 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGR-OCC: Evolving Monocular Priors for Embodied 3D Occupancy Prediction via Soft-Gating Lifting and Semantic-Adaptive Geometric Refinement
Mar 14, 20263D semantic occupancy prediction is a cornerstone for embodied AI, enabling agents to perceive dense scene geometry and semantics incrementally from monocular video streams. However, current online frameworks face two critical bottlenecks: the inherent depth ambiguity of monocular estimation that causes "feature bleeding" at object boundaries , and the "cold start" instability where uninitialized temporal fusion layers distort high-quality spatial priors during early training stages. In this paper, we propose SGR-OCC (Soft-Gating and Ray-refinement Occupancy), a unified framework driven by the philosophy of "Inheritance and Evolution". To perfectly inherit monocular spatial expertise, we introduce a Soft-Gating Feature Lifter that explicitly models depth uncertainty via a Gaussian gate to probabilistically suppress background noise. Furthermore, a Dynamic Ray-Constrained Anchor Refinement module simplifies complex 3D displacement searches into efficient 1D depth corrections along camera rays, ensuring sub-voxel adherence to physical surfaces. To ensure stable evolution toward temporal consistency, we employ a Two-Phase Progressive Training Strategy equipped with identity-initialized fusion, effectively resolving the cold start problem and shielding spatial priors from noisy early gradients. Extensive experiments on the EmbodiedOcc-ScanNet and Occ-ScanNet benchmarks demonstrate that SGR-OCC achieves state-of-the-art performance. In local prediction tasks, SGR-OCC achieves a completion IoU of 58.55$\%$ and a semantic mIoU of 49.89$\%$, surpassing the previous best method, EmbodiedOcc++, by 3.65$\%$ and 3.69$\%$ respectively. In challenging embodied prediction tasks, our model reaches 55.72$\%$ SC-IoU and 46.22$\%$ mIoU. Qualitative results further confirm our model's superior capability in preserving structural integrity and boundary sharpness in complex indoor environments.
EETnet: a CNN for Gaze Detection and Tracking for Smart-Eyewear
Nov 06, 2025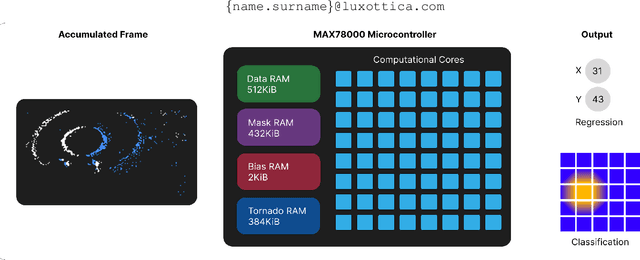
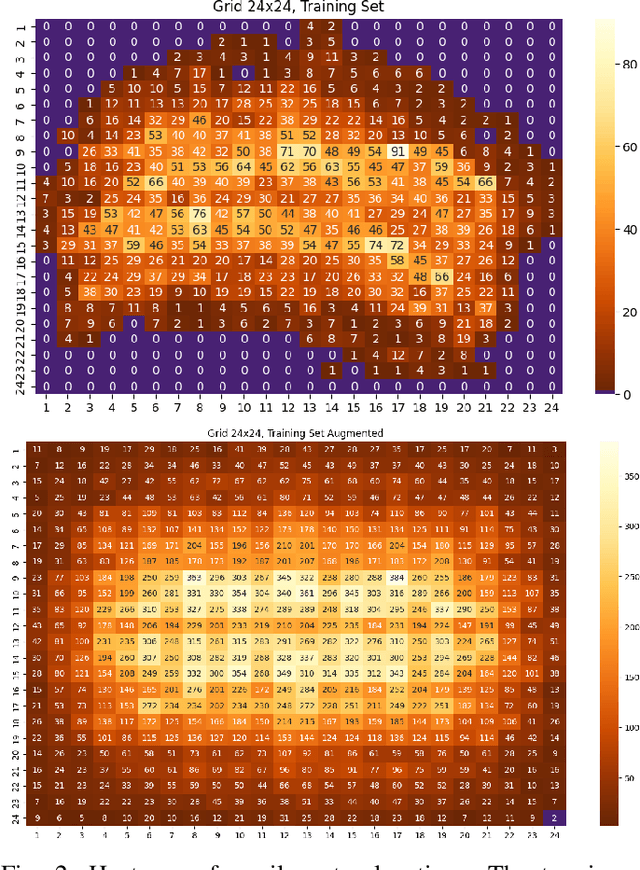

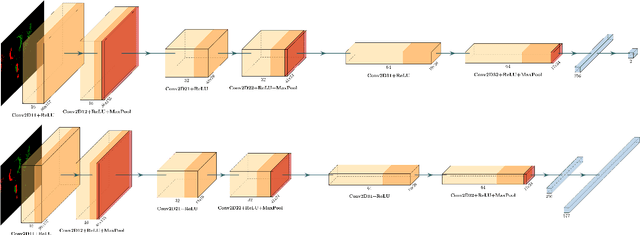
Event-based cameras are becoming a popular solution for efficient, low-power eye tracking. Due to the sparse and asynchronous nature of event data, they require less processing power and offer latencies in the microsecond range. However, many existing solutions are limited to validation on powerful GPUs, with no deployment on real embedded devices. In this paper, we present EETnet, a convolutional neural network designed for eye tracking using purely event-based data, capable of running on microcontrollers with limited resources. Additionally, we outline a methodology to train, evaluate, and quantize the network using a public dataset. Finally, we propose two versions of the architecture: a classification model that detects the pupil on a grid superimposed on the original image, and a regression model that operates at the pixel level.
From Pixels to Graphs: using Scene and Knowledge Graphs for HD-EPIC VQA Challenge
Jun 10, 2025



This report presents SceneNet and KnowledgeNet, our approaches developed for the HD-EPIC VQA Challenge 2025. SceneNet leverages scene graphs generated with a multi-modal large language model (MLLM) to capture fine-grained object interactions, spatial relationships, and temporally grounded events. In parallel, KnowledgeNet incorporates ConceptNet's external commonsense knowledge to introduce high-level semantic connections between entities, enabling reasoning beyond directly observable visual evidence. Each method demonstrates distinct strengths across the seven categories of the HD-EPIC benchmark, and their combination within our framework results in an overall accuracy of 44.21% on the challenge, highlighting its effectiveness for complex egocentric VQA tasks.
High-frequency near-eye ground truth for event-based eye tracking
Feb 05, 2025



Event-based eye tracking is a promising solution for efficient and low-power eye tracking in smart eyewear technologies. However, the novelty of event-based sensors has resulted in a limited number of available datasets, particularly those with eye-level annotations, crucial for algorithm validation and deep-learning training. This paper addresses this gap by presenting an improved version of a popular event-based eye-tracking dataset. We introduce a semi-automatic annotation pipeline specifically designed for event-based data annotation. Additionally, we provide the scientific community with the computed annotations for pupil detection at 200Hz.
RadarLCD: Learnable Radar-based Loop Closure Detection Pipeline
Sep 13, 2023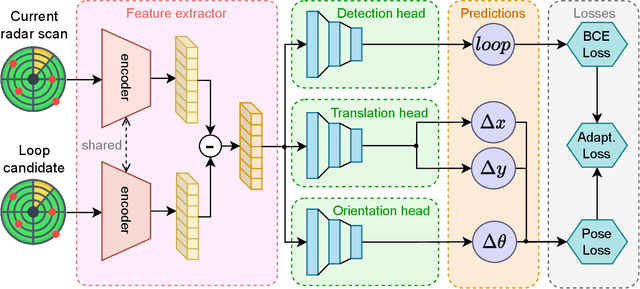
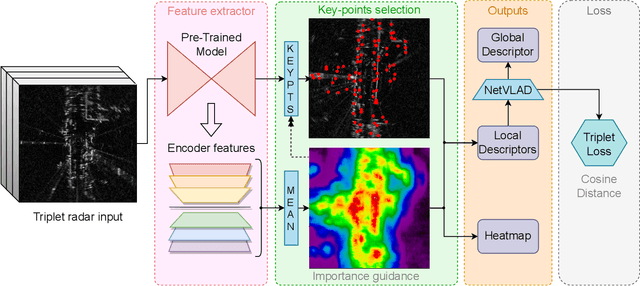
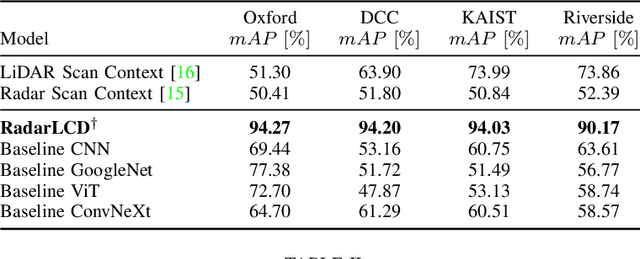
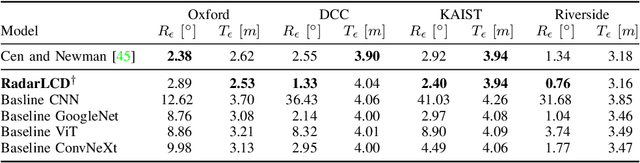
Loop Closure Detection (LCD) is an essential task in robotics and computer vision, serving as a fundamental component for various applications across diverse domains. These applications encompass object recognition, image retrieval, and video analysis. LCD consists in identifying whether a robot has returned to a previously visited location, referred to as a loop, and then estimating the related roto-translation with respect to the analyzed location. Despite the numerous advantages of radar sensors, such as their ability to operate under diverse weather conditions and provide a wider range of view compared to other commonly used sensors (e.g., cameras or LiDARs), integrating radar data remains an arduous task due to intrinsic noise and distortion. To address this challenge, this research introduces RadarLCD, a novel supervised deep learning pipeline specifically designed for Loop Closure Detection using the FMCW Radar (Frequency Modulated Continuous Wave) sensor. RadarLCD, a learning-based LCD methodology explicitly designed for radar systems, makes a significant contribution by leveraging the pre-trained HERO (Hybrid Estimation Radar Odometry) model. Being originally developed for radar odometry, HERO's features are used to select key points crucial for LCD tasks. The methodology undergoes evaluation across a variety of FMCW Radar dataset scenes, and it is compared to state-of-the-art systems such as Scan Context for Place Recognition and ICP for Loop Closure. The results demonstrate that RadarLCD surpasses the alternatives in multiple aspects of Loop Closure Detection.
Extended Object Tracking in Curvilinear Road Coordinates for Autonomous Driving
Feb 08, 2022
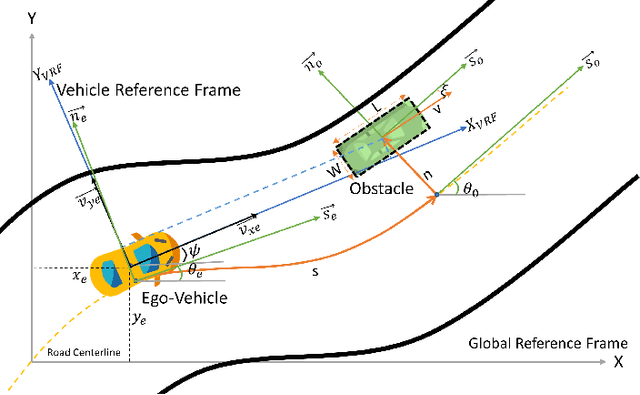
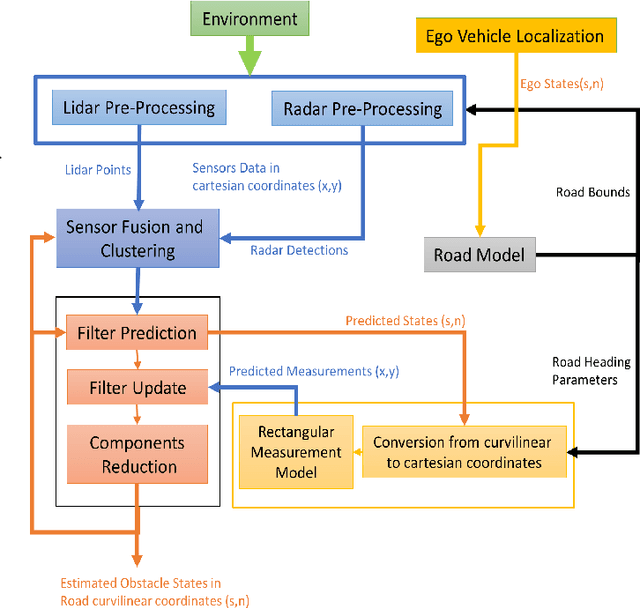
In literature, Extended Object Tracking (EOT) algorithms developed for autonomous driving predominantly provide obstacles state estimation in cartesian coordinates in the Vehicle Reference Frame. However, in many scenarios, state representation in road-aligned curvilinear coordinates is preferred when implementing autonomous driving subsystems like cruise control, lane-keeping assist, platooning, etc. This paper proposes a Gaussian Mixture Probability Hypothesis Density~(GM-PHD) filter with an Unscented Kalman Filter~(UKF) estimator that provides obstacle state estimates in curvilinear road coordinates. We employ a hybrid sensor fusion architecture between Lidar and Radar sensors to obtain rich measurement point representations for EOT. The measurement model for the UKF estimator is developed with the integration of coordinate conversion from curvilinear road coordinates to cartesian coordinates by using cubic hermit spline road model. The proposed algorithm is validated through Matlab Driving Scenario Designer simulation and experimental data collected at Monza Eni Circuit.
Two algorithms for vehicular obstacle detection in sparse pointcloud
Sep 15, 2021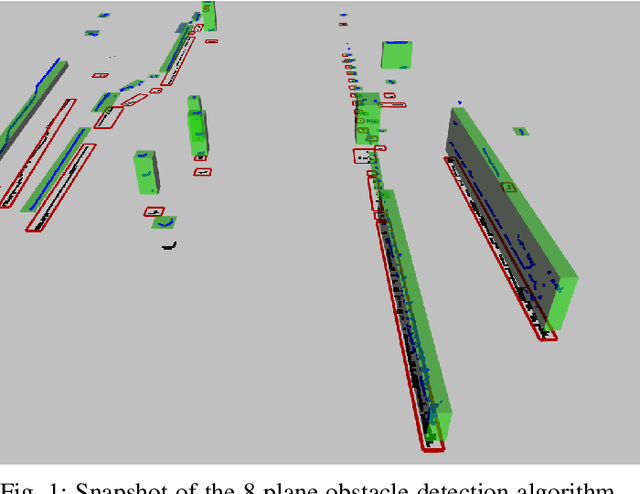


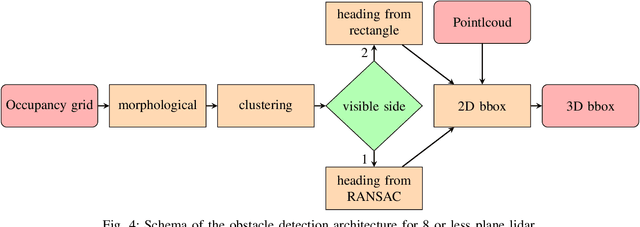
One of the main components of an autonomous vehicle is the obstacle detection pipeline. Most prototypes, both from research and industry, rely on lidars for this task. Pointcloud information from lidar is usually combined with data from cameras and radars, but the backbone of the architecture is mainly based on 3D bounding boxes computed from lidar data. To retrieve an accurate representation, sensors with many planes, e.g., greater than 32 planes, are usually employed. The returned pointcloud is indeed dense and well defined, but high-resolution sensors are still expensive and often require powerful GPUs to be processed. Lidars with fewer planes are cheaper, but the returned data are not dense enough to be processed with state of the art deep learning approaches to retrieve 3D bounding boxes. In this paper, we propose two solutions based on occupancy grid and geometric refinement to retrieve a list of 3D bounding boxes employing lidar with a low number of planes (i.e., 16 and 8 planes). Our solutions have been validated on a custom acquired dataset with accurate ground truth to prove its feasibility and accuracy.
Design of a prototypical platform for autonomous and connected vehicles
Jun 17, 2021

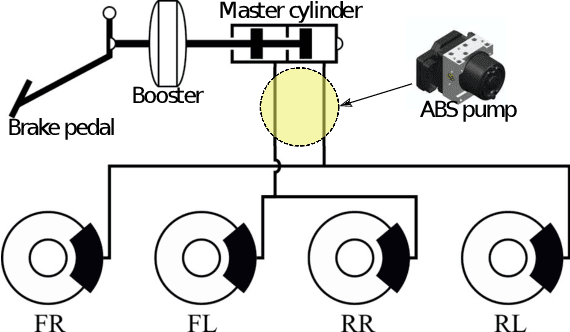

Self-driving technology is expected to revolutionize different sectors and is seen as the natural evolution of road vehicles. In the last years, real-world validation of designed and virtually tested solutions is growing in importance since simulated environments will never fully replicate all the aspects that can affect results in the real world. To this end, this paper presents our prototype platform for experimental research on connected and autonomous driving projects. In detail, the paper presents the overall architecture of the vehicle focusing both on mechanical aspects related to remote actuation and sensors set-up and software aspects by means of a comprehensive description of the main algorithms required for autonomous driving as ego-localization, environment perception, motion planning, and actuation. Finally, experimental tests conducted in an urban-like environment are reported to validate and assess the performances of the overall system.
LiDAR point-cloud processing based on projection methods: a comparison
Aug 03, 2020
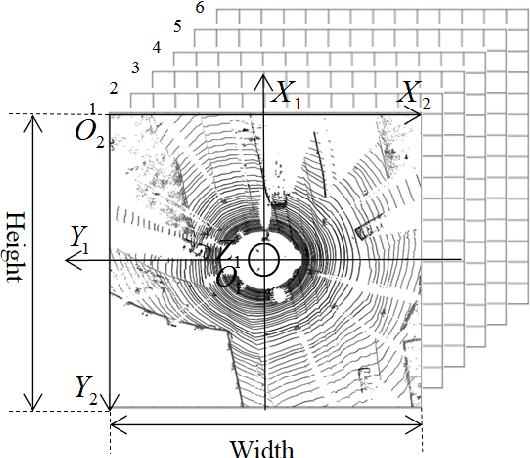
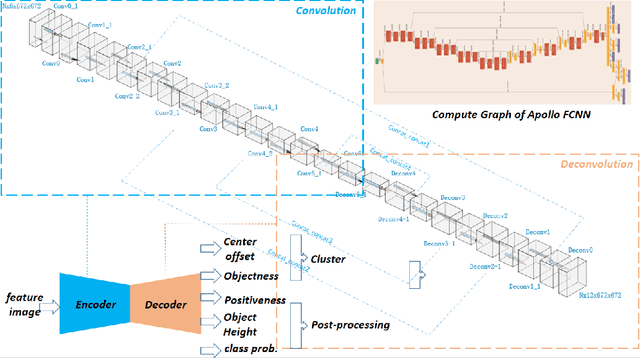
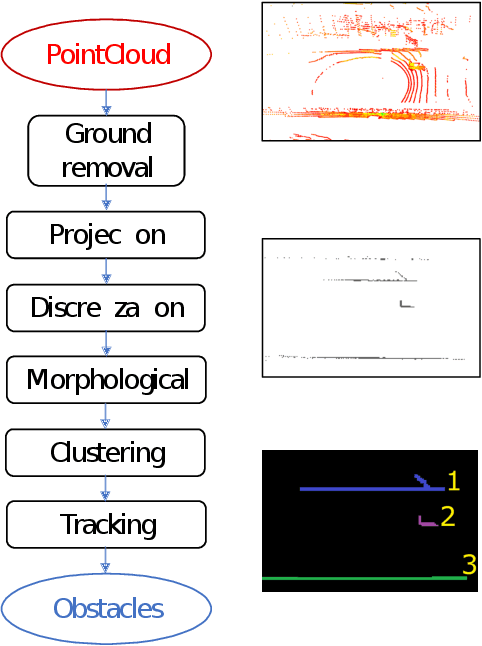
An accurate and rapid-response perception system is fundamental for autonomous vehicles to operate safely. 3D object detection methods handle point clouds given by LiDAR sensors to provide accurate depth and position information for each detection, together with its dimensions and classification. The information is then used to track vehicles and other obstacles in the surroundings of the autonomous vehicle, and also to feed control units that guarantee collision avoidance and motion planning. Nowadays, object detection systems can be divided into two main categories. The first ones are the geometric based, which retrieve the obstacles using geometric and morphological operations on the 3D points. The seconds are the deep learning-based, which process the 3D points, or an elaboration of the 3D point-cloud, with deep learning techniques to retrieve a set of obstacles. This paper presents a comparison between those two approaches, presenting one implementation of each class on a real autonomous vehicle. Accuracy of the estimates of the algorithms has been evaluated with experimental tests carried in the Monza ENI circuit. The position of the ego vehicle and the obstacle is given by GPS sensors with RTK correction, which guarantees an accurate ground truth for the comparison. Both algorithms have been implemented on ROS and run on a consumer laptop.
Advances in centerline estimation for autonomous lateral control
Feb 28, 2020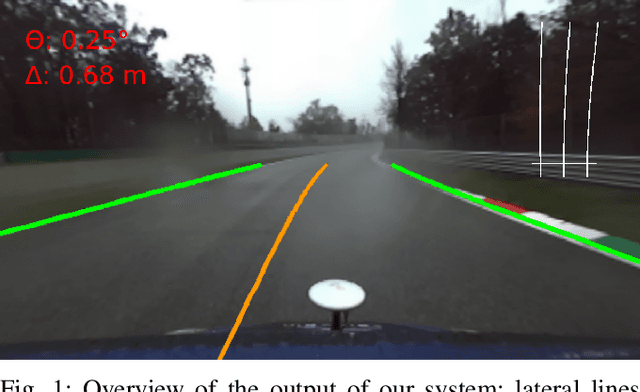
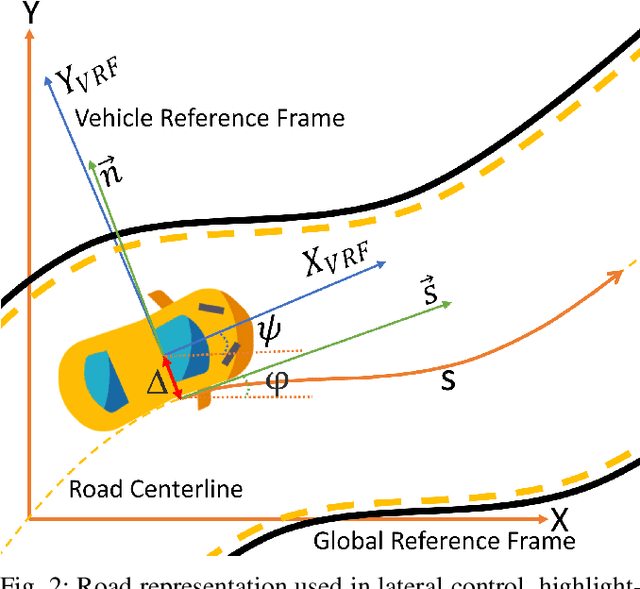

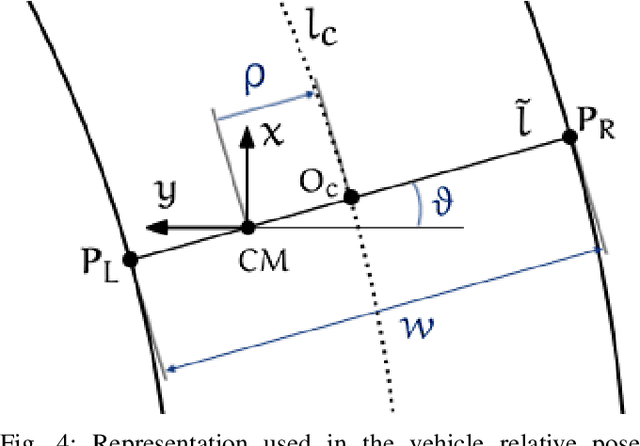
The ability of autonomous vehicles to maintain an accurate trajectory within their road lane is crucial for safe operation. This requires detecting the road lines and estimating the car relative pose within its lane. Lateral lines are usually computed from camera images. Still, most of the works on line detection are limited to image mask retrieval and do not provide a usable representation in world coordinates. What we propose in this paper is a complete perception pipeline able to retrieve, from a single image, all the information required by a vehicle lateral control system: road lines equation, centerline, vehicle heading and lateral displacement. We also evaluate our system by acquiring a new dataset with accurate geometric ground truth, and we make it publicly available to act as a benchmark for further research.