 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than the Sum of Its Parts: Ensembling Backbone Networks for Few-Shot Segmentation
Paper and Code
Feb 09, 2024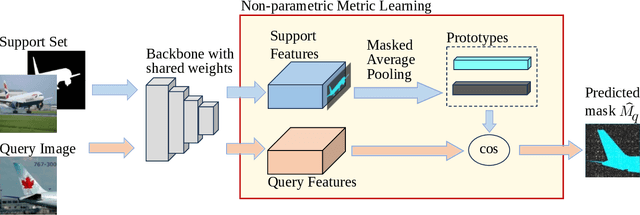
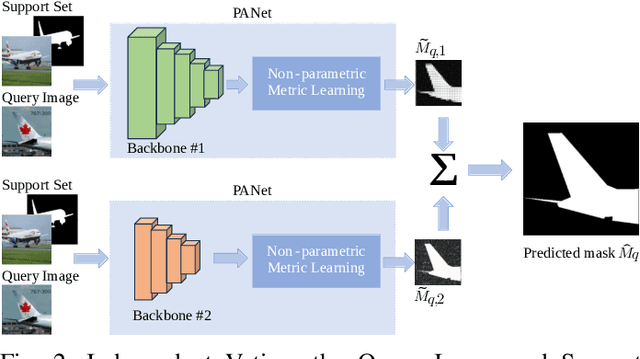
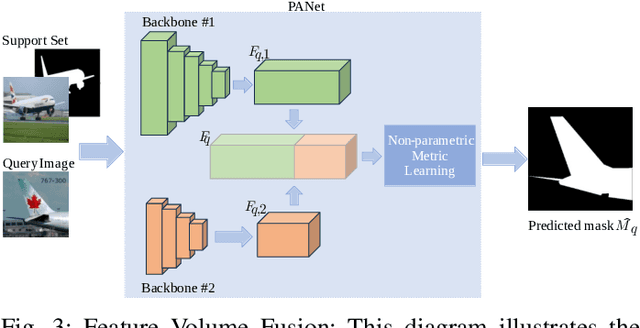

Semantic segmentation is a key prerequisite to robust image understanding for applications in \acrlong{ai} and Robotics. \acrlong{fss}, in particular, concerns the extension and optimization of traditional segmentation methods in challenging conditions where limited training examples are available. A predominant approach in \acrlong{fss} is to rely on a single backbone for visual feature extraction. Choosing which backbone to leverage is a deciding factor contributing to the overall performance. In this work, we interrogate on whether fusing features from different backbones can improve the ability of \acrlong{fss} models to capture richer visual features. To tackle this question, we propose and compare two ensembling techniques-Independent Voting and Feature Fusion. Among the available \acrlong{fss} methods, we implement the proposed ensembling techniques on PANet. The module dedicated to predicting segmentation masks from the backbone embeddings in PANet avoids trainable parameters, creating a controlled `in vitro' setting for isolating the impact of different ensembling strategies. Leveraging the complementary strengths of different backbones, our approach outperforms the original single-backbone PANet across standard benchmarks even in challenging one-shot learning scenarios. Specifically, it achieved a performance improvement of +7.37\% on PASCAL-5\textsuperscript{i} and of +10.68\% on COCO-20\textsuperscript{i} in the top-performing scenario where three backbones are combined. These results, together with the qualitative inspection of the predicted subject masks, suggest that relying on multiple backbones in PANet leads to a more comprehensive feature representation, thus expediting the successful application of \acrlong{fss} methods in challenging, data-scarce environments.