 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding effect of speech perception in EEG based speech recognition systems
Paper and Code
May 29, 2020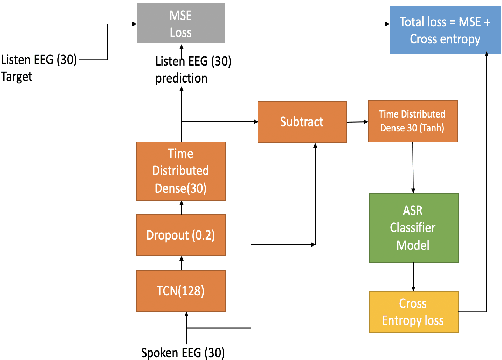
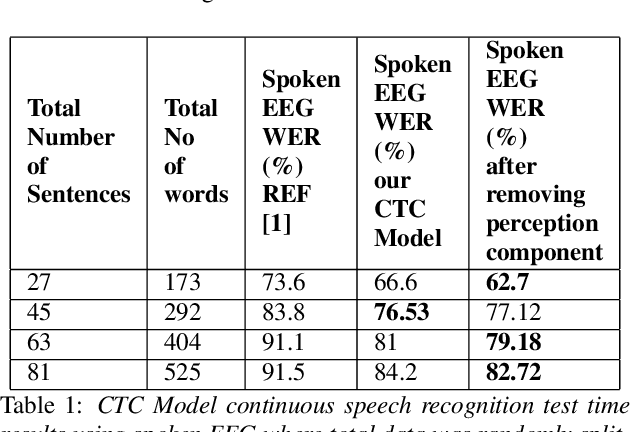
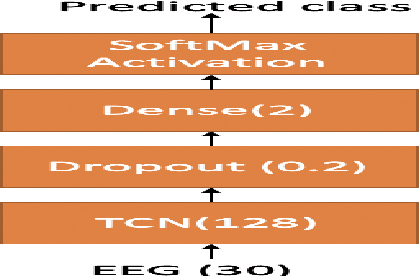
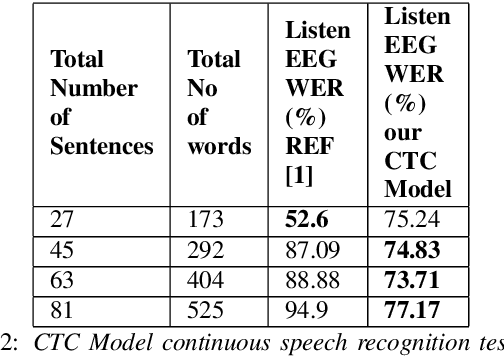
The electroencephalography (EEG) signals recorded in parallel with speech are used to perform isolated and continuous speech recognition. During speaking process, one also hears his or her own speech and this speech perception is also reflected in the recorded EEG signals. In this paper we investigate whether it is possible to separate out this speech perception component from EEG signals in order to design more robust EEG based speech recognition systems. We further demonstrate predicting EEG signals recorded in parallel with speaking from EEG signals recorded in parallel with passive listening and vice versa with very low normalized root mean squared error (RMSE). We finally demonstrate both isolated and continuous speech recognition using EEG signals recorded in parallel with listening, speaking and improve the previous connectionist temporal classification (CTC) model results demonstrated by authors in [1] using their data set.