 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: a Multimodal Alignment and Ranking System for Few-Shot Segmentation
Apr 10, 2025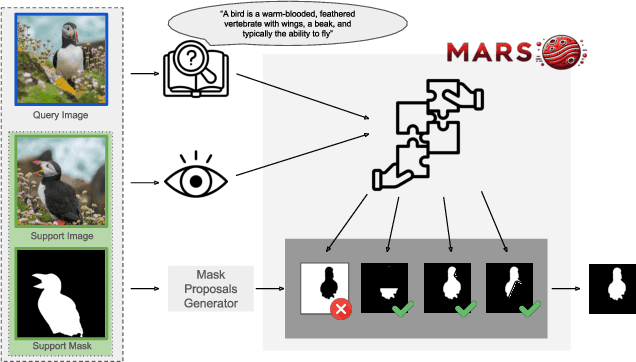
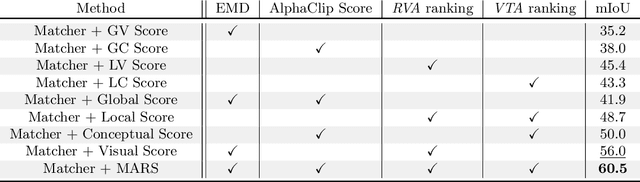
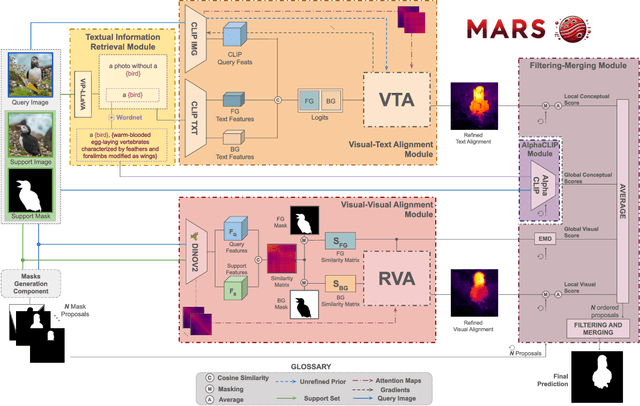

Current Few Shot Segmentation literature lacks a mask selection method that goes beyond visual similarity between the query and example images, leading to suboptimal predictions. We present MARS, a plug-and-play ranking system that leverages multimodal cues to filter and merge mask proposals robustly. Starting from a set of mask predictions for a single query image, we score, filter, and merge them to improve results. Proposals are evaluated using multimodal scores computed at local and global levels. Extensive experiments on COCO-20i, Pascal-5i, LVIS-92i, and FSS-1000 demonstrate that integrating all four scoring components is crucial for robust ranking, validating our contribution. As MARS can be effortlessly integrated with various mask proposal systems, we deploy it across a wide range of top-performer methods and achieve new state-of-the-art results on multiple existing benchmarks. Code will be available upon acceptance.
POPNASv2: An Efficient Multi-Objective Neural Architecture Search Technique
Oct 06, 2022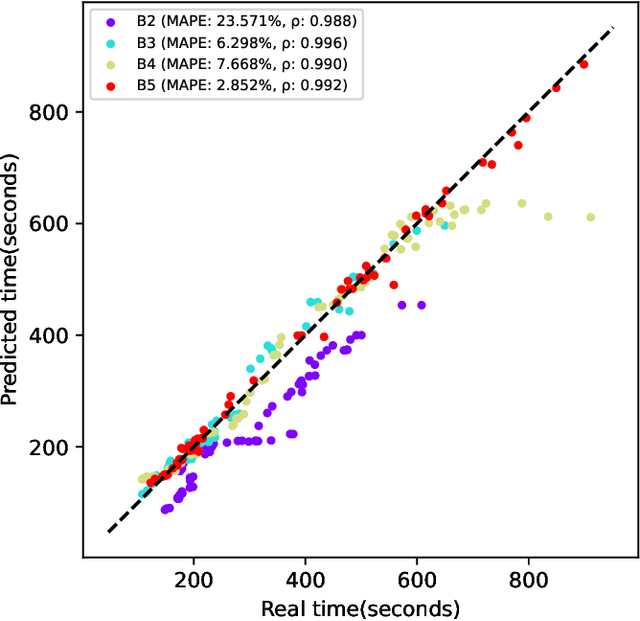
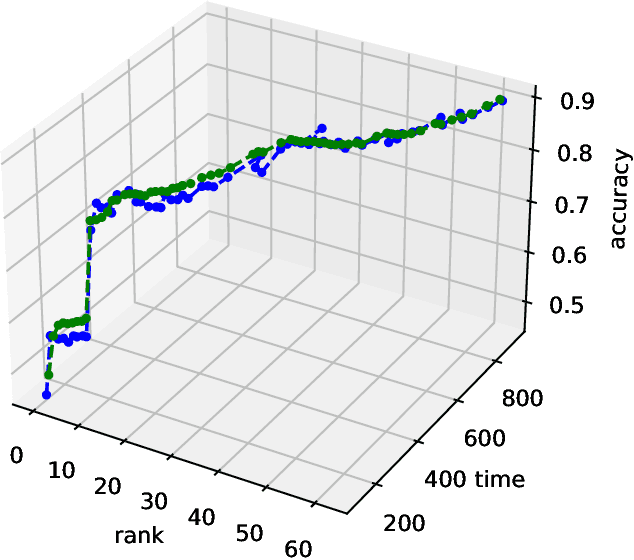
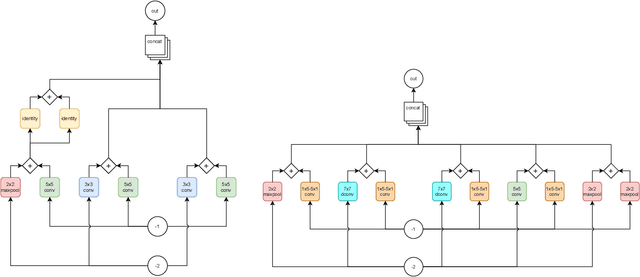
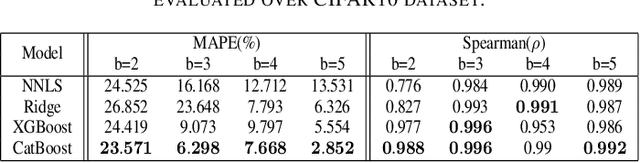
Automating the research for the best neural network model is a task that has gained more and more relevance in the last few years. In this context, Neural Architecture Search (NAS) represents the most effective technique whose results rival the state of the art hand-crafted architectures. However, this approach requires a lot of computational capabilities as well as research time, which makes prohibitive its usage in many real-world scenarios. With its sequential model-based optimization strategy, Progressive Neural Architecture Search (PNAS) represents a possible step forward to face this resources issue. Despite the quality of the found network architectures, this technique is still limited in research time. A significant step in this direction has been done by Pareto-Optimal Progressive Neural Architecture Search (POPNAS), which expands PNAS with a time predictor to enable a trade-off between search time and accuracy, considering a multi-objective optimization problem. This paper proposes a new version of the Pareto-Optimal Progressive Neural Architecture Search, called POPNASv2. Our approach enhances its first version and improves its performance. We expanded the search space by adding new operators and improved the quality of both predictors to build more accurate Pareto fronts. Moreover, we introduced cell equivalence checks and enriched the search strategy with an adaptive greedy exploration step. Our efforts allow POPNASv2 to achieve PNAS-like performance with an average 4x factor search time speed-up.
A Generative Federated Learning Framework for Differential Privacy
Sep 24, 2021



In machine learning, differential privacy and federated learning concepts are gaining more and more importance in an increasingly interconnected world. While the former refers to the sharing of private data characterized by strict security rules to protect individual privacy, the latter refers to distributed learning techniques in which a central server exchanges information with different clients for machine learning purposes. In recent years, many studies have shown the possibility of bypassing the privacy shields of these systems and exploiting the vulnerabilities of machine learning models, making them leak the information with which they have been trained. In this work, we present the 3DGL framework, an alternative to the current federated learning paradigms. Its goal is to share generative models with high levels of $\varepsilon$-differential privacy. In addition, we propose DDP-$\beta$VAE, a deep generative model capable of generating synthetic data with high levels of utility and safety for the individual. We evaluate the 3DGL framework based on DDP-$\beta$VAE, showing how the overall system is resilient to the principal attacks in federated learning and improves the performance of distributed learning algorithms.