 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Comp: An Automated Pipeline for Scalable Compositional Probing of Contrastive Vision-Language Models
Feb 02, 2026Modern Vision-Language Models (VLMs) exhibit a critical flaw in compositional reasoning, often confusing "a red cube and a blue sphere" with "a blue cube and a red sphere". Disentangling the visual and linguistic roots of these failures is a fundamental challenge for robust evaluation. To enable fine-grained, controllable analysis, we introduce Auto-Comp, a fully automated and synthetic pipeline for generating scalable benchmarks. Its controllable nature is key to dissecting and isolating different reasoning skills. Auto-Comp generates paired images from Minimal (e.g., "a monitor to the left of a bicycle on a white background") and LLM-generated Contextual captions (e.g., "In a brightly lit photography studio, a monitor is positioned to the left of a bicycle"), allowing a controlled A/B test to disentangle core binding ability from visio-linguistic complexity. Our evaluation of 20 VLMs on novel benchmarks for color binding and spatial relations reveals universal compositional failures in both CLIP and SigLIP model families. Crucially, our novel "Confusion Benchmark" reveals a deeper flaw beyond simple attribute swaps: models are highly susceptible to low-entropy distractors (e.g., repeated objects or colors), demonstrating their compositional failures extend beyond known bag-of-words limitations. we uncover a surprising trade-off: visio-linguistic context, which provides global scene cues, aids spatial reasoning but simultaneously hinders local attribute binding by introducing visual clutter. We release the Auto-Comp pipeline to facilitate future benchmark creation, alongside all our generated benchmarks (https://huggingface.co/AutoComp).
PolyGen: Fully Synthetic Vision-Language Training via Multi-Generator Ensembles
Feb 01, 2026Synthetic data offers a scalable solution for vision-language pre-training, yet current state-of-the-art methods typically rely on scaling up a single generative backbone, which introduces generator-specific spectral biases and limits feature diversity. In this work, we introduce PolyGen, a framework that redefines synthetic data construction by prioritizing manifold coverage and compositional rigor over simple dataset size. PolyGen employs a Polylithic approach to train on the intersection of architecturally distinct generators, effectively marginalizing out model-specific artifacts. Additionally, we introduce a Programmatic Hard Negative curriculum that enforces fine-grained syntactic understanding. By structurally reallocating the same data budget from unique captions to multi-source variations, PolyGen achieves a more robust feature space, outperforming the leading single-source baseline (SynthCLIP) by +19.0% on aggregate multi-task benchmarks and on the SugarCrepe++ compositionality benchmark (+9.1%). These results demonstrate that structural diversity is a more data-efficient scaling law than simply increasing the volume of single-source samples.
SCENEFORGE: Enhancing 3D-text alignment with Structured Scene Compositions
Sep 19, 2025The whole is greater than the sum of its parts-even in 3D-text contrastive learning. We introduce SceneForge, a novel framework that enhances contrastive alignment between 3D point clouds and text through structured multi-object scene compositions. SceneForge leverages individual 3D shapes to construct multi-object scenes with explicit spatial relations, pairing them with coherent multi-object descriptions refined by a large language model. By augmenting contrastive training with these structured, compositional samples, SceneForge effectively addresses the scarcity of large-scale 3D-text datasets, significantly enriching data complexity and diversity. We systematically investigate critical design elements, such as the optimal number of objects per scene, the proportion of compositional samples in training batches, and scene construction strategies. Extensive experiments demonstrate that SceneForge delivers substantial performance gains across multiple tasks, including zero-shot classification on ModelNet, ScanObjNN, Objaverse-LVIS, and ScanNet, as well as few-shot part segmentation on ShapeNetPart. SceneForge's compositional augmentations are model-agnostic, consistently improving performance across multiple encoder architectures. Moreover, SceneForge improves 3D visual question answering on ScanQA, generalizes robustly to retrieval scenarios with increasing scene complexity, and showcases spatial reasoning capabilities by adapting spatial configurations to align precisely with textual instructions.
Your Image Generator Is Your New Private Dataset
Apr 08, 2025
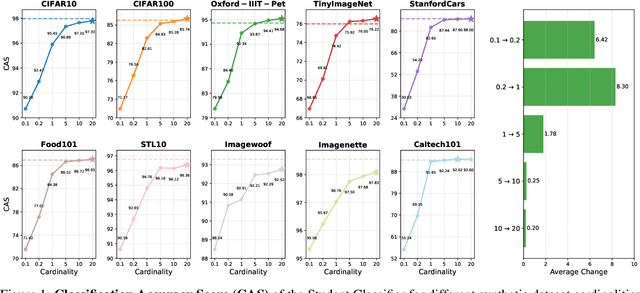
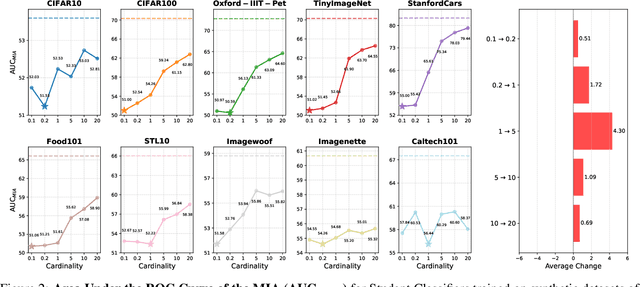
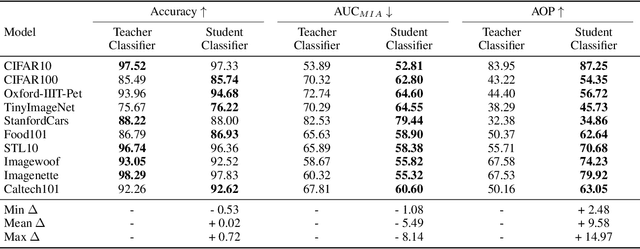
Generative diffusion models have emerged as powerful tools to synthetically produce training data, offering potential solutions to data scarcity and reducing labelling costs for downstream supervised deep learning applications. However, effectively leveraging text-conditioned image generation for building classifier training sets requires addressing key issues: constructing informative textual prompts, adapting generative models to specific domains, and ensuring robust performance. This paper proposes the Text-Conditioned Knowledge Recycling (TCKR) pipeline to tackle these challenges. TCKR combines dynamic image captioning, parameter-efficient diffusion model fine-tuning, and Generative Knowledge Distillation techniques to create synthetic datasets tailored for image classification. The pipeline is rigorously evaluated on ten diverse image classification benchmarks. The results demonstrate that models trained solely on TCKR-generated data achieve classification accuracies on par with (and in several cases exceeding) models trained on real images. Furthermore, the evaluation reveals that these synthetic-data-trained models exhibit substantially enhanced privacy characteristics: their vulnerability to Membership Inference Attacks is significantly reduced, with the membership inference AUC lowered by 5.49 points on average compared to using real training data, demonstrating a substantial improvement in the performance-privacy trade-off. These findings indicate that high-fidelity synthetic data can effectively replace real data for training classifiers, yielding strong performance whilst simultaneously providing improved privacy protection as a valuable emergent property. The code and trained models are available in the accompanying open-source repository.
Neuro-Symbolic Scene Graph Conditioning for Synthetic Image Dataset Generation
Mar 21, 2025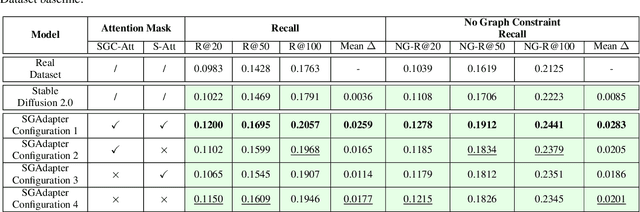

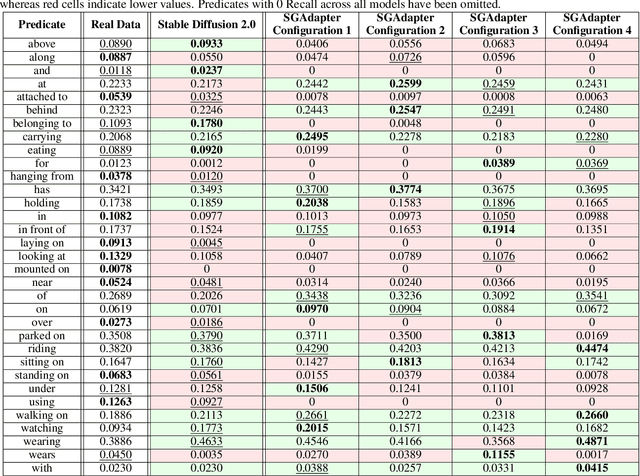
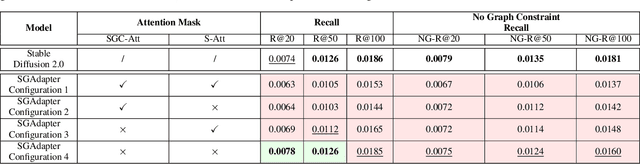
As machine learning models increase in scale and complexity, obtaining sufficient training data has become a critical bottleneck due to acquisition costs, privacy constraints, and data scarcity in specialised domains. While synthetic data generation has emerged as a promising alternative, a notable performance gap remains compared to models trained on real data, particularly as task complexity grows. Concurrently, Neuro-Symbolic methods, which combine neural networks' learning strengths with symbolic reasoning's structured representations, have demonstrated significant potential across various cognitive tasks. This paper explores the utility of Neuro-Symbolic conditioning for synthetic image dataset generation, focusing specifically on improving the performance of Scene Graph Generation models. The research investigates whether structured symbolic representations in the form of scene graphs can enhance synthetic data quality through explicit encoding of relational constraints. The results demonstrate that Neuro-Symbolic conditioning yields significant improvements of up to +2.59% in standard Recall metrics and +2.83% in No Graph Constraint Recall metrics when used for dataset augmentation. These findings establish that merging Neuro-Symbolic and generative approaches produces synthetic data with complementary structural information that enhances model performance when combined with real data, providing a novel approach to overcome data scarcity limitations even for complex visual reasoning tasks.
Can CLIP help CLIP in learning 3D?
Jun 04, 2024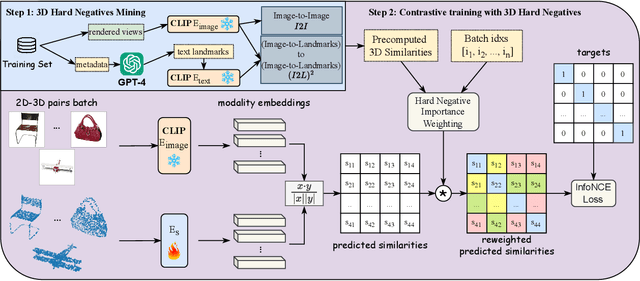
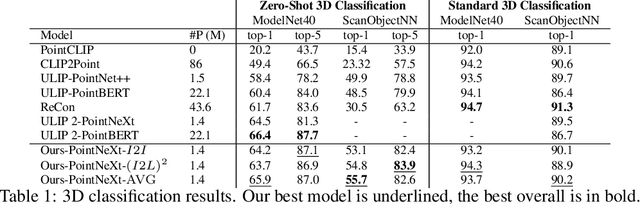
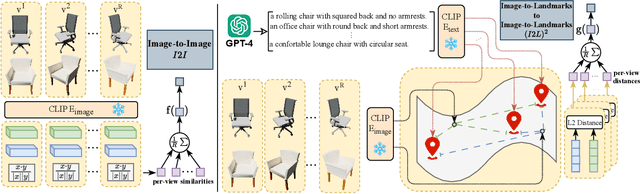
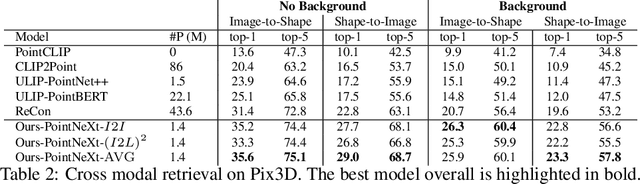
In this study, we explore an alternative approach to enhance contrastive text-image-3D alignment in the absence of textual descriptions for 3D objects. We introduce two unsupervised methods, $I2I$ and $(I2L)^2$, which leverage CLIP knowledge about textual and 2D data to compute the neural perceived similarity between two 3D samples. We employ the proposed methods to mine 3D hard negatives, establishing a multimodal contrastive pipeline with hard negative weighting via a custom loss function. We train on different configurations of the proposed hard negative mining approach, and we evaluate the accuracy of our models in 3D classification and on the cross-modal retrieval benchmark, testing image-to-shape and shape-to-image retrieval. Results demonstrate that our approach, even without explicit text alignment, achieves comparable or superior performance on zero-shot and standard 3D classification, while significantly improving both image-to-shape and shape-to-image retrieval compared to previous methods.
Can Shape-Infused Joint Embeddings Improve Image-Conditioned 3D Diffusion?
Feb 02, 2024Recent advancements in deep generative models, particularly with the application of CLIP (Contrastive Language Image Pretraining) to Denoising Diffusion Probabilistic Models (DDPMs), have demonstrated remarkable effectiveness in text to image generation. The well structured embedding space of CLIP has also been extended to image to shape generation with DDPMs, yielding notable results. Despite these successes, some fundamental questions arise: Does CLIP ensure the best results in shape generation from images? Can we leverage conditioning to bring explicit 3D knowledge into the generative process and obtain better quality? This study introduces CISP (Contrastive Image Shape Pre training), designed to enhance 3D shape synthesis guided by 2D images. CISP aims to enrich the CLIP framework by aligning 2D images with 3D shapes in a shared embedding space, specifically capturing 3D characteristics potentially overlooked by CLIP's text image focus. Our comprehensive analysis assesses CISP's guidance performance against CLIP guided models, focusing on generation quality, diversity, and coherence of the produced shapes with the conditioning image. We find that, while matching CLIP in generation quality and diversity, CISP substantially improves coherence with input images, underscoring the value of incorporating 3D knowledge into generative models. These findings suggest a promising direction for advancing the synthesis of 3D visual content by integrating multimodal systems with 3D representations.
IC3D: Image-Conditioned 3D Diffusion for Shape Generation
Nov 20, 2022



In the last years, Denoising Diffusion Probabilistic Models (DDPMs) obtained state-of-the-art results in many generative tasks, outperforming GANs and other classes of generative models. In particular, they reached impressive results in various image generation sub-tasks, among which conditional generation tasks such as text-guided image synthesis. Given the success of DDPMs in 2D generation, they have more recently been applied to 3D shape generation, outperforming previous approaches and reaching state-of-the-art results. However, 3D data pose additional challenges, such as the choice of the 3D representation, which impacts design choices and model efficiency. While reaching state-of-the-art results in generation quality, existing 3D DDPM works make little or no use of guidance, mainly being unconditional or class-conditional. In this paper, we present IC3D, the first Image-Conditioned 3D Diffusion model that generates 3D shapes by image guidance. It is also the first 3D DDPM model that adopts voxels as a 3D representation. To guide our DDPM, we present and leverage CISP (Contrastive Image-Shape Pre-training), a model jointly embedding images and shapes by contrastive pre-training, inspired by text-to-image DDPM works. Our generative diffusion model outperforms the state-of-the-art in 3D generation quality and diversity. Furthermore, we show that our generated shapes are preferred by human evaluators to a SoTA single-view 3D reconstruction model in terms of quality and coherence to the query image by running a side-by-side human evaluation.