 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyGen: Fully Synthetic Vision-Language Training via Multi-Generator Ensembles
Feb 01, 2026Synthetic data offers a scalable solution for vision-language pre-training, yet current state-of-the-art methods typically rely on scaling up a single generative backbone, which introduces generator-specific spectral biases and limits feature diversity. In this work, we introduce PolyGen, a framework that redefines synthetic data construction by prioritizing manifold coverage and compositional rigor over simple dataset size. PolyGen employs a Polylithic approach to train on the intersection of architecturally distinct generators, effectively marginalizing out model-specific artifacts. Additionally, we introduce a Programmatic Hard Negative curriculum that enforces fine-grained syntactic understanding. By structurally reallocating the same data budget from unique captions to multi-source variations, PolyGen achieves a more robust feature space, outperforming the leading single-source baseline (SynthCLIP) by +19.0% on aggregate multi-task benchmarks and on the SugarCrepe++ compositionality benchmark (+9.1%). These results demonstrate that structural diversity is a more data-efficient scaling law than simply increasing the volume of single-source samples.
Deep Variational Contrastive Learning for Joint Risk Stratification and Time-to-Event Estimation
Feb 01, 2026Survival analysis is essential for clinical decision-making, as it allows practitioners to estimate time-to-event outcomes, stratify patient risk profiles, and guide treatment planning. Deep learning has revolutionized this field with unprecedented predictive capabilities but faces a fundamental trade-off between performance and interpretability. While neural networks achieve high accuracy, their black-box nature limits clinical adoption. Conversely, deep clustering-based methods that stratify patients into interpretable risk groups typically sacrifice predictive power. We propose CONVERSE (CONtrastive Variational Ensemble for Risk Stratification and Estimation), a deep survival model that bridges this gap by unifying variational autoencoders with contrastive learning for interpretable risk stratification. CONVERSE combines variational embeddings with multiple intra- and inter-cluster contrastive losses. Self-paced learning progressively incorporates samples from easy to hard, improving training stability. The model supports cluster-specific survival heads, enabling accurate ensemble predictions. Comprehensive evaluation on four benchmark datasets demonstrates that CONVERSE achieves competitive or superior performance compared to existing deep survival methods, while maintaining meaningful patient stratification.
Your Image Generator Is Your New Private Dataset
Apr 08, 2025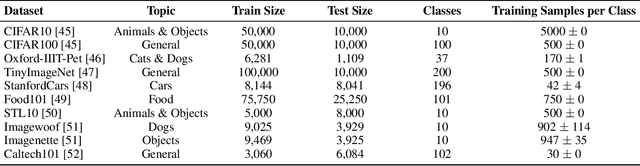
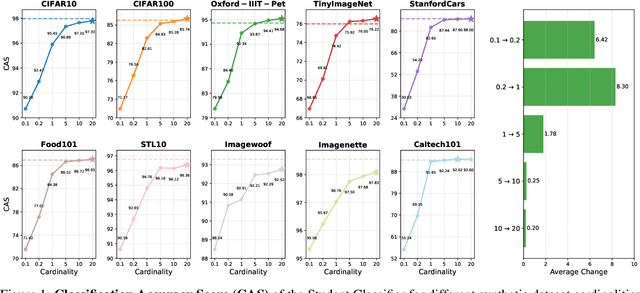
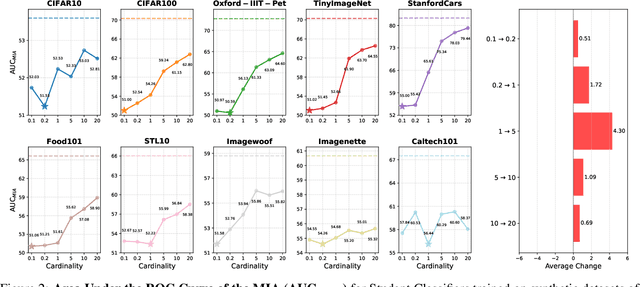
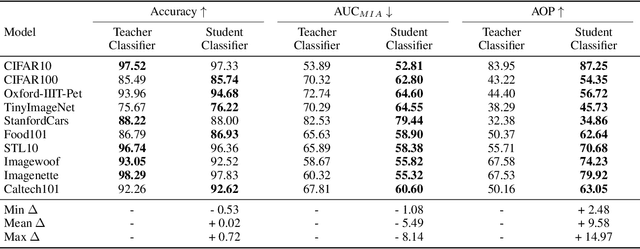
Generative diffusion models have emerged as powerful tools to synthetically produce training data, offering potential solutions to data scarcity and reducing labelling costs for downstream supervised deep learning applications. However, effectively leveraging text-conditioned image generation for building classifier training sets requires addressing key issues: constructing informative textual prompts, adapting generative models to specific domains, and ensuring robust performance. This paper proposes the Text-Conditioned Knowledge Recycling (TCKR) pipeline to tackle these challenges. TCKR combines dynamic image captioning, parameter-efficient diffusion model fine-tuning, and Generative Knowledge Distillation techniques to create synthetic datasets tailored for image classification. The pipeline is rigorously evaluated on ten diverse image classification benchmarks. The results demonstrate that models trained solely on TCKR-generated data achieve classification accuracies on par with (and in several cases exceeding) models trained on real images. Furthermore, the evaluation reveals that these synthetic-data-trained models exhibit substantially enhanced privacy characteristics: their vulnerability to Membership Inference Attacks is significantly reduced, with the membership inference AUC lowered by 5.49 points on average compared to using real training data, demonstrating a substantial improvement in the performance-privacy trade-off. These findings indicate that high-fidelity synthetic data can effectively replace real data for training classifiers, yielding strong performance whilst simultaneously providing improved privacy protection as a valuable emergent property. The code and trained models are available in the accompanying open-source repository.
Neuro-Symbolic Scene Graph Conditioning for Synthetic Image Dataset Generation
Mar 21, 2025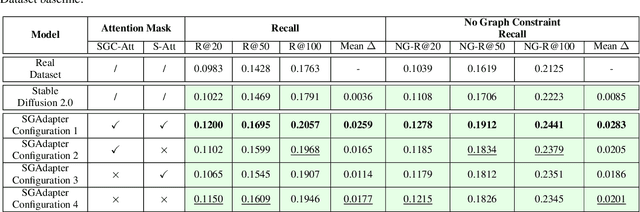

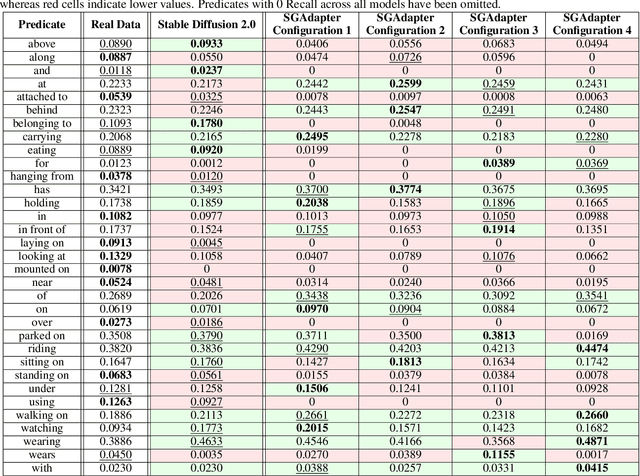
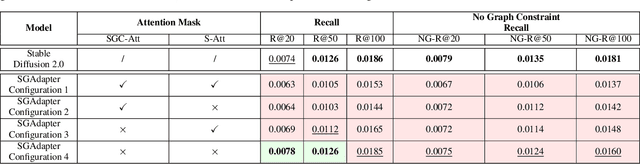
As machine learning models increase in scale and complexity, obtaining sufficient training data has become a critical bottleneck due to acquisition costs, privacy constraints, and data scarcity in specialised domains. While synthetic data generation has emerged as a promising alternative, a notable performance gap remains compared to models trained on real data, particularly as task complexity grows. Concurrently, Neuro-Symbolic methods, which combine neural networks' learning strengths with symbolic reasoning's structured representations, have demonstrated significant potential across various cognitive tasks. This paper explores the utility of Neuro-Symbolic conditioning for synthetic image dataset generation, focusing specifically on improving the performance of Scene Graph Generation models. The research investigates whether structured symbolic representations in the form of scene graphs can enhance synthetic data quality through explicit encoding of relational constraints. The results demonstrate that Neuro-Symbolic conditioning yields significant improvements of up to +2.59% in standard Recall metrics and +2.83% in No Graph Constraint Recall metrics when used for dataset augmentation. These findings establish that merging Neuro-Symbolic and generative approaches produces synthetic data with complementary structural information that enhances model performance when combined with real data, providing a novel approach to overcome data scarcity limitations even for complex visual reasoning tasks.
ZO-DARTS++: An Efficient and Size-Variable Zeroth-Order Neural Architecture Search Algorithm
Mar 08, 2025Differentiable Neural Architecture Search (NAS) provides a promising avenue for automating the complex design of deep learning (DL) models. However, current differentiable NAS methods often face constraints in efficiency, operation selection, and adaptability under varying resource limitations. We introduce ZO-DARTS++, a novel NAS method that effectively balances performance and resource constraints. By integrating a zeroth-order approximation for efficient gradient handling, employing a sparsemax function with temperature annealing for clearer and more interpretable architecture distributions, and adopting a size-variable search scheme for generating compact yet accurate architectures, ZO-DARTS++ establishes a new balance between model complexity and performance. In extensive tests on medical imaging datasets, ZO-DARTS++ improves the average accuracy by up to 1.8\% over standard DARTS-based methods and shortens search time by approximately 38.6\%. Additionally, its resource-constrained variants can reduce the number of parameters by more than 35\% while maintaining competitive accuracy levels. Thus, ZO-DARTS++ offers a versatile and efficient framework for generating high-quality, resource-aware DL models suitable for real-world medical applications.
POMONAG: Pareto-Optimal Many-Objective Neural Architecture Generator
Sep 30, 2024
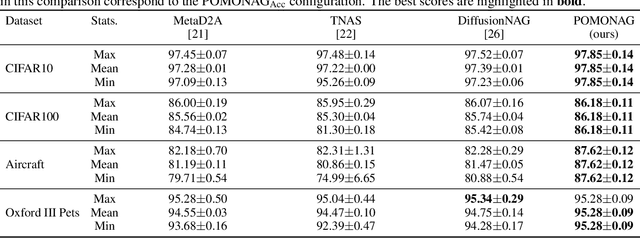


Neural Architecture Search (NAS) automates neural network design, reducing dependence on human expertise. While NAS methods are computationally intensive and dataset-specific, auxiliary predictors reduce the models needing training, decreasing search time. This strategy is used to generate architectures satisfying multiple computational constraints. Recently, Transferable NAS has emerged, generalizing the search process from dataset-dependent to task-dependent. In this field, DiffusionNAG is a state-of-the-art method. This diffusion-based approach streamlines computation, generating architectures optimized for accuracy on unseen datasets without further adaptation. However, by focusing solely on accuracy, DiffusionNAG overlooks other crucial objectives like model complexity, computational efficiency, and inference latency -- factors essential for deploying models in resource-constrained environments. This paper introduces the Pareto-Optimal Many-Objective Neural Architecture Generator (POMONAG), extending DiffusionNAG via a many-objective diffusion process. POMONAG simultaneously considers accuracy, number of parameters, multiply-accumulate operations (MACs), and inference latency. It integrates Performance Predictor models to estimate these metrics and guide diffusion gradients. POMONAG's optimization is enhanced by expanding its training Meta-Dataset, applying Pareto Front Filtering, and refining embeddings for conditional generation. These enhancements enable POMONAG to generate Pareto-optimal architectures that outperform the previous state-of-the-art in performance and efficiency. Results were validated on two search spaces -- NASBench201 and MobileNetV3 -- and evaluated across 15 image classification datasets.
Federated Knowledge Recycling: Privacy-Preserving Synthetic Data Sharing
Jul 30, 2024Federated learning has emerged as a paradigm for collaborative learning, enabling the development of robust models without the need to centralise sensitive data. However, conventional federated learning techniques have privacy and security vulnerabilities due to the exposure of models, parameters or updates, which can be exploited as an attack surface. This paper presents Federated Knowledge Recycling (FedKR), a cross-silo federated learning approach that uses locally generated synthetic data to facilitate collaboration between institutions. FedKR combines advanced data generation techniques with a dynamic aggregation process to provide greater security against privacy attacks than existing methods, significantly reducing the attack surface. Experimental results on generic and medical datasets show that FedKR achieves competitive performance, with an average improvement in accuracy of 4.24% compared to training models from local data, demonstrating particular effectiveness in data scarcity scenarios.
Synthetic Image Learning: Preserving Performance and Preventing Membership Inference Attacks
Jul 22, 2024

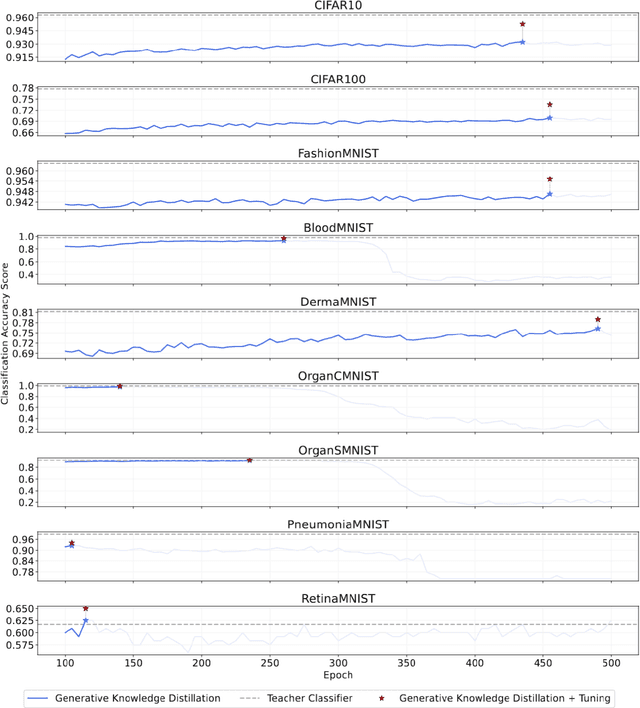

Generative artificial intelligence has transformed the generation of synthetic data, providing innovative solutions to challenges like data scarcity and privacy, which are particularly critical in fields such as medicine. However, the effective use of this synthetic data to train high-performance models remains a significant challenge. This paper addresses this issue by introducing Knowledge Recycling (KR), a pipeline designed to optimise the generation and use of synthetic data for training downstream classifiers. At the heart of this pipeline is Generative Knowledge Distillation (GKD), the proposed technique that significantly improves the quality and usefulness of the information provided to classifiers through a synthetic dataset regeneration and soft labelling mechanism. The KR pipeline has been tested on a variety of datasets, with a focus on six highly heterogeneous medical image datasets, ranging from retinal images to organ scans. The results show a significant reduction in the performance gap between models trained on real and synthetic data, with models based on synthetic data outperforming those trained on real data in some cases. Furthermore, the resulting models show almost complete immunity to Membership Inference Attacks, manifesting privacy properties missing in models trained with conventional techniques.
A Lightweight Neural Architecture Search Model for Medical Image Classification
May 06, 2024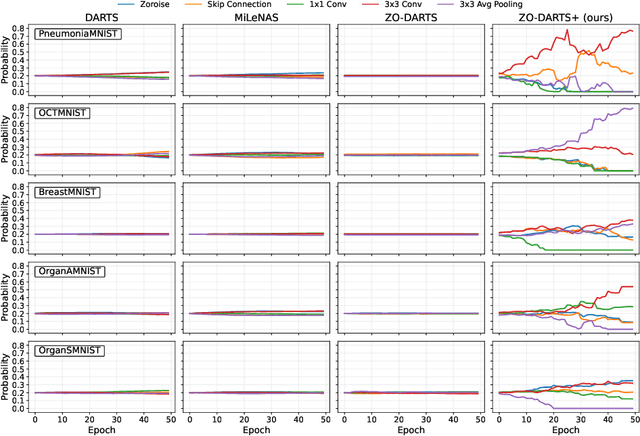

Accurate classification of medical images is essential for modern diagnostics. Deep learning advancements led clinicians to increasingly use sophisticated models to make faster and more accurate decisions, sometimes replacing human judgment. However, model development is costly and repetitive. Neural Architecture Search (NAS) provides solutions by automating the design of deep learning architectures. This paper presents ZO-DARTS+, a differentiable NAS algorithm that improves search efficiency through a novel method of generating sparse probabilities by bi-level optimization. Experiments on five public medical datasets show that ZO-DARTS+ matches the accuracy of state-of-the-art solutions while reducing search times by up to three times.
Stable Diffusion Dataset Generation for Downstream Classification Tasks
May 04, 2024

Recent advances in generative artificial intelligence have enabled the creation of high-quality synthetic data that closely mimics real-world data. This paper explores the adaptation of the Stable Diffusion 2.0 model for generating synthetic datasets, using Transfer Learning, Fine-Tuning and generation parameter optimisation techniques to improve the utility of the dataset for downstream classification tasks. We present a class-conditional version of the model that exploits a Class-Encoder and optimisation of key generation parameters. Our methodology led to synthetic datasets that, in a third of cases, produced models that outperformed those trained on real datasets.