 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Empirical Impact of Forgetting and Transfer in Continual Visual Odometry
Jun 03, 2024As robotics continues to advance, the need for adaptive and continuously-learning embodied agents increases, particularly in the realm of assistance robotics. Quick adaptability and long-term information retention are essential to operate in dynamic environments typical of humans' everyday lives. A lifelong learning paradigm is thus required, but it is scarcely addressed by current robotics literature. This study empirically investigates the impact of catastrophic forgetting and the effectiveness of knowledge transfer in neural networks trained continuously in an embodied setting. We focus on the task of visual odometry, which holds primary importance for embodied agents in enabling their self-localization. We experiment on the simple continual scenario of discrete transitions between indoor locations, akin to a robot navigating different apartments. In this regime, we observe initial satisfactory performance with high transferability between environments, followed by a specialization phase where the model prioritizes current environment-specific knowledge at the expense of generalization. Conventional regularization strategies and increased model capacity prove ineffective in mitigating this phenomenon. Rehearsal is instead mildly beneficial but with the addition of a substantial memory cost. Incorporating action information, as commonly done in embodied settings, facilitates quicker convergence but exacerbates specialization, making the model overly reliant on its motion expectations and less adept at correctly interpreting visual cues. These findings emphasize the open challenges of balancing adaptation and memory retention in lifelong robotics and contribute valuable insights into the application of a lifelong paradigm on embodied agents.
Can Shape-Infused Joint Embeddings Improve Image-Conditioned 3D Diffusion?
Feb 02, 2024Recent advancements in deep generative models, particularly with the application of CLIP (Contrastive Language Image Pretraining) to Denoising Diffusion Probabilistic Models (DDPMs), have demonstrated remarkable effectiveness in text to image generation. The well structured embedding space of CLIP has also been extended to image to shape generation with DDPMs, yielding notable results. Despite these successes, some fundamental questions arise: Does CLIP ensure the best results in shape generation from images? Can we leverage conditioning to bring explicit 3D knowledge into the generative process and obtain better quality? This study introduces CISP (Contrastive Image Shape Pre training), designed to enhance 3D shape synthesis guided by 2D images. CISP aims to enrich the CLIP framework by aligning 2D images with 3D shapes in a shared embedding space, specifically capturing 3D characteristics potentially overlooked by CLIP's text image focus. Our comprehensive analysis assesses CISP's guidance performance against CLIP guided models, focusing on generation quality, diversity, and coherence of the produced shapes with the conditioning image. We find that, while matching CLIP in generation quality and diversity, CISP substantially improves coherence with input images, underscoring the value of incorporating 3D knowledge into generative models. These findings suggest a promising direction for advancing the synthesis of 3D visual content by integrating multimodal systems with 3D representations.
RadarLCD: Learnable Radar-based Loop Closure Detection Pipeline
Sep 13, 2023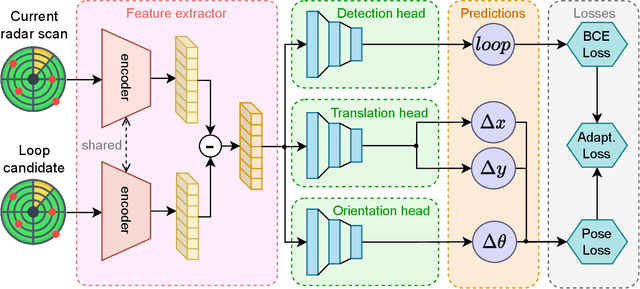
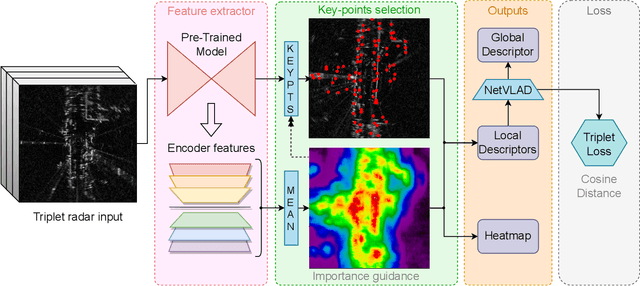
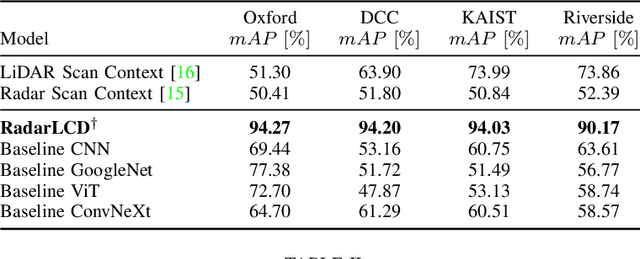
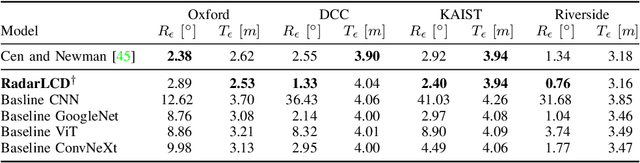
Loop Closure Detection (LCD) is an essential task in robotics and computer vision, serving as a fundamental component for various applications across diverse domains. These applications encompass object recognition, image retrieval, and video analysis. LCD consists in identifying whether a robot has returned to a previously visited location, referred to as a loop, and then estimating the related roto-translation with respect to the analyzed location. Despite the numerous advantages of radar sensors, such as their ability to operate under diverse weather conditions and provide a wider range of view compared to other commonly used sensors (e.g., cameras or LiDARs), integrating radar data remains an arduous task due to intrinsic noise and distortion. To address this challenge, this research introduces RadarLCD, a novel supervised deep learning pipeline specifically designed for Loop Closure Detection using the FMCW Radar (Frequency Modulated Continuous Wave) sensor. RadarLCD, a learning-based LCD methodology explicitly designed for radar systems, makes a significant contribution by leveraging the pre-trained HERO (Hybrid Estimation Radar Odometry) model. Being originally developed for radar odometry, HERO's features are used to select key points crucial for LCD tasks. The methodology undergoes evaluation across a variety of FMCW Radar dataset scenes, and it is compared to state-of-the-art systems such as Scan Context for Place Recognition and ICP for Loop Closure. The results demonstrate that RadarLCD surpasses the alternatives in multiple aspects of Loop Closure Detection.
Continual Cross-Dataset Adaptation in Road Surface Classification
Sep 05, 2023


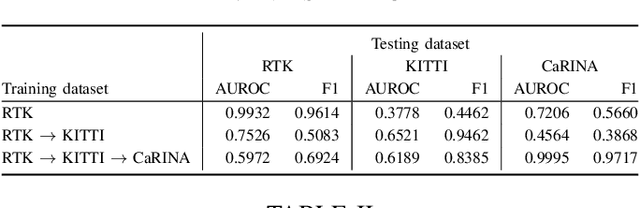
Accurate road surface classification is crucial for autonomous vehicles (AVs) to optimize driving conditions, enhance safety, and enable advanced road mapping. However, deep learning models for road surface classification suffer from poor generalization when tested on unseen datasets. To update these models with new information, also the original training dataset must be taken into account, in order to avoid catastrophic forgetting. This is, however, inefficient if not impossible, e.g., when the data is collected in streams or large amounts. To overcome this limitation and enable fast and efficient cross-dataset adaptation, we propose to employ continual learning finetuning methods designed to retain past knowledge while adapting to new data, thus effectively avoiding forgetting. Experimental results demonstrate the superiority of this approach over naive finetuning, achieving performance close to fresh retraining. While solving this known problem, we also provide a general description of how the same technique can be adopted in other AV scenarios. We highlight the potential computational and economic benefits that a continual-based adaptation can bring to the AV industry, while also reducing greenhouse emissions due to unnecessary joint retraining.
IC3D: Image-Conditioned 3D Diffusion for Shape Generation
Nov 20, 2022



In the last years, Denoising Diffusion Probabilistic Models (DDPMs) obtained state-of-the-art results in many generative tasks, outperforming GANs and other classes of generative models. In particular, they reached impressive results in various image generation sub-tasks, among which conditional generation tasks such as text-guided image synthesis. Given the success of DDPMs in 2D generation, they have more recently been applied to 3D shape generation, outperforming previous approaches and reaching state-of-the-art results. However, 3D data pose additional challenges, such as the choice of the 3D representation, which impacts design choices and model efficiency. While reaching state-of-the-art results in generation quality, existing 3D DDPM works make little or no use of guidance, mainly being unconditional or class-conditional. In this paper, we present IC3D, the first Image-Conditioned 3D Diffusion model that generates 3D shapes by image guidance. It is also the first 3D DDPM model that adopts voxels as a 3D representation. To guide our DDPM, we present and leverage CISP (Contrastive Image-Shape Pre-training), a model jointly embedding images and shapes by contrastive pre-training, inspired by text-to-image DDPM works. Our generative diffusion model outperforms the state-of-the-art in 3D generation quality and diversity. Furthermore, we show that our generated shapes are preferred by human evaluators to a SoTA single-view 3D reconstruction model in terms of quality and coherence to the query image by running a side-by-side human evaluation.
Advances in centerline estimation for autonomous lateral control
Feb 28, 2020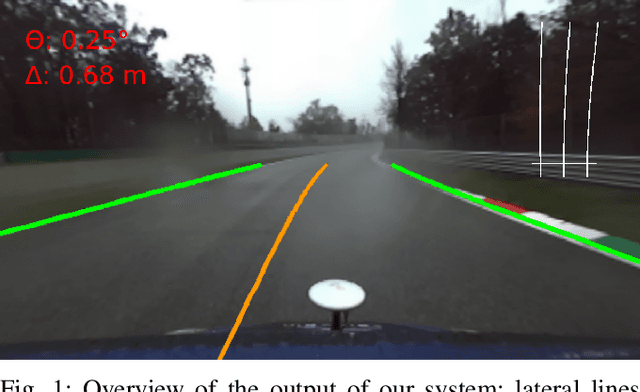
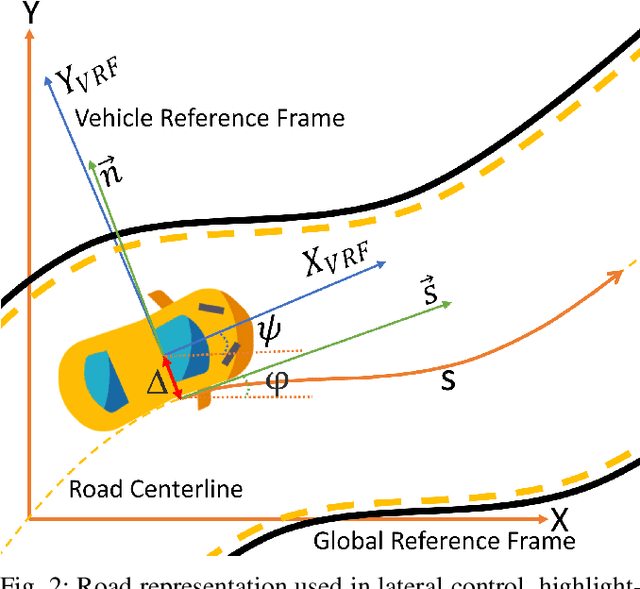

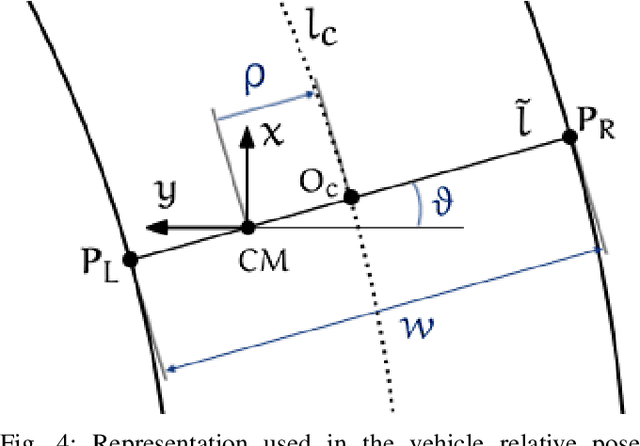
The ability of autonomous vehicles to maintain an accurate trajectory within their road lane is crucial for safe operation. This requires detecting the road lines and estimating the car relative pose within its lane. Lateral lines are usually computed from camera images. Still, most of the works on line detection are limited to image mask retrieval and do not provide a usable representation in world coordinates. What we propose in this paper is a complete perception pipeline able to retrieve, from a single image, all the information required by a vehicle lateral control system: road lines equation, centerline, vehicle heading and lateral displacement. We also evaluate our system by acquiring a new dataset with accurate geometric ground truth, and we make it publicly available to act as a benchmark for further research.