 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess or More: Towards Glanceable Explanations for LLM Recommendations Using Ultra-Small Devices
Feb 26, 2025Large Language Models (LLMs) have shown remarkable potential in recommending everyday actions as personal AI assistants, while Explainable AI (XAI) techniques are being increasingly utilized to help users understand why a recommendation is given. Personal AI assistants today are often located on ultra-small devices such as smartwatches, which have limited screen space. The verbosity of LLM-generated explanations, however, makes it challenging to deliver glanceable LLM explanations on such ultra-small devices. To address this, we explored 1) spatially structuring an LLM's explanation text using defined contextual components during prompting and 2) presenting temporally adaptive explanations to users based on confidence levels. We conducted a user study to understand how these approaches impacted user experiences when interacting with LLM recommendations and explanations on ultra-small devices. The results showed that structured explanations reduced users' time to action and cognitive load when reading an explanation. Always-on structured explanations increased users' acceptance of AI recommendations. However, users were less satisfied with structured explanations compared to unstructured ones due to their lack of sufficient, readable details. Additionally, adaptively presenting structured explanations was less effective at improving user perceptions of the AI compared to the always-on structured explanations. Together with users' interview feedback, the results led to design implications to be mindful of when personalizing the content and timing of LLM explanations that are displayed on ultra-small devices.
Multiscale Video Pretraining for Long-Term Activity Forecasting
Jul 24, 2023Long-term activity forecasting is an especially challenging research problem because it requires understanding the temporal relationships between observed actions, as well as the variability and complexity of human activities. Despite relying on strong supervision via expensive human annotations, state-of-the-art forecasting approaches often generalize poorly to unseen data. To alleviate this issue, we propose Multiscale Video Pretraining (MVP), a novel self-supervised pretraining approach that learns robust representations for forecasting by learning to predict contextualized representations of future video clips over multiple timescales. MVP is based on our observation that actions in videos have a multiscale nature, where atomic actions typically occur at a short timescale and more complex actions may span longer timescales. We compare MVP to state-of-the-art self-supervised video learning approaches on downstream long-term forecasting tasks including long-term action anticipation and video summary prediction. Our comprehensive experiments across the Ego4D and Epic-Kitchens-55/100 datasets demonstrate that MVP out-performs state-of-the-art methods by significant margins. Notably, MVP obtains a relative performance gain of over 20% accuracy in video summary forecasting over existing methods.
EgoAdapt: A multi-stream evaluation study of adaptation to real-world egocentric user video
Jul 11, 2023



In egocentric action recognition a single population model is typically trained and subsequently embodied on a head-mounted device, such as an augmented reality headset. While this model remains static for new users and environments, we introduce an adaptive paradigm of two phases, where after pretraining a population model, the model adapts on-device and online to the user's experience. This setting is highly challenging due to the change from population to user domain and the distribution shifts in the user's data stream. Coping with the latter in-stream distribution shifts is the focus of continual learning, where progress has been rooted in controlled benchmarks but challenges faced in real-world applications often remain unaddressed. We introduce EgoAdapt, a benchmark for real-world egocentric action recognition that facilitates our two-phased adaptive paradigm, and real-world challenges naturally occur in the egocentric video streams from Ego4d, such as long-tailed action distributions and large-scale classification over 2740 actions. We introduce an evaluation framework that directly exploits the user's data stream with new metrics to measure the adaptation gain over the population model, online generalization, and hindsight performance. In contrast to single-stream evaluation in existing works, our framework proposes a meta-evaluation that aggregates the results from 50 independent user streams. We provide an extensive empirical study for finetuning and experience replay.
Convolutional Bipartite Attractor Networks
Jun 15, 2019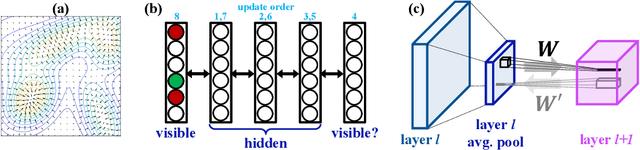
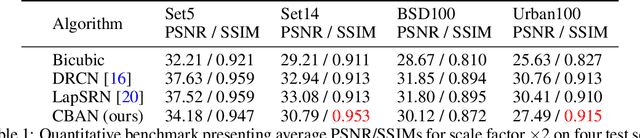


In human perception and cognition, the fundamental operation that brains perform is interpretation: constructing coherent neural states from noisy, incomplete, and intrinsically ambiguous evidence. The problem of interpretation is well matched to an early and often overlooked architecture, the attractor network---a recurrent neural network that performs constraint satisfaction, imputation of missing features, and clean up of noisy data via energy minimization dynamics. We revisit attractor nets in light of modern deep learning methods, and propose a convolutional bipartite architecture with a novel training loss, activation function, and connectivity constraints. We tackle problems much larger than have been previously explored with attractor nets and demonstrate their potential for image denoising, completion, and super-resolution. We argue that this architecture is better motivated than ever-deeper feedforward models and is a viable alternative to more costly sampling-based methods on a range of supervised and unsupervised tasks.