 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: a Multimodal Alignment and Ranking System for Few-Shot Segmentation
Apr 10, 2025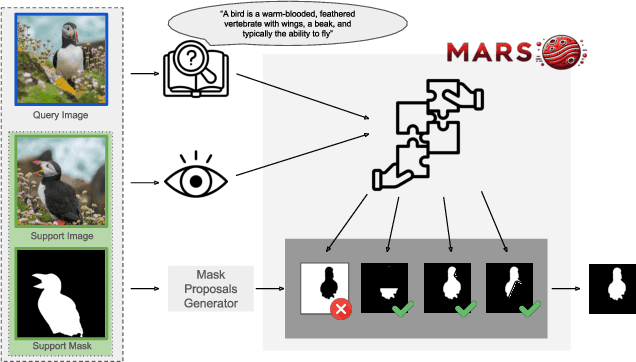
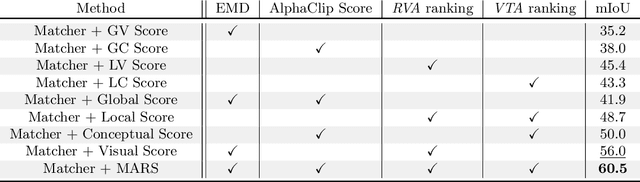
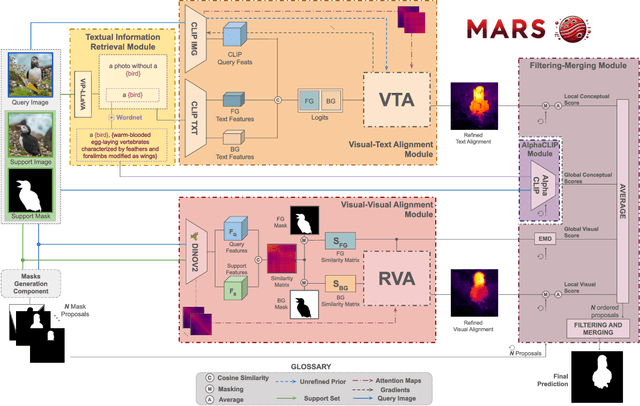

Current Few Shot Segmentation literature lacks a mask selection method that goes beyond visual similarity between the query and example images, leading to suboptimal predictions. We present MARS, a plug-and-play ranking system that leverages multimodal cues to filter and merge mask proposals robustly. Starting from a set of mask predictions for a single query image, we score, filter, and merge them to improve results. Proposals are evaluated using multimodal scores computed at local and global levels. Extensive experiments on COCO-20i, Pascal-5i, LVIS-92i, and FSS-1000 demonstrate that integrating all four scoring components is crucial for robust ranking, validating our contribution. As MARS can be effortlessly integrated with various mask proposal systems, we deploy it across a wide range of top-performer methods and achieve new state-of-the-art results on multiple existing benchmarks. Code will be available upon acceptance.
More than the Sum of Its Parts: Ensembling Backbone Networks for Few-Shot Segmentation
Feb 09, 2024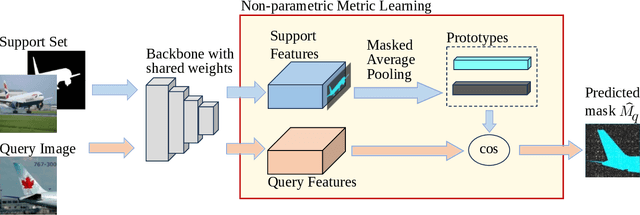
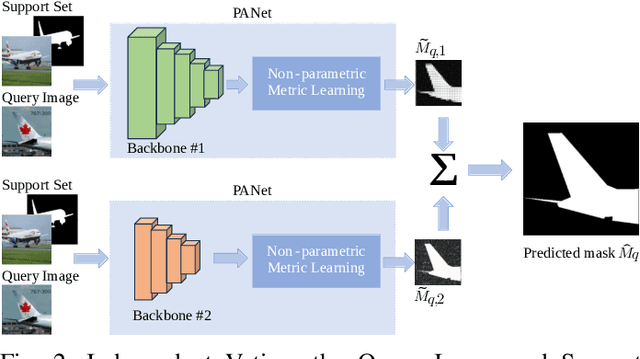
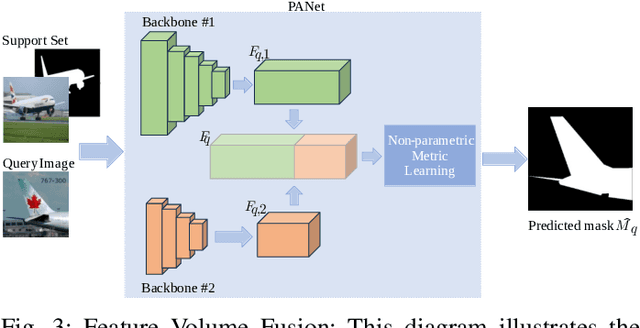

Semantic segmentation is a key prerequisite to robust image understanding for applications in \acrlong{ai} and Robotics. \acrlong{fss}, in particular, concerns the extension and optimization of traditional segmentation methods in challenging conditions where limited training examples are available. A predominant approach in \acrlong{fss} is to rely on a single backbone for visual feature extraction. Choosing which backbone to leverage is a deciding factor contributing to the overall performance. In this work, we interrogate on whether fusing features from different backbones can improve the ability of \acrlong{fss} models to capture richer visual features. To tackle this question, we propose and compare two ensembling techniques-Independent Voting and Feature Fusion. Among the available \acrlong{fss} methods, we implement the proposed ensembling techniques on PANet. The module dedicated to predicting segmentation masks from the backbone embeddings in PANet avoids trainable parameters, creating a controlled `in vitro' setting for isolating the impact of different ensembling strategies. Leveraging the complementary strengths of different backbones, our approach outperforms the original single-backbone PANet across standard benchmarks even in challenging one-shot learning scenarios. Specifically, it achieved a performance improvement of +7.37\% on PASCAL-5\textsuperscript{i} and of +10.68\% on COCO-20\textsuperscript{i} in the top-performing scenario where three backbones are combined. These results, together with the qualitative inspection of the predicted subject masks, suggest that relying on multiple backbones in PANet leads to a more comprehensive feature representation, thus expediting the successful application of \acrlong{fss} methods in challenging, data-scarce environments.
Surgical fine-tuning for Grape Bunch Segmentation under Visual Domain Shifts
Jul 03, 2023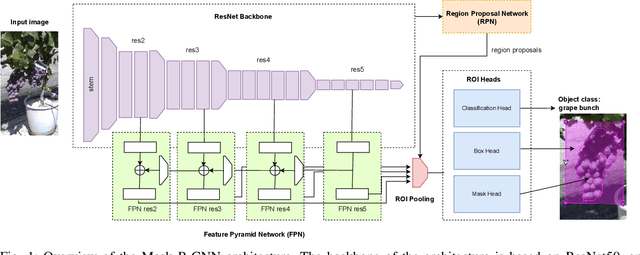

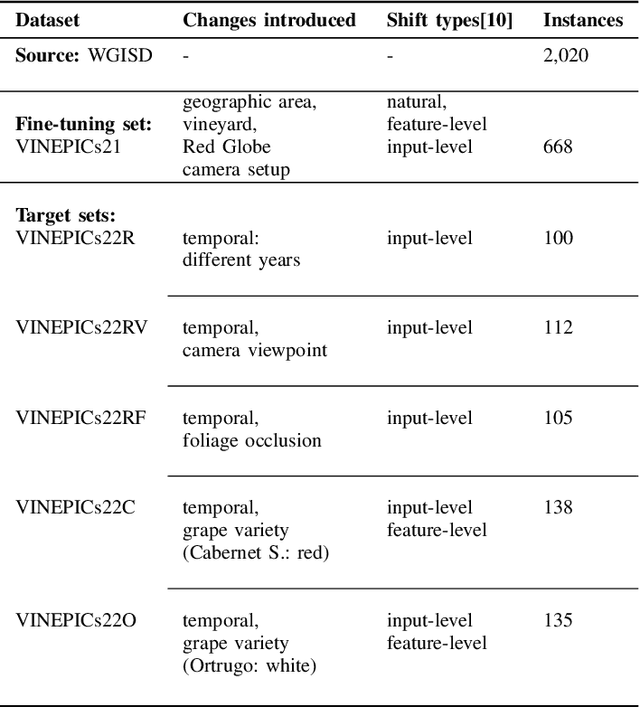

Mobile robots will play a crucial role in the transition towards sustainable agriculture. To autonomously and effectively monitor the state of plants, robots ought to be equipped with visual perception capabilities that are robust to the rapid changes that characterise agricultural settings. In this paper, we focus on the challenging task of segmenting grape bunches from images collected by mobile robots in vineyards. In this context, we present the first study that applies surgical fine-tuning to instance segmentation tasks. We show how selectively tuning only specific model layers can support the adaptation of pre-trained Deep Learning models to newly-collected grape images that introduce visual domain shifts, while also substantially reducing the number of tuned parameters.
Few Shot Semantic Segmentation: a review of methodologies and open challenges
Apr 12, 2023Semantic segmentation assigns category labels to each pixel in an image, enabling breakthroughs in fields such as autonomous driving and robotics. Deep Neural Networks have achieved high accuracies in semantic segmentation but require large training datasets. Some domains have difficulties building such datasets due to rarity, privacy concerns, and the need for skilled annotators. Few-Shot Learning (FSL) has emerged as a new research stream that allows models to learn new tasks from a few samples. This contribution provides an overview of FSL in semantic segmentation (FSS), proposes a new taxonomy, and describes current limitations and outlooks.