 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Efficient Split Learning of ViTs with Attention-based Double Compression
Sep 18, 2025



This paper proposes a novel communication-efficient Split Learning (SL) framework, named Attention-based Double Compression (ADC), which reduces the communication overhead required for transmitting intermediate Vision Transformers activations during the SL training process. ADC incorporates two parallel compression strategies. The first one merges samples' activations that are similar, based on the average attention score calculated in the last client layer; this strategy is class-agnostic, meaning that it can also merge samples having different classes, without losing generalization ability nor decreasing final results. The second strategy follows the first and discards the least meaningful tokens, further reducing the communication cost. Combining these strategies not only allows for sending less during the forward pass, but also the gradients are naturally compressed, allowing the whole model to be trained without additional tuning or approximations of the gradients. Simulation results demonstrate that Attention-based Double Compression outperforms state-of-the-art SL frameworks by significantly reducing communication overheads while maintaining high accuracy.
Adaptive Semantic Token Communication for Transformer-based Edge Inference
May 23, 2025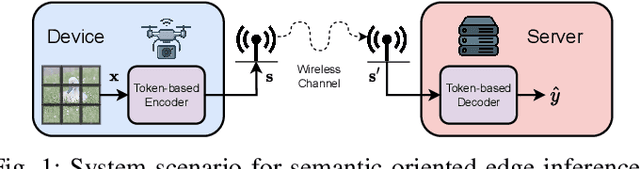



This paper presents an adaptive framework for edge inference based on a dynamically configurable transformer-powered deep joint source channel coding (DJSCC) architecture. Motivated by a practical scenario where a resource constrained edge device engages in goal oriented semantic communication, such as selectively transmitting essential features for object detection to an edge server, our approach enables efficient task aware data transmission under varying bandwidth and channel conditions. To achieve this, input data is tokenized into compact high level semantic representations, refined by a transformer, and transmitted over noisy wireless channels. As part of the DJSCC pipeline, we employ a semantic token selection mechanism that adaptively compresses informative features into a user specified number of tokens per sample. These tokens are then further compressed through the JSCC module, enabling a flexible token communication strategy that adjusts both the number of transmitted tokens and their embedding dimensions. We incorporate a resource allocation algorithm based on Lyapunov stochastic optimization to enhance robustness under dynamic network conditions, effectively balancing compression efficiency and task performance. Experimental results demonstrate that our system consistently outperforms existing baselines, highlighting its potential as a strong foundation for AI native semantic communication in edge intelligence applications.
Goal-oriented Communications based on Recursive Early Exit Neural Networks
Dec 27, 2024



This paper presents a novel framework for goal-oriented semantic communications leveraging recursive early exit models. The proposed approach is built on two key components. First, we introduce an innovative early exit strategy that dynamically partitions computations, enabling samples to be offloaded to a server based on layer-wise recursive prediction dynamics that detect samples for which the confidence is not increasing fast enough over layers. Second, we develop a Reinforcement Learning-based online optimization framework that jointly determines early exit points, computation splitting, and offloading strategies, while accounting for wireless conditions, inference accuracy, and resource costs. Numerical evaluations in an edge inference scenario demonstrate the method's adaptability and effectiveness in striking an excellent trade-off between performance, latency, and resource efficiency.
Adaptive Layer Selection for Efficient Vision Transformer Fine-Tuning
Aug 16, 2024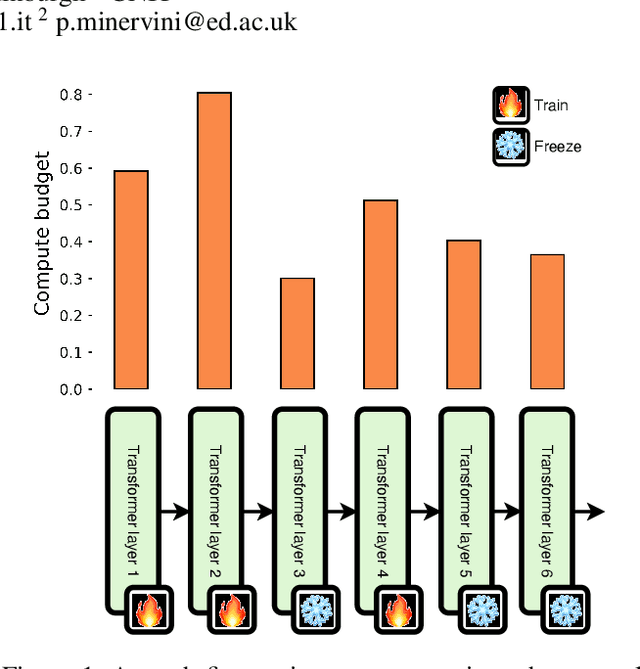


Recently, foundation models based on Vision Transformers (ViTs) have become widely available. However, their fine-tuning process is highly resource-intensive, and it hinders their adoption in several edge or low-energy applications. To this end, in this paper we introduce an efficient fine-tuning method for ViTs called $\textbf{ALaST}$ ($\textit{Adaptive Layer Selection Fine-Tuning for Vision Transformers}$) to speed up the fine-tuning process while reducing computational cost, memory load, and training time. Our approach is based on the observation that not all layers are equally critical during fine-tuning, and their importance varies depending on the current mini-batch. Therefore, at each fine-tuning step, we adaptively estimate the importance of all layers and we assign what we call ``compute budgets'' accordingly. Layers that were allocated lower budgets are either trained with a reduced number of input tokens or kept frozen. Freezing a layer reduces the computational cost and memory usage by preventing updates to its weights, while discarding tokens removes redundant data, speeding up processing and reducing memory requirements. We show that this adaptive compute allocation enables a nearly-optimal schedule for distributing computational resources across layers, resulting in substantial reductions in training time (up to 1.5x), FLOPs (up to 2x), and memory load (up to 2x) compared to traditional full fine-tuning approaches. Additionally, it can be successfully combined with other parameter-efficient fine-tuning methods, such as LoRA.
Joint or Disjoint: Mixing Training Regimes for Early-Exit Models
Jul 19, 2024Early exits are an important efficiency mechanism integrated into deep neural networks that allows for the termination of the network's forward pass before processing through all its layers. By allowing early halting of the inference process for less complex inputs that reached high confidence, early exits significantly reduce the amount of computation required. Early exit methods add trainable internal classifiers which leads to more intricacy in the training process. However, there is no consistent verification of the approaches of training of early exit methods, and no unified scheme of training such models. Most early exit methods employ a training strategy that either simultaneously trains the backbone network and the exit heads or trains the exit heads separately. We propose a training approach where the backbone is initially trained on its own, followed by a phase where both the backbone and the exit heads are trained together. Thus, we advocate for organizing early-exit training strategies into three distinct categories, and then validate them for their performance and efficiency. In this benchmark, we perform both theoretical and empirical analysis of early-exit training regimes. We study the methods in terms of information flow, loss landscape and numerical rank of activations and gauge the suitability of regimes for various architectures and datasets.
Adaptive Semantic Token Selection for AI-native Goal-oriented Communications
Apr 25, 2024In this paper, we propose a novel design for AI-native goal-oriented communications, exploiting transformer neural networks under dynamic inference constraints on bandwidth and computation. Transformers have become the standard architecture for pretraining large-scale vision and text models, and preliminary results have shown promising performance also in deep joint source-channel coding (JSCC). Here, we consider a dynamic model where communication happens over a channel with variable latency and bandwidth constraints. Leveraging recent works on conditional computation, we exploit the structure of the transformer blocks and the multihead attention operator to design a trainable semantic token selection mechanism that learns to select relevant tokens (e.g., image patches) from the input signal. This is done dynamically, on a per-input basis, with a rate that can be chosen as an additional input by the user. We show that our model improves over state-of-the-art token selection mechanisms, exhibiting high accuracy for a wide range of latency and bandwidth constraints, without the need for deploying multiple architectures tailored to each constraint. Last, but not least, the proposed token selection mechanism helps extract powerful semantics that are easy to understand and explain, paving the way for interpretable-by-design models for the next generation of AI-native communication systems.
Conditional computation in neural networks: principles and research trends
Mar 12, 2024



This article summarizes principles and ideas from the emerging area of applying \textit{conditional computation} methods to the design of neural networks. In particular, we focus on neural networks that can dynamically activate or de-activate parts of their computational graph conditionally on their input. Examples include the dynamic selection of, e.g., input tokens, layers (or sets of layers), and sub-modules inside each layer (e.g., channels in a convolutional filter). We first provide a general formalism to describe these techniques in an uniform way. Then, we introduce three notable implementations of these principles: mixture-of-experts (MoEs) networks, token selection mechanisms, and early-exit neural networks. The paper aims to provide a tutorial-like introduction to this growing field. To this end, we analyze the benefits of these modular designs in terms of efficiency, explainability, and transfer learning, with a focus on emerging applicative areas ranging from automated scientific discovery to semantic communication.
Cascaded Scaling Classifier: class incremental learning with probability scaling
Feb 05, 2024Humans are capable of acquiring new knowledge and transferring learned knowledge into different domains, incurring a small forgetting. The same ability, called Continual Learning, is challenging to achieve when operating with neural networks due to the forgetting affecting past learned tasks when learning new ones. This forgetting can be mitigated by replaying stored samples from past tasks, but a large memory size may be needed for long sequences of tasks; moreover, this could lead to overfitting on saved samples. In this paper, we propose a novel regularisation approach and a novel incremental classifier called, respectively, Margin Dampening and Cascaded Scaling Classifier. The first combines a soft constraint and a knowledge distillation approach to preserve past learned knowledge while allowing the model to learn new patterns effectively. The latter is a gated incremental classifier, helping the model modify past predictions without directly interfering with them. This is achieved by modifying the output of the model with auxiliary scaling functions. We empirically show that our approach performs well on multiple benchmarks against well-established baselines, and we also study each component of our proposal and how the combinations of such components affect the final results.
NACHOS: Neural Architecture Search for Hardware Constrained Early Exit Neural Networks
Jan 24, 2024Early Exit Neural Networks (EENNs) endow astandard Deep Neural Network (DNN) with Early Exit Classifiers (EECs), to provide predictions at intermediate points of the processing when enough confidence in classification is achieved. This leads to many benefits in terms of effectiveness and efficiency. Currently, the design of EENNs is carried out manually by experts, a complex and time-consuming task that requires accounting for many aspects, including the correct placement, the thresholding, and the computational overhead of the EECs. For this reason, the research is exploring the use of Neural Architecture Search (NAS) to automatize the design of EENNs. Currently, few comprehensive NAS solutions for EENNs have been proposed in the literature, and a fully automated, joint design strategy taking into consideration both the backbone and the EECs remains an open problem. To this end, this work presents Neural Architecture Search for Hardware Constrained Early Exit Neural Networks (NACHOS), the first NAS framework for the design of optimal EENNs satisfying constraints on the accuracy and the number of Multiply and Accumulate (MAC) operations performed by the EENNs at inference time. In particular, this provides the joint design of backbone and EECs to select a set of admissible (i.e., respecting the constraints) Pareto Optimal Solutions in terms of best tradeoff between the accuracy and number of MACs. The results show that the models designed by NACHOS are competitive with the state-of-the-art EENNs. Additionally, this work investigates the effectiveness of two novel regularization terms designed for the optimization of the auxiliary classifiers of the EENN
Centroids Matching: an efficient Continual Learning approach operating in the embedding space
Aug 03, 2022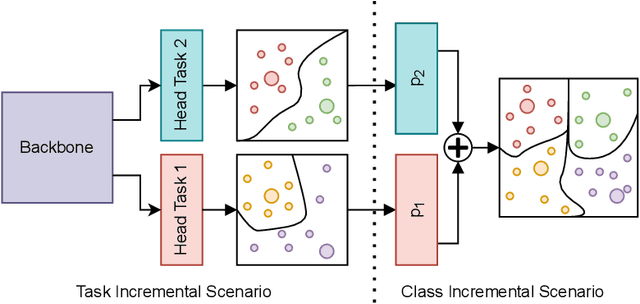


Catastrophic forgetting (CF) occurs when a neural network loses the information previously learned while training on a set of samples from a different distribution, i.e., a new task. Existing approaches have achieved remarkable results in mitigating CF, especially in a scenario called task incremental learning. However, this scenario is not realistic, and limited work has been done to achieve good results on more realistic scenarios. In this paper, we propose a novel regularization method called Centroids Matching, that, inspired by meta-learning approaches, fights CF by operating in the feature space produced by the neural network, achieving good results while requiring a small memory footprint. Specifically, the approach classifies the samples directly using the feature vectors produced by the neural network, by matching those vectors with the centroids representing the classes from the current task, or all the tasks up to that point. Centroids Matching is faster than competing baselines, and it can be exploited to efficiently mitigate CF, by preserving the distances between the embedding space produced by the model when past tasks were over, and the one currently produced, leading to a method that achieves high accuracy on all the tasks, without using an external memory when operating on easy scenarios, or using a small one for more realistic ones. Extensive experiments demonstrate that Centroids Matching achieves accuracy gains on multiple datasets and scenarios.