 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Image Learning: Preserving Performance and Preventing Membership Inference Attacks
Paper and Code
Jul 22, 2024

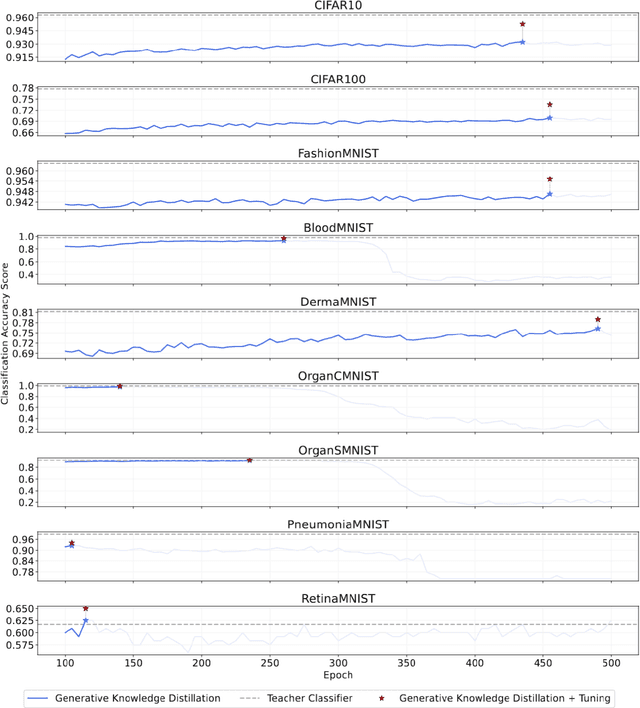

Generative artificial intelligence has transformed the generation of synthetic data, providing innovative solutions to challenges like data scarcity and privacy, which are particularly critical in fields such as medicine. However, the effective use of this synthetic data to train high-performance models remains a significant challenge. This paper addresses this issue by introducing Knowledge Recycling (KR), a pipeline designed to optimise the generation and use of synthetic data for training downstream classifiers. At the heart of this pipeline is Generative Knowledge Distillation (GKD), the proposed technique that significantly improves the quality and usefulness of the information provided to classifiers through a synthetic dataset regeneration and soft labelling mechanism. The KR pipeline has been tested on a variety of datasets, with a focus on six highly heterogeneous medical image datasets, ranging from retinal images to organ scans. The results show a significant reduction in the performance gap between models trained on real and synthetic data, with models based on synthetic data outperforming those trained on real data in some cases. Furthermore, the resulting models show almost complete immunity to Membership Inference Attacks, manifesting privacy properties missing in models trained with conventional techniques.