 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Once-For-All: A Study on Parallel Blocks, Skip Connections and Early Exits
Feb 03, 2023



The use of Neural Architecture Search (NAS) techniques to automate the design of neural networks has become increasingly popular in recent years. The proliferation of devices with different hardware characteristics using such neural networks, as well as the need to reduce the power consumption for their search, has led to the realisation of Once-For-All (OFA), an eco-friendly algorithm characterised by the ability to generate easily adaptable models through a single learning process. In order to improve this paradigm and develop high-performance yet eco-friendly NAS techniques, this paper presents OFAv2, the extension of OFA aimed at improving its performance while maintaining the same ecological advantage. The algorithm is improved from an architectural point of view by including early exits, parallel blocks and dense skip connections. The training process is extended by two new phases called Elastic Level and Elastic Height. A new Knowledge Distillation technique is presented to handle multi-output networks, and finally a new strategy for dynamic teacher network selection is proposed. These modifications allow OFAv2 to improve its accuracy performance on the Tiny ImageNet dataset by up to 12.07% compared to the original version of OFA, while maintaining the algorithm flexibility and advantages.
POPNASv3: a Pareto-Optimal Neural Architecture Search Solution for Image and Time Series Classification
Dec 13, 2022The automated machine learning (AutoML) field has become increasingly relevant in recent years. These algorithms can develop models without the need for expert knowledge, facilitating the application of machine learning techniques in the industry. Neural Architecture Search (NAS) exploits deep learning techniques to autonomously produce neural network architectures whose results rival the state-of-the-art models hand-crafted by AI experts. However, this approach requires significant computational resources and hardware investments, making it less appealing for real-usage applications. This article presents the third version of Pareto-Optimal Progressive Neural Architecture Search (POPNASv3), a new sequential model-based optimization NAS algorithm targeting different hardware environments and multiple classification tasks. Our method is able to find competitive architectures within large search spaces, while keeping a flexible structure and data processing pipeline to adapt to different tasks. The algorithm employs Pareto optimality to reduce the number of architectures sampled during the search, drastically improving the time efficiency without loss in accuracy. The experiments performed on images and time series classification datasets provide evidence that POPNASv3 can explore a large set of assorted operators and converge to optimal architectures suited for the type of data provided under different scenarios.
POPNASv2: An Efficient Multi-Objective Neural Architecture Search Technique
Oct 06, 2022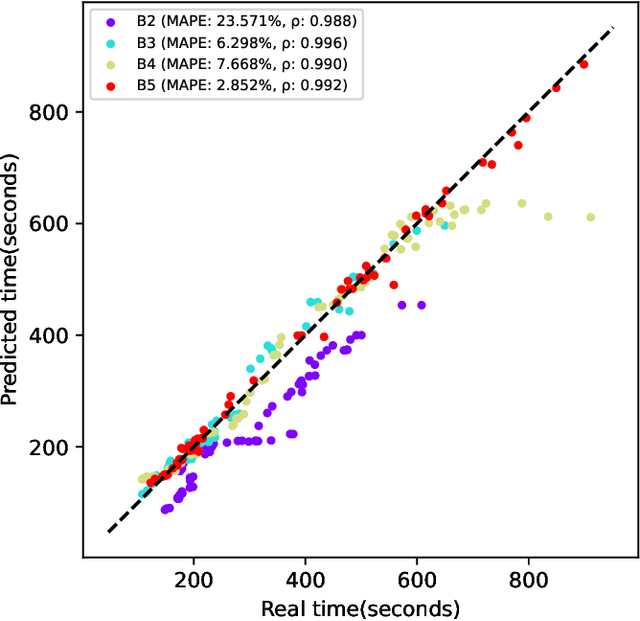
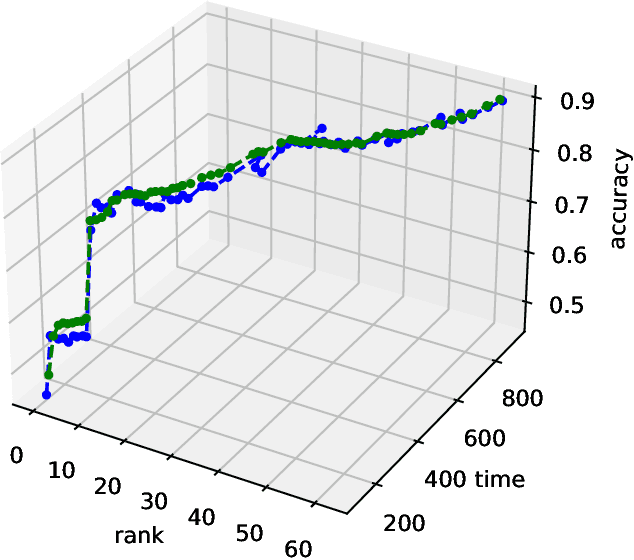
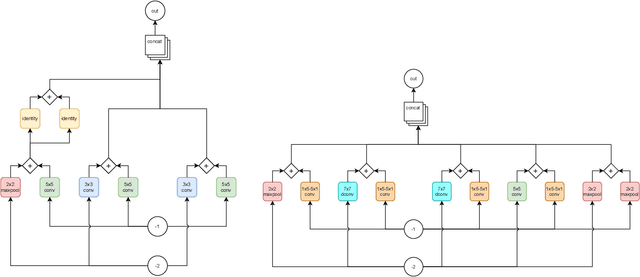
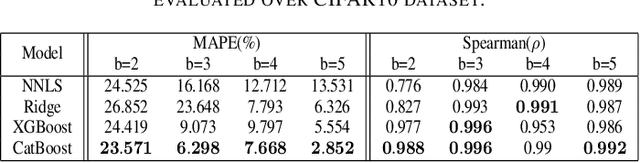
Automating the research for the best neural network model is a task that has gained more and more relevance in the last few years. In this context, Neural Architecture Search (NAS) represents the most effective technique whose results rival the state of the art hand-crafted architectures. However, this approach requires a lot of computational capabilities as well as research time, which makes prohibitive its usage in many real-world scenarios. With its sequential model-based optimization strategy, Progressive Neural Architecture Search (PNAS) represents a possible step forward to face this resources issue. Despite the quality of the found network architectures, this technique is still limited in research time. A significant step in this direction has been done by Pareto-Optimal Progressive Neural Architecture Search (POPNAS), which expands PNAS with a time predictor to enable a trade-off between search time and accuracy, considering a multi-objective optimization problem. This paper proposes a new version of the Pareto-Optimal Progressive Neural Architecture Search, called POPNASv2. Our approach enhances its first version and improves its performance. We expanded the search space by adding new operators and improved the quality of both predictors to build more accurate Pareto fronts. Moreover, we introduced cell equivalence checks and enriched the search strategy with an adaptive greedy exploration step. Our efforts allow POPNASv2 to achieve PNAS-like performance with an average 4x factor search time speed-up.