 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQUAD: Scalable Quorum Adaptive Decisions via ensemble of early exit neural networks
Jan 30, 2026Early-exit neural networks have become popular for reducing inference latency by allowing intermediate predictions when sufficient confidence is achieved. However, standard approaches typically rely on single-model confidence thresholds, which are frequently unreliable due to inherent calibration issues. To address this, we introduce SQUAD (Scalable Quorum Adaptive Decisions), the first inference scheme that integrates early-exit mechanisms with distributed ensemble learning, improving uncertainty estimation while reducing the inference time. Unlike traditional methods that depend on individual confidence scores, SQUAD employs a quorum-based stopping criterion on early-exit learners by collecting intermediate predictions incrementally in order of computational complexity until a consensus is reached and halting the computation at that exit if the consensus is statistically significant. To maximize the efficacy of this voting mechanism, we also introduce QUEST (Quorum Search Technique), a Neural Architecture Search method to select early-exit learners with optimized hierarchical diversity, ensuring learners are complementary at every intermediate layer. This consensus-driven approach yields statistically robust early exits, improving the test accuracy up to 5.95% compared to state-of-the-art dynamic solutions with a comparable computational cost and reducing the inference latency up to 70.60% compared to static ensembles while maintaining a good accuracy.
SEAL: Searching Expandable Architectures for Incremental Learning
May 15, 2025Incremental learning is a machine learning paradigm where a model learns from a sequential stream of tasks. This setting poses a key challenge: balancing plasticity (learning new tasks) and stability (preserving past knowledge). Neural Architecture Search (NAS), a branch of AutoML, automates the design of the architecture of Deep Neural Networks and has shown success in static settings. However, existing NAS-based approaches to incremental learning often rely on expanding the model at every task, making them impractical in resource-constrained environments. In this work, we introduce SEAL, a NAS-based framework tailored for data-incremental learning, a scenario where disjoint data samples arrive sequentially and are not stored for future access. SEAL adapts the model structure dynamically by expanding it only when necessary, based on a capacity estimation metric. Stability is preserved through cross-distillation training after each expansion step. The NAS component jointly searches for both the architecture and the optimal expansion policy. Experiments across multiple benchmarks demonstrate that SEAL effectively reduces forgetting and enhances accuracy while maintaining a lower model size compared to prior methods. These results highlight the promise of combining NAS and selective expansion for efficient, adaptive learning in incremental scenarios.
DYNAMAX: Dynamic computing for Transformers and Mamba based architectures
Apr 29, 2025Early exits (EEs) offer a promising approach to reducing computational costs and latency by dynamically terminating inference once a satisfactory prediction confidence on a data sample is achieved. Although many works integrate EEs into encoder-only Transformers, their application to decoder-only architectures and, more importantly, Mamba models, a novel family of state-space architectures in the LLM realm, remains insufficiently explored. This work introduces DYNAMAX, the first framework to exploit the unique properties of Mamba architectures for early exit mechanisms. We not only integrate EEs into Mamba but also repurpose Mamba as an efficient EE classifier for both Mamba-based and transformer-based LLMs, showcasing its versatility. Our experiments employ the Mistral 7B transformer compared to the Codestral 7B Mamba model, using data sets such as TruthfulQA, CoQA, and TriviaQA to evaluate computational savings, accuracy, and consistency. The results highlight the adaptability of Mamba as a powerful EE classifier and its efficiency in balancing computational cost and performance quality across NLP tasks. By leveraging Mamba's inherent design for dynamic processing, we open pathways for scalable and efficient inference in embedded applications and resource-constrained environments. This study underscores the transformative potential of Mamba in redefining dynamic computing paradigms for LLMs.
Architecture-Aware Minimization (A$^2$M): How to Find Flat Minima in Neural Architecture Search
Mar 13, 2025Neural Architecture Search (NAS) has become an essential tool for designing effective and efficient neural networks. In this paper, we investigate the geometric properties of neural architecture spaces commonly used in differentiable NAS methods, specifically NAS-Bench-201 and DARTS. By defining flatness metrics such as neighborhoods and loss barriers along paths in architecture space, we reveal locality and flatness characteristics analogous to the well-known properties of neural network loss landscapes in weight space. In particular, we find that highly accurate architectures cluster together in flat regions, while suboptimal architectures remain isolated, unveiling the detailed geometrical structure of the architecture search landscape. Building on these insights, we propose Architecture-Aware Minimization (A$^2$M), a novel analytically derived algorithmic framework that explicitly biases, for the first time, the gradient of differentiable NAS methods towards flat minima in architecture space. A$^2$M consistently improves generalization over state-of-the-art DARTS-based algorithms on benchmark datasets including CIFAR-10, CIFAR-100, and ImageNet16-120, across both NAS-Bench-201 and DARTS search spaces. Notably, A$^2$M is able to increase the test accuracy, on average across different differentiable NAS methods, by +3.60\% on CIFAR-10, +4.60\% on CIFAR-100, and +3.64\% on ImageNet16-120, demonstrating its superior effectiveness in practice. A$^2$M can be easily integrated into existing differentiable NAS frameworks, offering a versatile tool for future research and applications in automated machine learning. We open-source our code at https://github.com/AI-Tech-Research-Lab/AsquaredM.
ZO-DARTS++: An Efficient and Size-Variable Zeroth-Order Neural Architecture Search Algorithm
Mar 08, 2025Differentiable Neural Architecture Search (NAS) provides a promising avenue for automating the complex design of deep learning (DL) models. However, current differentiable NAS methods often face constraints in efficiency, operation selection, and adaptability under varying resource limitations. We introduce ZO-DARTS++, a novel NAS method that effectively balances performance and resource constraints. By integrating a zeroth-order approximation for efficient gradient handling, employing a sparsemax function with temperature annealing for clearer and more interpretable architecture distributions, and adopting a size-variable search scheme for generating compact yet accurate architectures, ZO-DARTS++ establishes a new balance between model complexity and performance. In extensive tests on medical imaging datasets, ZO-DARTS++ improves the average accuracy by up to 1.8\% over standard DARTS-based methods and shortens search time by approximately 38.6\%. Additionally, its resource-constrained variants can reduce the number of parameters by more than 35\% while maintaining competitive accuracy levels. Thus, ZO-DARTS++ offers a versatile and efficient framework for generating high-quality, resource-aware DL models suitable for real-world medical applications.
A Lightweight Neural Architecture Search Model for Medical Image Classification
May 06, 2024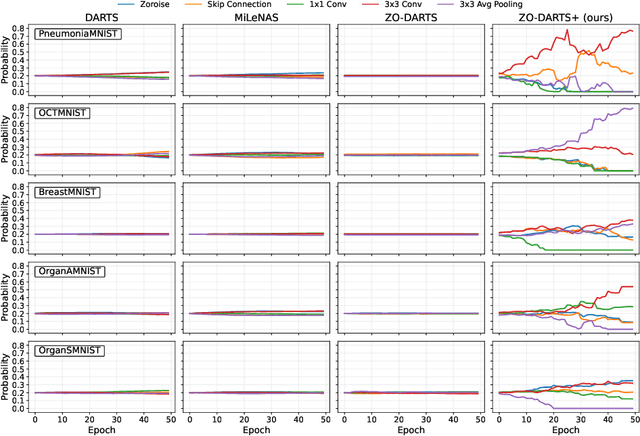

Accurate classification of medical images is essential for modern diagnostics. Deep learning advancements led clinicians to increasingly use sophisticated models to make faster and more accurate decisions, sometimes replacing human judgment. However, model development is costly and repetitive. Neural Architecture Search (NAS) provides solutions by automating the design of deep learning architectures. This paper presents ZO-DARTS+, a differentiable NAS algorithm that improves search efficiency through a novel method of generating sparse probabilities by bi-level optimization. Experiments on five public medical datasets show that ZO-DARTS+ matches the accuracy of state-of-the-art solutions while reducing search times by up to three times.
FlatNAS: optimizing Flatness in Neural Architecture Search for Out-of-Distribution Robustness
Feb 29, 2024Neural Architecture Search (NAS) paves the way for the automatic definition of Neural Network (NN) architectures, attracting increasing research attention and offering solutions in various scenarios. This study introduces a novel NAS solution, called Flat Neural Architecture Search (FlatNAS), which explores the interplay between a novel figure of merit based on robustness to weight perturbations and single NN optimization with Sharpness-Aware Minimization (SAM). FlatNAS is the first work in the literature to systematically explore flat regions in the loss landscape of NNs in a NAS procedure, while jointly optimizing their performance on in-distribution data, their out-of-distribution (OOD) robustness, and constraining the number of parameters in their architecture. Differently from current studies primarily concentrating on OOD algorithms, FlatNAS successfully evaluates the impact of NN architectures on OOD robustness, a crucial aspect in real-world applications of machine and deep learning. FlatNAS achieves a good trade-off between performance, OOD generalization, and the number of parameters, by using only in-distribution data in the NAS exploration. The OOD robustness of the NAS-designed models is evaluated by focusing on robustness to input data corruptions, using popular benchmark datasets in the literature.
NACHOS: Neural Architecture Search for Hardware Constrained Early Exit Neural Networks
Jan 24, 2024Early Exit Neural Networks (EENNs) endow astandard Deep Neural Network (DNN) with Early Exit Classifiers (EECs), to provide predictions at intermediate points of the processing when enough confidence in classification is achieved. This leads to many benefits in terms of effectiveness and efficiency. Currently, the design of EENNs is carried out manually by experts, a complex and time-consuming task that requires accounting for many aspects, including the correct placement, the thresholding, and the computational overhead of the EECs. For this reason, the research is exploring the use of Neural Architecture Search (NAS) to automatize the design of EENNs. Currently, few comprehensive NAS solutions for EENNs have been proposed in the literature, and a fully automated, joint design strategy taking into consideration both the backbone and the EECs remains an open problem. To this end, this work presents Neural Architecture Search for Hardware Constrained Early Exit Neural Networks (NACHOS), the first NAS framework for the design of optimal EENNs satisfying constraints on the accuracy and the number of Multiply and Accumulate (MAC) operations performed by the EENNs at inference time. In particular, this provides the joint design of backbone and EECs to select a set of admissible (i.e., respecting the constraints) Pareto Optimal Solutions in terms of best tradeoff between the accuracy and number of MACs. The results show that the models designed by NACHOS are competitive with the state-of-the-art EENNs. Additionally, this work investigates the effectiveness of two novel regularization terms designed for the optimization of the auxiliary classifiers of the EENN