 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Speech Synthesis using EEG
Paper and Code
May 03, 2020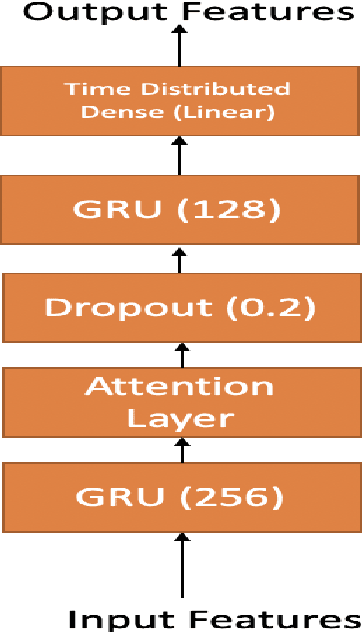

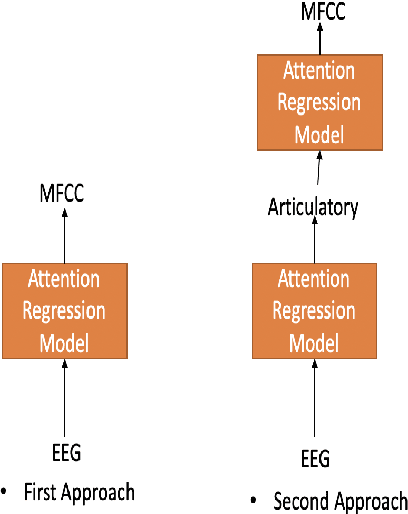
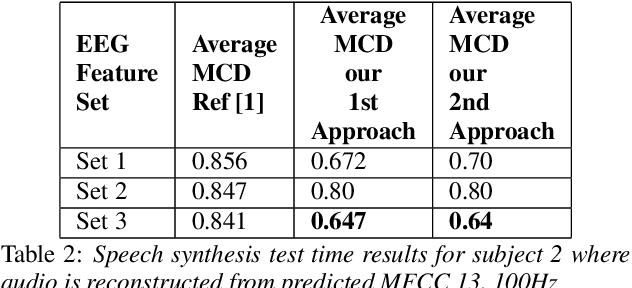
In this paper we introduce attention-regression model to demonstrate predicting acoustic features from electroencephalography (EEG) features recorded in parallel with spoken sentences. First we demonstrate predicting acoustic features directly from EEG features using our attention model and then we demonstrate predicting acoustic features from EEG features using a two-step approach where in the first step we use our attention model to predict articulatory features from EEG features and then in second step another attention-regression model is trained to transform the predicted articulatory features to acoustic features. Our proposed attention-regression model demonstrates superior performance compared to the regression model introduced by authors in [1] when tested using their data set for majority of the subjects during test time. The results presented in this paper further advances the work described by authors in [1].