 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Work Embeddings: Contrastive Learning of a Bidirectional Multi-task Ranker
Nov 11, 2025



Workforce transformation across diverse industries has driven an increased demand for specialized natural language processing capabilities. Nevertheless, tasks derived from work-related contexts inherently reflect real-world complexities, characterized by long-tailed distributions, extreme multi-label target spaces, and scarce data availability. The rise of generalist embedding models prompts the question of their performance in the work domain, especially as progress in the field has focused mainly on individual tasks. To this end, we introduce WorkBench, the first unified evaluation suite spanning six work-related tasks formulated explicitly as ranking problems, establishing a common ground for multi-task progress. Based on this benchmark, we find significant positive cross-task transfer, and use this insight to compose task-specific bipartite graphs from real-world data, synthetically enriched through grounding. This leads to Unified Work Embeddings (UWE), a task-agnostic bi-encoder that exploits our training-data structure with a many-to-many InfoNCE objective, and leverages token-level embeddings with task-agnostic soft late interaction. UWE demonstrates zero-shot ranking performance on unseen target spaces in the work domain, enables low-latency inference by caching the task target space embeddings, and shows significant gains in macro-averaged MAP and RP@10 over generalist embedding models.
Towards Open-World Gesture Recognition
Jan 20, 2024



Static machine learning methods in gesture recognition assume that training and test data come from the same underlying distribution. However, in real-world applications involving gesture recognition on wrist-worn devices, data distribution may change over time. We formulate this problem of adapting recognition models to new tasks, where new data patterns emerge, as open-world gesture recognition (OWGR). We propose leveraging continual learning to make machine learning models adaptive to new tasks without degrading performance on previously learned tasks. However, the exploration of parameters for questions around when and how to train and deploy recognition models requires time-consuming user studies and is sometimes impractical. To address this challenge, we propose a design engineering approach that enables offline analysis on a collected large-scale dataset with various parameters and compares different continual learning methods. Finally, design guidelines are provided to enhance the development of an open-world wrist-worn gesture recognition process.
Multiscale Video Pretraining for Long-Term Activity Forecasting
Jul 24, 2023Long-term activity forecasting is an especially challenging research problem because it requires understanding the temporal relationships between observed actions, as well as the variability and complexity of human activities. Despite relying on strong supervision via expensive human annotations, state-of-the-art forecasting approaches often generalize poorly to unseen data. To alleviate this issue, we propose Multiscale Video Pretraining (MVP), a novel self-supervised pretraining approach that learns robust representations for forecasting by learning to predict contextualized representations of future video clips over multiple timescales. MVP is based on our observation that actions in videos have a multiscale nature, where atomic actions typically occur at a short timescale and more complex actions may span longer timescales. We compare MVP to state-of-the-art self-supervised video learning approaches on downstream long-term forecasting tasks including long-term action anticipation and video summary prediction. Our comprehensive experiments across the Ego4D and Epic-Kitchens-55/100 datasets demonstrate that MVP out-performs state-of-the-art methods by significant margins. Notably, MVP obtains a relative performance gain of over 20% accuracy in video summary forecasting over existing methods.
EgoAdapt: A multi-stream evaluation study of adaptation to real-world egocentric user video
Jul 11, 2023



In egocentric action recognition a single population model is typically trained and subsequently embodied on a head-mounted device, such as an augmented reality headset. While this model remains static for new users and environments, we introduce an adaptive paradigm of two phases, where after pretraining a population model, the model adapts on-device and online to the user's experience. This setting is highly challenging due to the change from population to user domain and the distribution shifts in the user's data stream. Coping with the latter in-stream distribution shifts is the focus of continual learning, where progress has been rooted in controlled benchmarks but challenges faced in real-world applications often remain unaddressed. We introduce EgoAdapt, a benchmark for real-world egocentric action recognition that facilitates our two-phased adaptive paradigm, and real-world challenges naturally occur in the egocentric video streams from Ego4d, such as long-tailed action distributions and large-scale classification over 2740 actions. We introduce an evaluation framework that directly exploits the user's data stream with new metrics to measure the adaptation gain over the population model, online generalization, and hindsight performance. In contrast to single-stream evaluation in existing works, our framework proposes a meta-evaluation that aggregates the results from 50 independent user streams. We provide an extensive empirical study for finetuning and experience replay.
3rd Continual Learning Workshop Challenge on Egocentric Category and Instance Level Object Understanding
Dec 13, 2022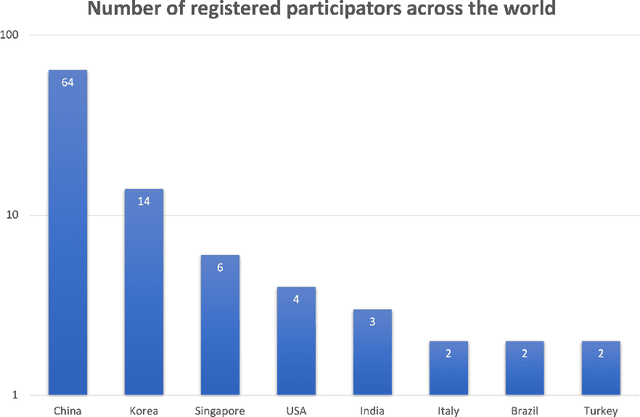
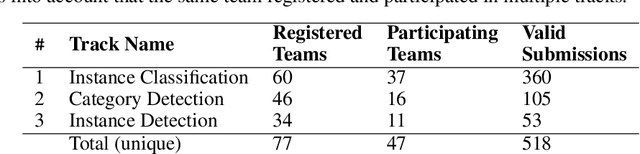


Continual Learning, also known as Lifelong or Incremental Learning, has recently gained renewed interest among the Artificial Intelligence research community. Recent research efforts have quickly led to the design of novel algorithms able to reduce the impact of the catastrophic forgetting phenomenon in deep neural networks. Due to this surge of interest in the field, many competitions have been held in recent years, as they are an excellent opportunity to stimulate research in promising directions. This paper summarizes the ideas, design choices, rules, and results of the challenge held at the 3rd Continual Learning in Computer Vision (CLVision) Workshop at CVPR 2022. The focus of this competition is the complex continual object detection task, which is still underexplored in literature compared to classification tasks. The challenge is based on the challenge version of the novel EgoObjects dataset, a large-scale egocentric object dataset explicitly designed to benchmark continual learning algorithms for egocentric category-/instance-level object understanding, which covers more than 1k unique main objects and 250+ categories in around 100k video frames.
CLAD: A realistic Continual Learning benchmark for Autonomous Driving
Oct 07, 2022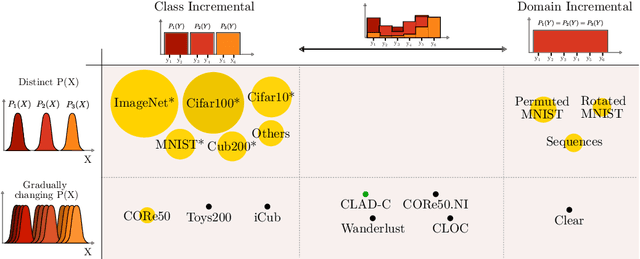

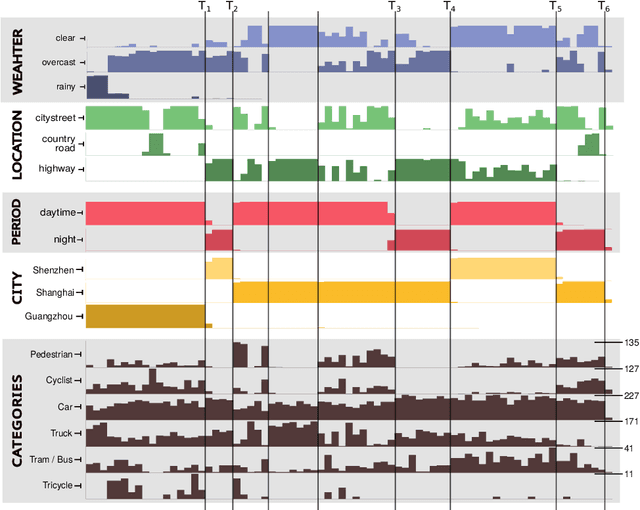
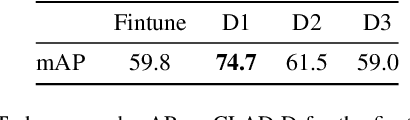
In this paper we describe the design and the ideas motivating a new Continual Learning benchmark for Autonomous Driving (CLAD), that focuses on the problems of object classification and object detection. The benchmark utilises SODA10M, a recently released large-scale dataset that concerns autonomous driving related problems. First, we review and discuss existing continual learning benchmarks, how they are related, and show that most are extreme cases of continual learning. To this end, we survey the benchmarks used in continual learning papers at three highly ranked computer vision conferences. Next, we introduce CLAD-C, an online classification benchmark realised through a chronological data stream that poses both class and domain incremental challenges; and CLAD-D, a domain incremental continual object detection benchmark. We examine the inherent difficulties and challenges posed by the benchmark, through a survey of the techniques and methods used by the top-3 participants in a CLAD-challenge workshop at ICCV 2021. We conclude with possible pathways to improve the current continual learning state of the art, and which directions we deem promising for future research.
Continual evaluation for lifelong learning: Identifying the stability gap
May 26, 2022



Introducing a time dependency on the data generating distribution has proven to be difficult for gradient-based training of neural networks, as the greedy updates result in catastrophic forgetting of previous timesteps. Continual learning aims to overcome the greedy optimization to enable continuous accumulation of knowledge over time. The data stream is typically divided into locally stationary distributions, called tasks, allowing task-based evaluation on held-out data from the training tasks. Contemporary evaluation protocols and metrics in continual learning are task-based and quantify the trade-off between stability and plasticity only at task transitions. However, our empirical evidence suggests that between task transitions significant, temporary forgetting can occur, remaining unidentified in task-based evaluation. Therefore, we propose a framework for continual evaluation that establishes per-iteration evaluation and define a new set of metrics that enables identifying the worst-case performance of the learner over its lifetime. Performing continual evaluation, we empirically identify that replay suffers from a stability gap: upon learning a new task, there is a substantial but transient decrease in performance on past tasks. Further conceptual and empirical analysis suggests not only replay-based, but also regularization-based continual learning methods are prone to the stability gap.
Re-examining Distillation For Continual Object Detection
Apr 04, 2022
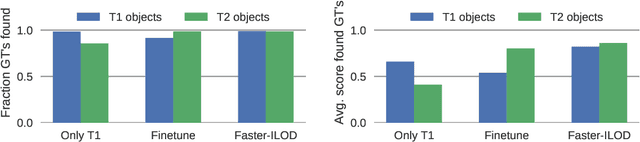


Training models continually to detect and classify objects, from new classes and new domains, remains an open problem. In this work, we conduct a thorough analysis of why and how object detection models forget catastrophically. We focus on distillation-based approaches in two-stage networks; the most-common strategy employed in contemporary continual object detection work.Distillation aims to transfer the knowledge of a model trained on previous tasks -- the teacher -- to a new model -- the student -- while it learns the new task. We show that this works well for the region proposal network, but that wrong, yet overly confident teacher predictions prevent student models from effective learning of the classification head. Our analysis provides a foundation that allows us to propose improvements for existing techniques by detecting incorrect teacher predictions, based on current ground-truth labels, and by employing an adaptive Huber loss as opposed to the mean squared error for the distillation loss in the classification heads. We evidence that our strategy works not only in a class incremental setting, but also in domain incremental settings, which constitute a realistic context, likely to be the setting of representative real-world problems.
Rehearsal revealed: The limits and merits of revisiting samples in continual learning
Apr 15, 2021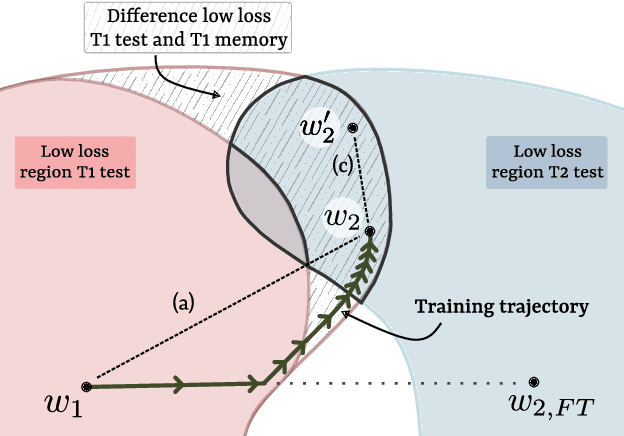

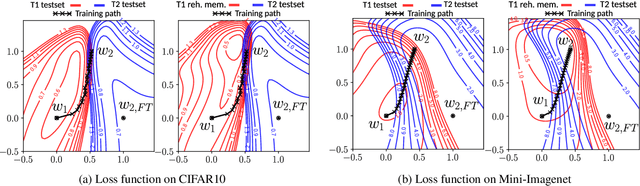

Learning from non-stationary data streams and overcoming catastrophic forgetting still poses a serious challenge for machine learning research. Rather than aiming to improve state-of-the-art, in this work we provide insight into the limits and merits of rehearsal, one of continual learning's most established methods. We hypothesize that models trained sequentially with rehearsal tend to stay in the same low-loss region after a task has finished, but are at risk of overfitting on its sample memory, hence harming generalization. We provide both conceptual and strong empirical evidence on three benchmarks for both behaviors, bringing novel insights into the dynamics of rehearsal and continual learning in general. Finally, we interpret important continual learning works in the light of our findings, allowing for a deeper understanding of their successes.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021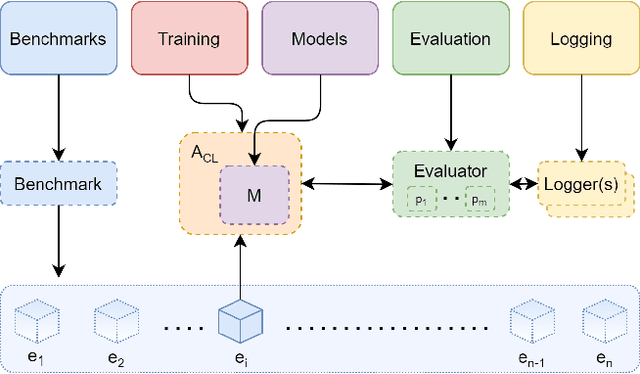


Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.