 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Reinforcement Learning for Runtime Optimization of AI Applications in Smart Eyewears
Aug 24, 2025Extended reality technologies are transforming fields such as healthcare, entertainment, and education, with Smart Eye-Wears (SEWs) and Artificial Intelligence (AI) playing a crucial role. However, SEWs face inherent limitations in computational power, memory, and battery life, while offloading computations to external servers is constrained by network conditions and server workload variability. To address these challenges, we propose a Federated Reinforcement Learning (FRL) framework, enabling multiple agents to train collaboratively while preserving data privacy. We implemented synchronous and asynchronous federation strategies, where models are aggregated either at fixed intervals or dynamically based on agent progress. Experimental results show that federated agents exhibit significantly lower performance variability, ensuring greater stability and reliability. These findings underscore the potential of FRL for applications requiring robust real-time AI processing, such as real-time object detection in SEWs.
ZO-DARTS++: An Efficient and Size-Variable Zeroth-Order Neural Architecture Search Algorithm
Mar 08, 2025Differentiable Neural Architecture Search (NAS) provides a promising avenue for automating the complex design of deep learning (DL) models. However, current differentiable NAS methods often face constraints in efficiency, operation selection, and adaptability under varying resource limitations. We introduce ZO-DARTS++, a novel NAS method that effectively balances performance and resource constraints. By integrating a zeroth-order approximation for efficient gradient handling, employing a sparsemax function with temperature annealing for clearer and more interpretable architecture distributions, and adopting a size-variable search scheme for generating compact yet accurate architectures, ZO-DARTS++ establishes a new balance between model complexity and performance. In extensive tests on medical imaging datasets, ZO-DARTS++ improves the average accuracy by up to 1.8\% over standard DARTS-based methods and shortens search time by approximately 38.6\%. Additionally, its resource-constrained variants can reduce the number of parameters by more than 35\% while maintaining competitive accuracy levels. Thus, ZO-DARTS++ offers a versatile and efficient framework for generating high-quality, resource-aware DL models suitable for real-world medical applications.
A Lightweight Neural Architecture Search Model for Medical Image Classification
May 06, 2024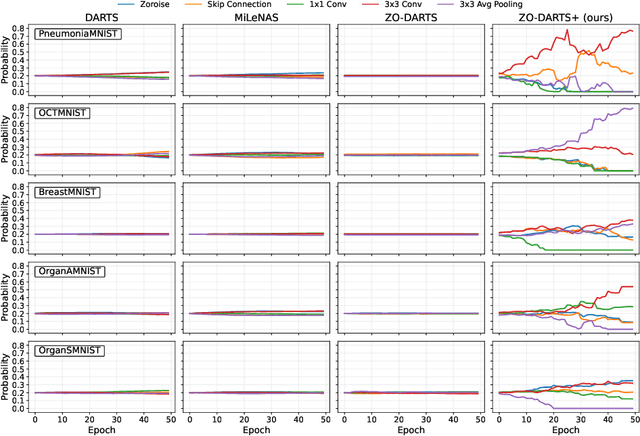

Accurate classification of medical images is essential for modern diagnostics. Deep learning advancements led clinicians to increasingly use sophisticated models to make faster and more accurate decisions, sometimes replacing human judgment. However, model development is costly and repetitive. Neural Architecture Search (NAS) provides solutions by automating the design of deep learning architectures. This paper presents ZO-DARTS+, a differentiable NAS algorithm that improves search efficiency through a novel method of generating sparse probabilities by bi-level optimization. Experiments on five public medical datasets show that ZO-DARTS+ matches the accuracy of state-of-the-art solutions while reducing search times by up to three times.
POPNASv3: a Pareto-Optimal Neural Architecture Search Solution for Image and Time Series Classification
Dec 13, 2022The automated machine learning (AutoML) field has become increasingly relevant in recent years. These algorithms can develop models without the need for expert knowledge, facilitating the application of machine learning techniques in the industry. Neural Architecture Search (NAS) exploits deep learning techniques to autonomously produce neural network architectures whose results rival the state-of-the-art models hand-crafted by AI experts. However, this approach requires significant computational resources and hardware investments, making it less appealing for real-usage applications. This article presents the third version of Pareto-Optimal Progressive Neural Architecture Search (POPNASv3), a new sequential model-based optimization NAS algorithm targeting different hardware environments and multiple classification tasks. Our method is able to find competitive architectures within large search spaces, while keeping a flexible structure and data processing pipeline to adapt to different tasks. The algorithm employs Pareto optimality to reduce the number of architectures sampled during the search, drastically improving the time efficiency without loss in accuracy. The experiments performed on images and time series classification datasets provide evidence that POPNASv3 can explore a large set of assorted operators and converge to optimal architectures suited for the type of data provided under different scenarios.
POPNASv2: An Efficient Multi-Objective Neural Architecture Search Technique
Oct 06, 2022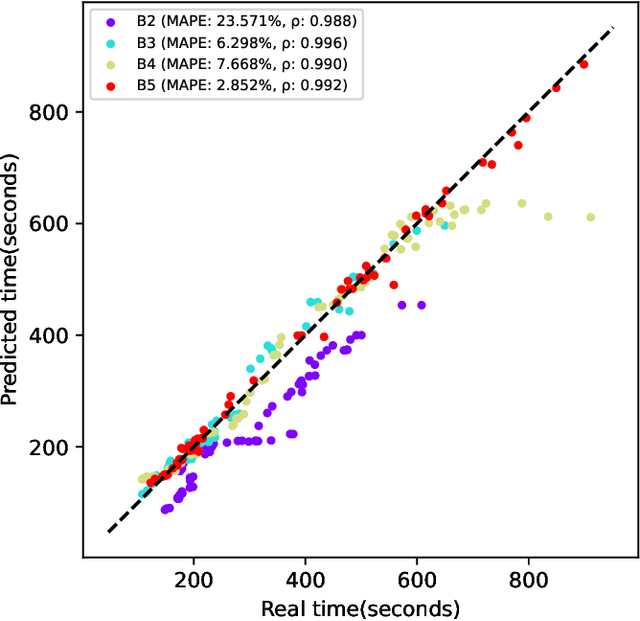
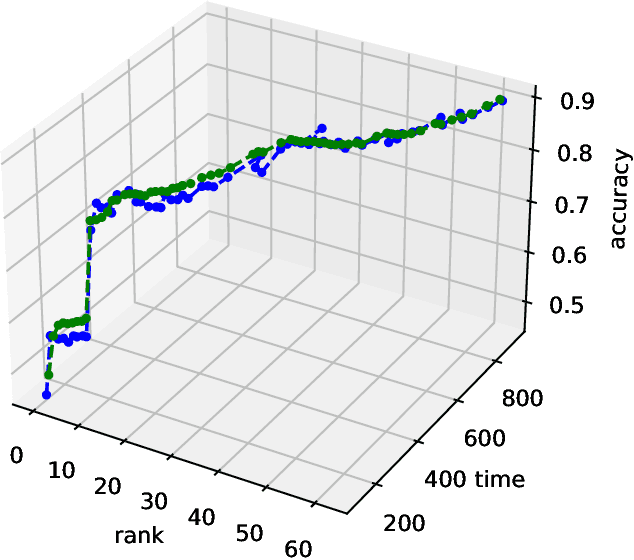
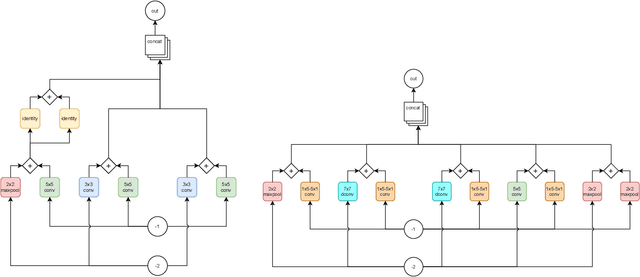
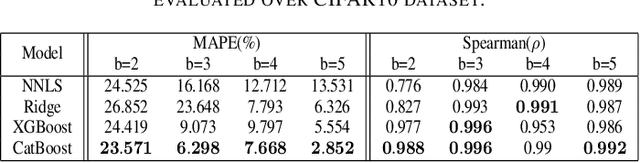
Automating the research for the best neural network model is a task that has gained more and more relevance in the last few years. In this context, Neural Architecture Search (NAS) represents the most effective technique whose results rival the state of the art hand-crafted architectures. However, this approach requires a lot of computational capabilities as well as research time, which makes prohibitive its usage in many real-world scenarios. With its sequential model-based optimization strategy, Progressive Neural Architecture Search (PNAS) represents a possible step forward to face this resources issue. Despite the quality of the found network architectures, this technique is still limited in research time. A significant step in this direction has been done by Pareto-Optimal Progressive Neural Architecture Search (POPNAS), which expands PNAS with a time predictor to enable a trade-off between search time and accuracy, considering a multi-objective optimization problem. This paper proposes a new version of the Pareto-Optimal Progressive Neural Architecture Search, called POPNASv2. Our approach enhances its first version and improves its performance. We expanded the search space by adding new operators and improved the quality of both predictors to build more accurate Pareto fronts. Moreover, we introduced cell equivalence checks and enriched the search strategy with an adaptive greedy exploration step. Our efforts allow POPNASv2 to achieve PNAS-like performance with an average 4x factor search time speed-up.
ANDREAS: Artificial intelligence traiNing scheDuler foR accElerAted resource clusterS
May 11, 2021



Artificial Intelligence (AI) and Deep Learning (DL) algorithms are currently applied to a wide range of products and solutions. DL training jobs are highly resource demanding and they experience great benefits when exploiting AI accelerators (e.g., GPUs). However, the effective management of GPU-powered clusters comes with great challenges. Among these, efficient scheduling and resource allocation solutions are crucial to maximize performance and minimize Data Centers operational costs. In this paper we propose ANDREAS, an advanced scheduling solution that tackles these problems jointly, aiming at optimizing DL training runtime workloads and their energy consumption in accelerated clusters. Experiments based on simulation demostrate that we can achieve a cost reduction between 30 and 62% on average with respect to first-principle methods while the validation on a real cluster shows a worst case deviation below 13% between actual and predicted costs, proving the effectiveness of ANDREAS solution in practical scenarios.