Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Video features from EEG and Vice versa
Paper and Code
May 16, 2020


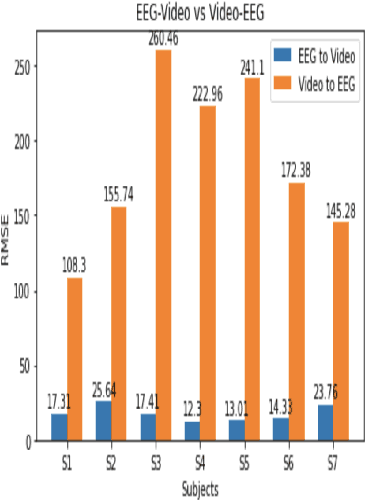
In this paper we explore predicting facial or lip video features from electroencephalography (EEG) features and predicting EEG features from recorded facial or lip video frames using deep learning models. The subjects were asked to read out loud English sentences shown to them on a computer screen and their simultaneous EEG signals and facial video frames were recorded. Our model was able to generate very broad characteristics of the facial or lip video frame from input EEG features. Our results demonstrate the first step towards synthesizing high quality facial or lip video from recorded EEG features. We demonstrate results for a data set consisting of seven subjects.
* under review
View paper on