actions as personal AI assistants, while Explainable AI (XAI) techniques are being increasingly utilized to help users understand why a recommendation is given. Personal AI assistants today are often located on ultra-small devices such as smartwatches, which have limited screen space. The verbosity of LLM-generated explanations, however, makes it challenging to deliver glanceable LLM explanations on such ultra-small devices. To address this, we explored 1) spatially structuring an LLM's explanation text using defined contextual components during prompting and 2) presenting temporally adaptive explanations to users based on confidence levels. We conducted a user study to understand how these approaches impacted user experiences when interacting with LLM recommendations and explanations on ultra-small devices. The results showed that structured explanations reduced users' time to action and cognitive load when reading an explanation. Always-on structured explanations increased users' acceptance of AI recommendations. However, users were less satisfied with structured explanations compared to unstructured ones due to their lack of sufficient, readable details. Additionally, adaptively presenting structured explanations was less effective at improving user perceptions of the AI compared to the always-on structured explanations. Together with users' interview feedback, the results led to design implications to be mindful of when personalizing the content and timing of LLM explanations that are displayed on ultra-small devices.
Scalable Quantum-Inspired Optimization through Dynamic Qubit Compression
Dec 24, 2024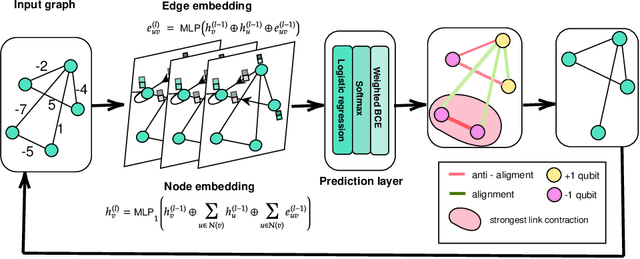
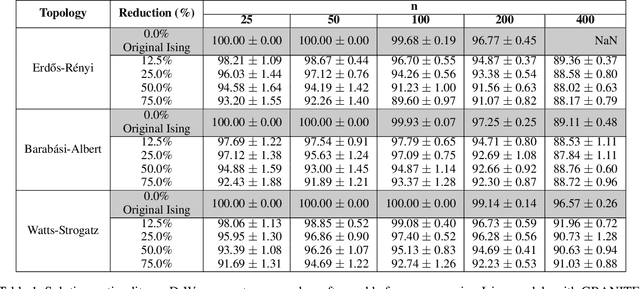
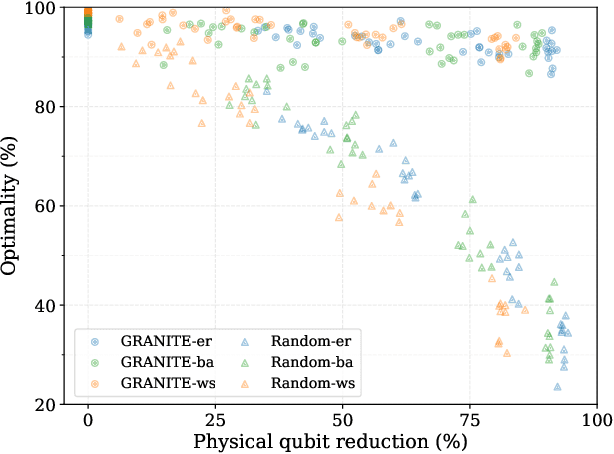
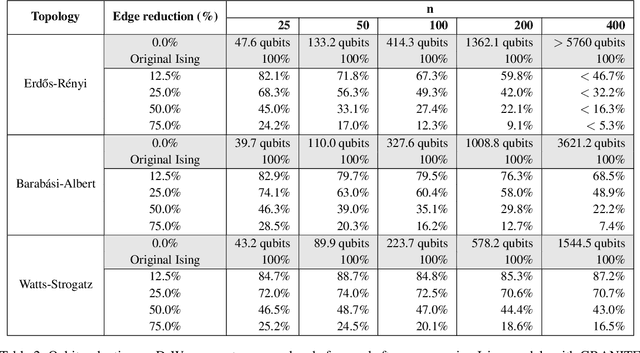
Hard combinatorial optimization problems, often mapped to Ising models, promise potential solutions with quantum advantage but are constrained by limited qubit counts in near-term devices. We present an innovative quantum-inspired framework that dynamically compresses large Ising models to fit available quantum hardware of different sizes. Thus, we aim to bridge the gap between large-scale optimization and current hardware capabilities. Our method leverages a physics-inspired GNN architecture to capture complex interactions in Ising models and accurately predict alignments among neighboring spins (aka qubits) at ground states. By progressively merging such aligned spins, we can reduce the model size while preserving the underlying optimization structure. It also provides a natural trade-off between the solution quality and size reduction, meeting different hardware constraints of quantum computing devices. Extensive numerical studies on Ising instances of diverse topologies show that our method can reduce instance size at multiple levels with virtually no losses in solution quality on the latest D-wave quantum annealers.
Brain Signals to Rescue Aphasia, Apraxia and Dysarthria Speech Recognition
Feb 28, 2021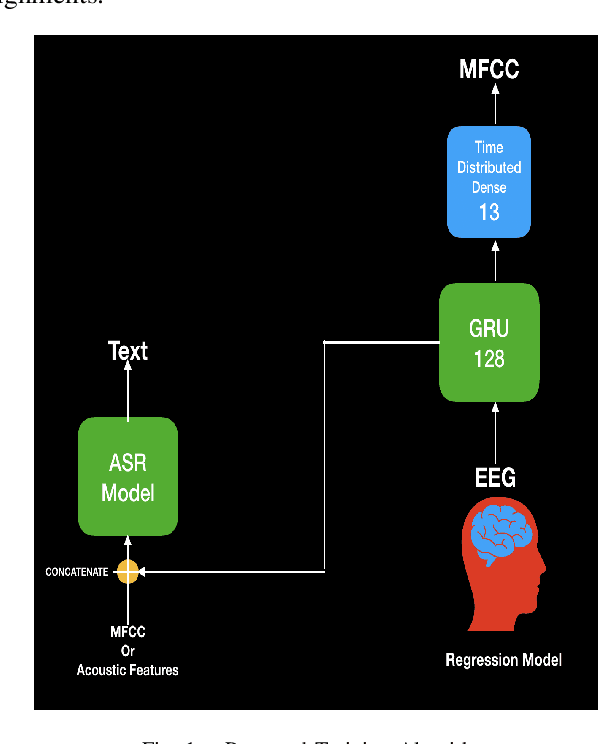
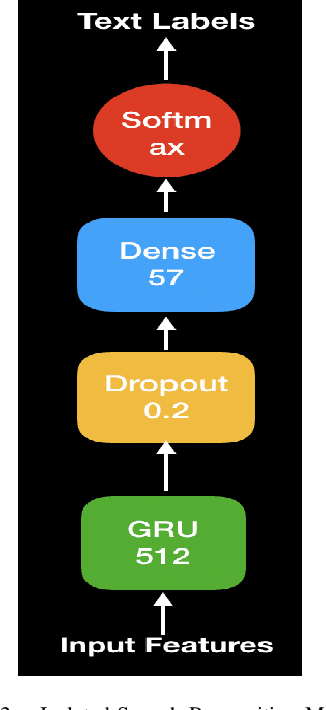
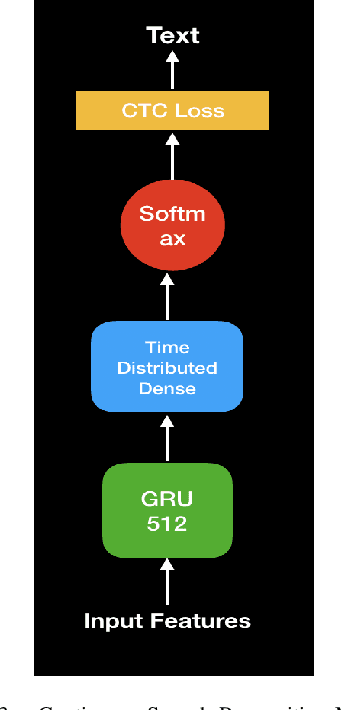
In this paper, we propose a deep learning-based algorithm to improve the performance of automatic speech recognition (ASR) systems for aphasia, apraxia, and dysarthria speech by utilizing electroencephalography (EEG) features recorded synchronously with aphasia, apraxia, and dysarthria speech. We demonstrate a significant decoding performance improvement by more than 50\% during test time for isolated speech recognition task and we also provide preliminary results indicating performance improvement for the more challenging continuous speech recognition task by utilizing EEG features. The results presented in this paper show the first step towards demonstrating the possibility of utilizing non-invasive neural signals to design a real-time robust speech prosthetic for stroke survivors recovering from aphasia, apraxia, and dysarthria. Our aphasia, apraxia, and dysarthria speech-EEG data set will be released to the public to help further advance this interesting and crucial research.
Speech Recognition using EEG signals recorded using dry electrodes
Aug 13, 2020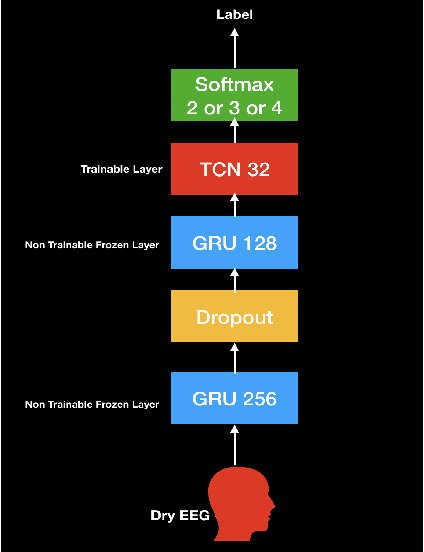
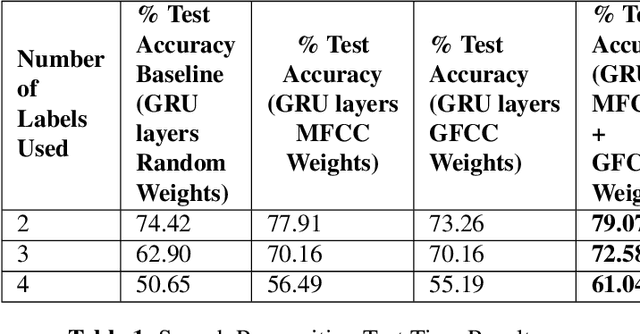
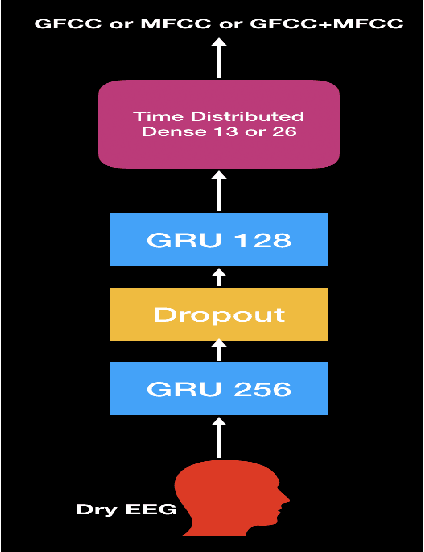
In this paper, we demonstrate speech recognition using electroencephalography (EEG) signals obtained using dry electrodes on a limited English vocabulary consisting of three vowels and one word using a deep learning model. We demonstrate a test accuracy of 79.07 percent on a subset vocabulary consisting of two English vowels. Our results demonstrate the feasibility of using EEG signals recorded using dry electrodes for performing the task of speech recognition.
Constrained Variational Autoencoder for improving EEG based Speech Recognition Systems
Jun 01, 2020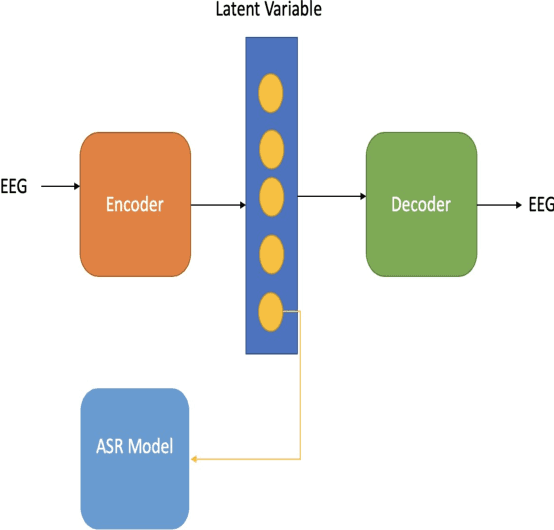

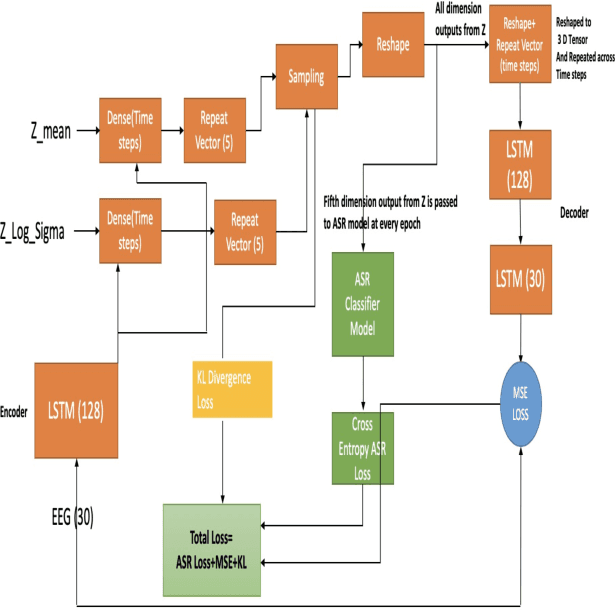
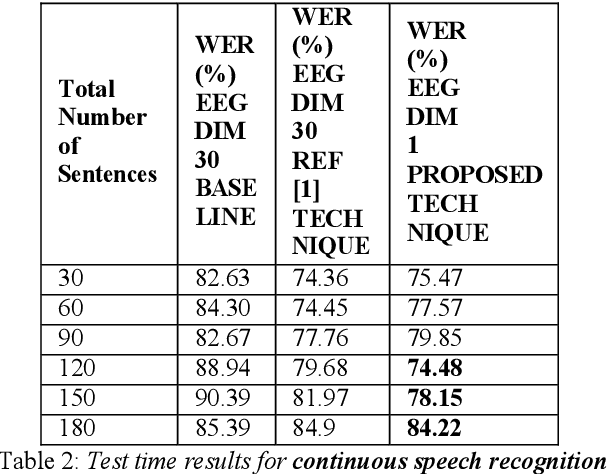
In this paper we introduce a recurrent neural network (RNN) based variational autoencoder (VAE) model with a new constrained loss function that can generate more meaningful electroencephalography (EEG) features from raw EEG features to improve the performance of EEG based speech recognition systems. We demonstrate that both continuous and isolated speech recognition systems trained and tested using EEG features generated from raw EEG features using our VAE model results in improved performance and we demonstrate our results for a limited English vocabulary consisting of 30 unique sentences for continuous speech recognition and for an English vocabulary consisting of 2 unique sentences for isolated speech recognition. We compare our method with another recently introduced method described by authors in [1] to improve the performance of EEG based continuous speech recognition systems and we demonstrate that our method outperforms their method as vocabulary size increases when trained and tested using the same data set. Even though we demonstrate results only for automatic speech recognition (ASR) experiments in this paper, the proposed VAE model with constrained loss function can be extended to a variety of other EEG based brain computer interface (BCI) applications.
Improving EEG based continuous speech recognition using GAN
May 29, 2020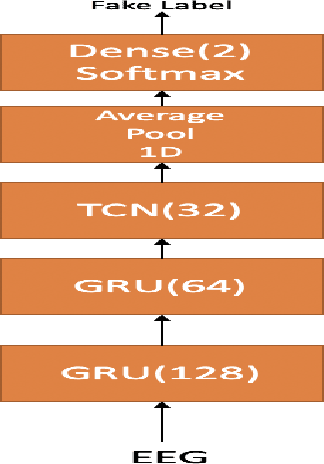
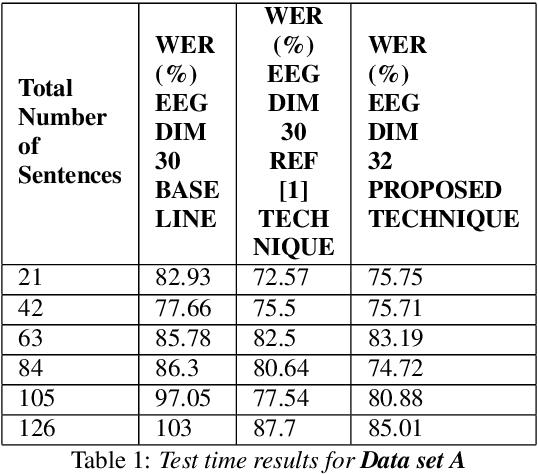
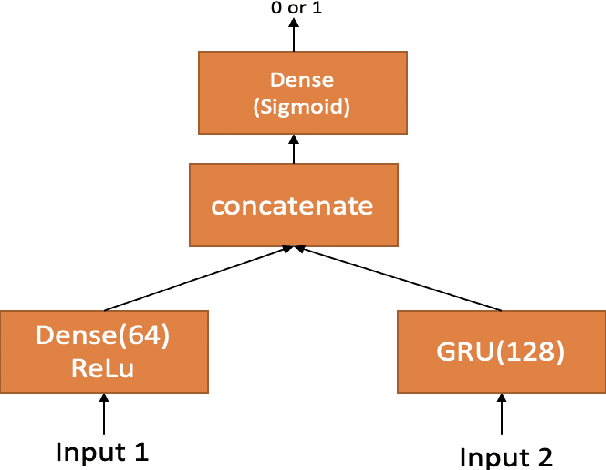
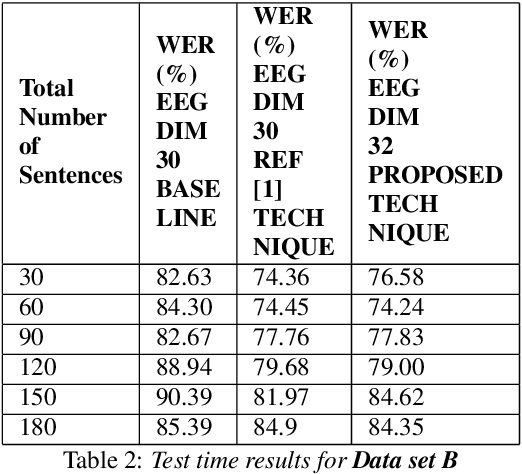
In this paper we demonstrate that it is possible to generate more meaningful electroencephalography (EEG) features from raw EEG features using generative adversarial networks (GAN) to improve the performance of EEG based continuous speech recognition systems. We improve the results demonstrated by authors in [1] using their data sets for for some of the test time experiments and for other cases our results were comparable with theirs. Our proposed approach can be implemented without using any additional sensor information, whereas in [1] authors used additional features like acoustic or articulatory information to improve the performance of EEG based continuous speech recognition systems.
Understanding effect of speech perception in EEG based speech recognition systems
May 29, 2020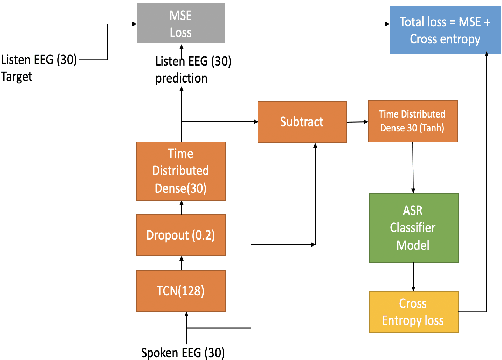
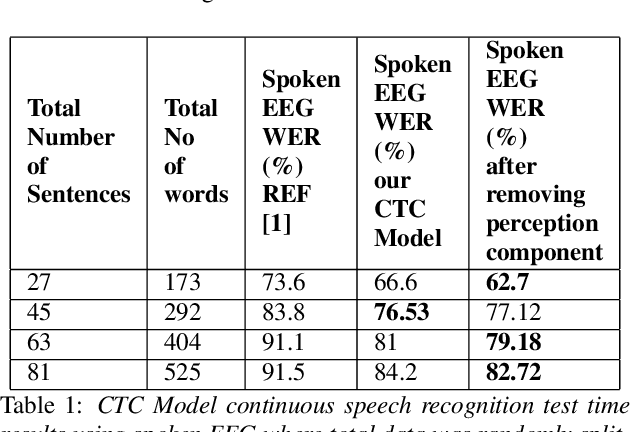
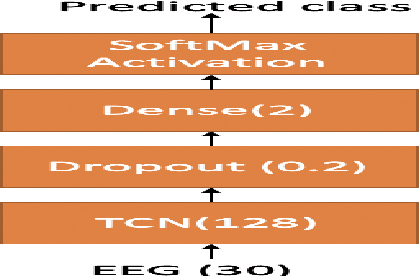
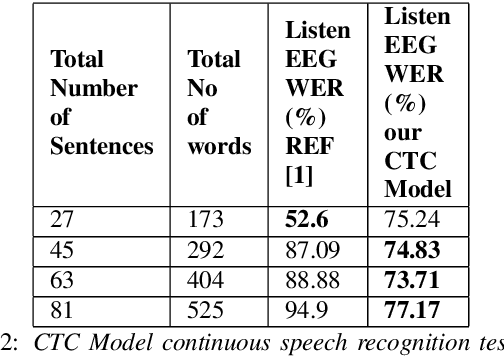
The electroencephalography (EEG) signals recorded in parallel with speech are used to perform isolated and continuous speech recognition. During speaking process, one also hears his or her own speech and this speech perception is also reflected in the recorded EEG signals. In this paper we investigate whether it is possible to separate out this speech perception component from EEG signals in order to design more robust EEG based speech recognition systems. We further demonstrate predicting EEG signals recorded in parallel with speaking from EEG signals recorded in parallel with passive listening and vice versa with very low normalized root mean squared error (RMSE). We finally demonstrate both isolated and continuous speech recognition using EEG signals recorded in parallel with listening, speaking and improve the previous connectionist temporal classification (CTC) model results demonstrated by authors in [1] using their data set.
Predicting Different Acoustic Features from EEG and towards direct synthesis of Audio Waveform from EEG
May 29, 2020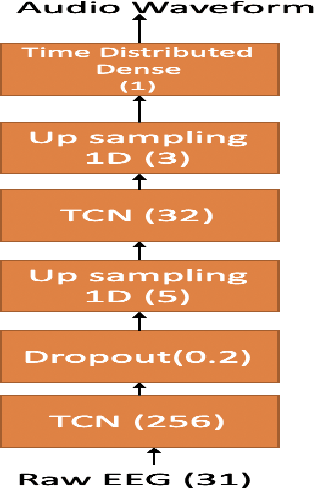
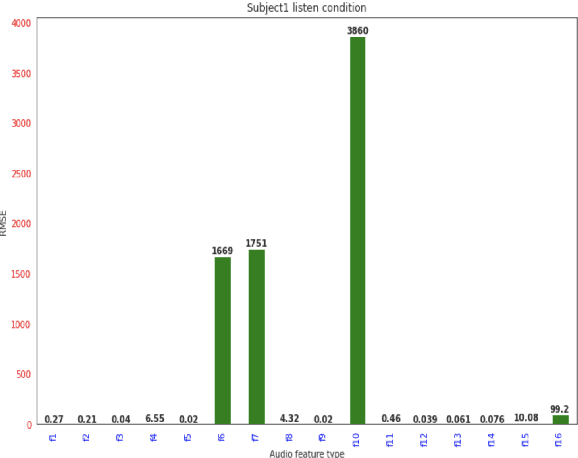
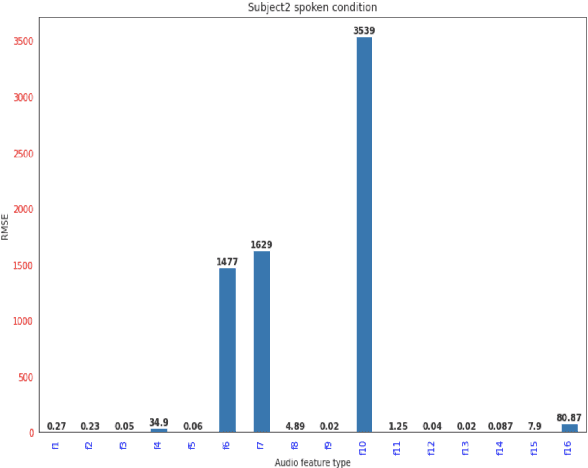
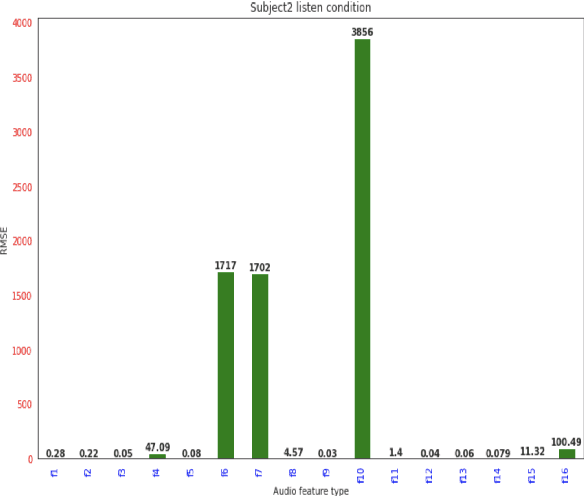
In [1,2] authors provided preliminary results for synthesizing speech from electroencephalography (EEG) features where they first predict acoustic features from EEG features and then the speech is reconstructed from the predicted acoustic features using griffin lim reconstruction algorithm. In this paper we first introduce a deep learning model that takes raw EEG waveform signals as input and directly produces audio waveform as output. We then demonstrate predicting 16 different acoustic features from EEG features. We demonstrate our results for both spoken and listen condition in this paper. The results presented in this paper shows how different acoustic features are related to non-invasive neural EEG signals recorded during speech perception and production.
Predicting Video features from EEG and Vice versa
May 16, 2020


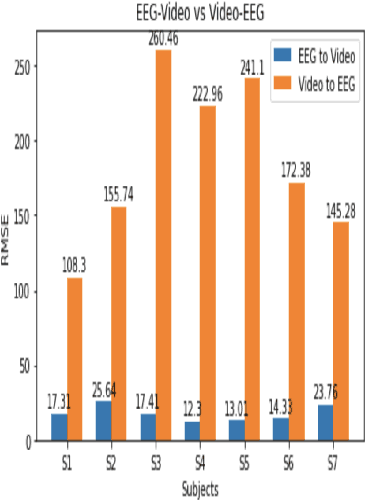
In this paper we explore predicting facial or lip video features from electroencephalography (EEG) features and predicting EEG features from recorded facial or lip video frames using deep learning models. The subjects were asked to read out loud English sentences shown to them on a computer screen and their simultaneous EEG signals and facial video frames were recorded. Our model was able to generate very broad characteristics of the facial or lip video frame from input EEG features. Our results demonstrate the first step towards synthesizing high quality facial or lip video from recorded EEG features. We demonstrate results for a data set consisting of seven subjects.
Advancing Speech Synthesis using EEG
May 03, 2020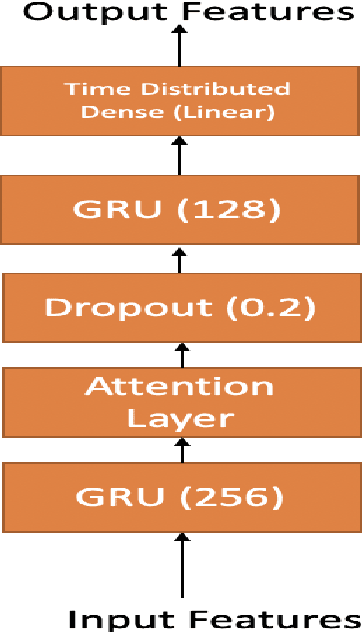

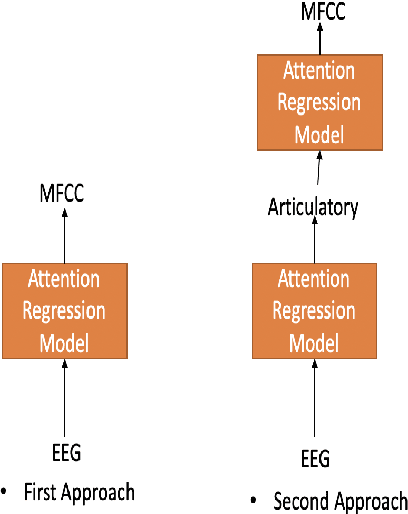
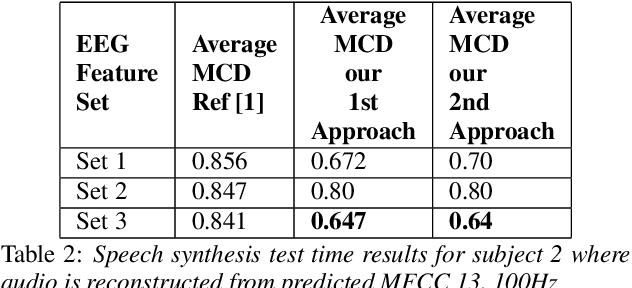
In this paper we introduce attention-regression model to demonstrate predicting acoustic features from electroencephalography (EEG) features recorded in parallel with spoken sentences. First we demonstrate predicting acoustic features directly from EEG features using our attention model and then we demonstrate predicting acoustic features from EEG features using a two-step approach where in the first step we use our attention model to predict articulatory features from EEG features and then in second step another attention-regression model is trained to transform the predicted articulatory features to acoustic features. Our proposed attention-regression model demonstrates superior performance compared to the regression model introduced by authors in [1] when tested using their data set for majority of the subjects during test time. The results presented in this paper further advances the work described by authors in [1].