 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Efficient Split Learning of ViTs with Attention-based Double Compression
Sep 18, 2025



This paper proposes a novel communication-efficient Split Learning (SL) framework, named Attention-based Double Compression (ADC), which reduces the communication overhead required for transmitting intermediate Vision Transformers activations during the SL training process. ADC incorporates two parallel compression strategies. The first one merges samples' activations that are similar, based on the average attention score calculated in the last client layer; this strategy is class-agnostic, meaning that it can also merge samples having different classes, without losing generalization ability nor decreasing final results. The second strategy follows the first and discards the least meaningful tokens, further reducing the communication cost. Combining these strategies not only allows for sending less during the forward pass, but also the gradients are naturally compressed, allowing the whole model to be trained without additional tuning or approximations of the gradients. Simulation results demonstrate that Attention-based Double Compression outperforms state-of-the-art SL frameworks by significantly reducing communication overheads while maintaining high accuracy.
Adaptive Semantic Token Communication for Transformer-based Edge Inference
May 23, 2025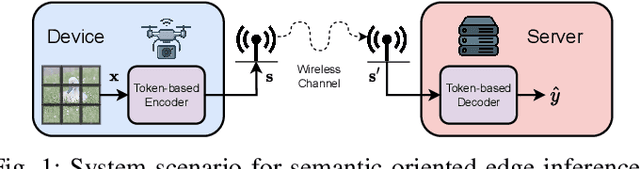



This paper presents an adaptive framework for edge inference based on a dynamically configurable transformer-powered deep joint source channel coding (DJSCC) architecture. Motivated by a practical scenario where a resource constrained edge device engages in goal oriented semantic communication, such as selectively transmitting essential features for object detection to an edge server, our approach enables efficient task aware data transmission under varying bandwidth and channel conditions. To achieve this, input data is tokenized into compact high level semantic representations, refined by a transformer, and transmitted over noisy wireless channels. As part of the DJSCC pipeline, we employ a semantic token selection mechanism that adaptively compresses informative features into a user specified number of tokens per sample. These tokens are then further compressed through the JSCC module, enabling a flexible token communication strategy that adjusts both the number of transmitted tokens and their embedding dimensions. We incorporate a resource allocation algorithm based on Lyapunov stochastic optimization to enhance robustness under dynamic network conditions, effectively balancing compression efficiency and task performance. Experimental results demonstrate that our system consistently outperforms existing baselines, highlighting its potential as a strong foundation for AI native semantic communication in edge intelligence applications.
MASS: MoErging through Adaptive Subspace Selection
Apr 06, 2025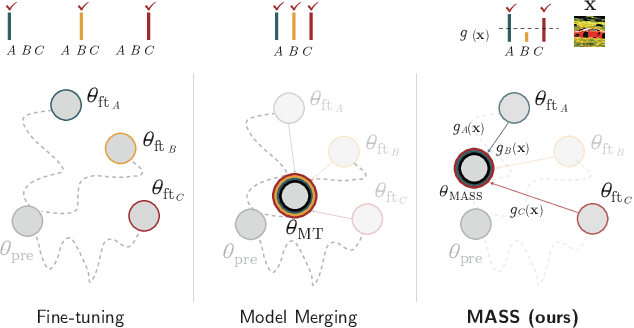
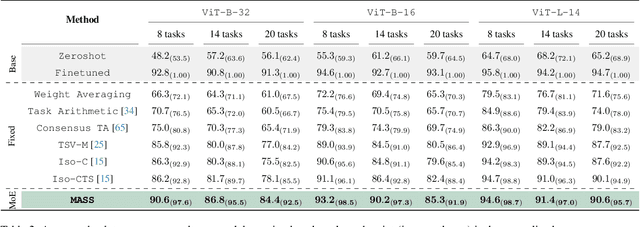
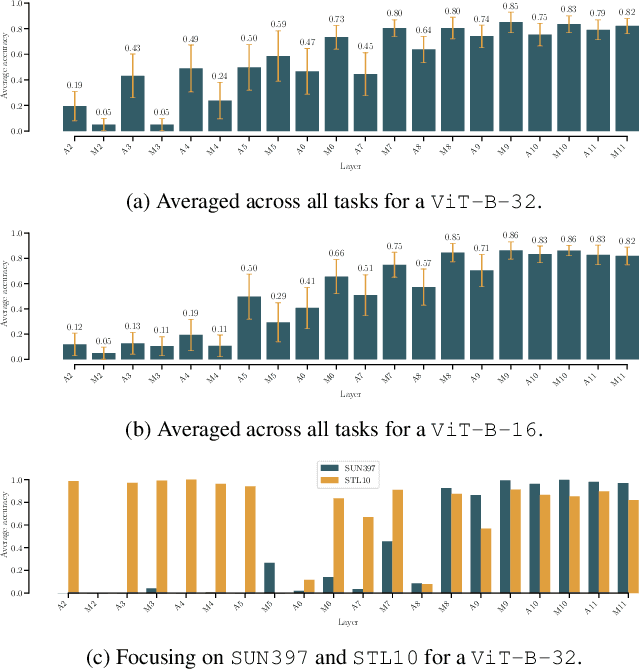
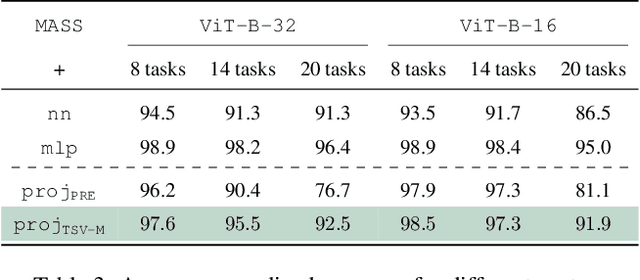
Model merging has recently emerged as a lightweight alternative to ensembling, combining multiple fine-tuned models into a single set of parameters with no additional training overhead. Yet, existing merging methods fall short of matching the full accuracy of separately fine-tuned endpoints. We present MASS (MoErging through Adaptive Subspace Selection), a new approach that closes this gap by unifying multiple fine-tuned models while retaining near state-of-the-art performance across tasks. Building on the low-rank decomposition of per-task updates, MASS stores only the most salient singular components for each task and merges them into a shared model. At inference time, a non-parametric, data-free router identifies which subspace (or combination thereof) best explains an input's intermediate features and activates the corresponding task-specific block. This procedure is fully training-free and introduces only a two-pass inference overhead plus a ~2 storage factor compared to a single pretrained model, irrespective of the number of tasks. We evaluate MASS on CLIP-based image classification using ViT-B-16, ViT-B-32 and ViT-L-14 for benchmarks of 8, 14 and 20 tasks respectively, establishing a new state-of-the-art. Most notably, MASS recovers up to ~98% of the average accuracy of individual fine-tuned models, making it a practical alternative to ensembling at a fraction of the storage cost.
Q-Filters: Leveraging QK Geometry for Efficient KV Cache Compression
Mar 04, 2025Autoregressive language models rely on a Key-Value (KV) Cache, which avoids re-computing past hidden states during generation, making it faster. As model sizes and context lengths grow, the KV Cache becomes a significant memory bottleneck, which calls for compression methods that limit its size during generation. In this paper, we discover surprising properties of Query (Q) and Key (K) vectors that allow us to efficiently approximate attention scores without computing the attention maps. We propose Q-Filters, a training-free KV Cache compression method that filters out less crucial Key-Value pairs based on a single context-agnostic projection. Contrarily to many alternatives, Q-Filters is compatible with FlashAttention, as it does not require direct access to attention weights. Experimental results in long-context settings demonstrate that Q-Filters is competitive with attention-based compression methods such as SnapKV in retrieval tasks while consistently outperforming efficient compression schemes such as Streaming-LLM in generation setups. Notably, Q-Filters achieves a 99% accuracy in the needle-in-a-haystack task with a x32 compression level while reducing the generation perplexity drop by up to 65% in text generation compared to Streaming-LLM.
A Survey on Dynamic Neural Networks: from Computer Vision to Multi-modal Sensor Fusion
Jan 13, 2025Model compression is essential in the deployment of large Computer Vision models on embedded devices. However, static optimization techniques (e.g. pruning, quantization, etc.) neglect the fact that different inputs have different complexities, thus requiring different amount of computations. Dynamic Neural Networks allow to condition the number of computations to the specific input. The current literature on the topic is very extensive and fragmented. We present a comprehensive survey that synthesizes and unifies existing Dynamic Neural Networks research in the context of Computer Vision. Additionally, we provide a logical taxonomy based on which component of the network is adaptive: the output, the computation graph or the input. Furthermore, we argue that Dynamic Neural Networks are particularly beneficial in the context of Sensor Fusion for better adaptivity, noise reduction and information prioritization. We present preliminary works in this direction.
Mixture-of-Experts Graph Transformers for Interpretable Particle Collision Detection
Jan 08, 2025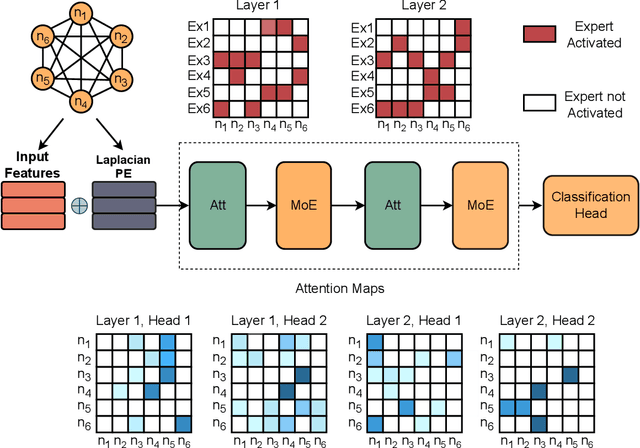
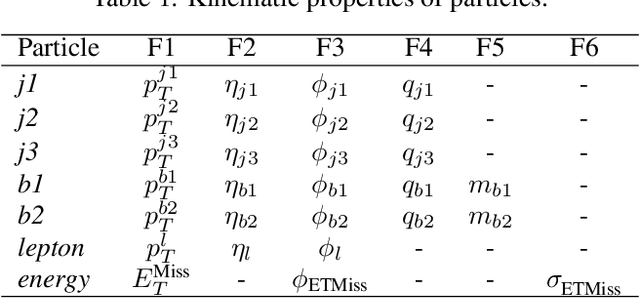
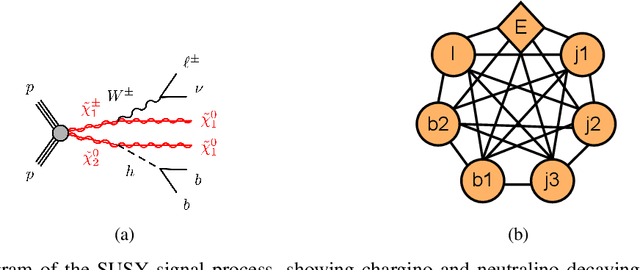

The Large Hadron Collider at CERN produces immense volumes of complex data from high-energy particle collisions, demanding sophisticated analytical techniques for effective interpretation. Neural Networks, including Graph Neural Networks, have shown promise in tasks such as event classification and object identification by representing collisions as graphs. However, while Graph Neural Networks excel in predictive accuracy, their "black box" nature often limits their interpretability, making it difficult to trust their decision-making processes. In this paper, we propose a novel approach that combines a Graph Transformer model with Mixture-of-Expert layers to achieve high predictive performance while embedding interpretability into the architecture. By leveraging attention maps and expert specialization, the model offers insights into its internal decision-making, linking predictions to physics-informed features. We evaluate the model on simulated events from the ATLAS experiment, focusing on distinguishing rare Supersymmetric signal events from Standard Model background. Our results highlight that the model achieves competitive classification accuracy while providing interpretable outputs that align with known physics, demonstrating its potential as a robust and transparent tool for high-energy physics data analysis. This approach underscores the importance of explainability in machine learning methods applied to high energy physics, offering a path toward greater trust in AI-driven discoveries.
Goal-oriented Communications based on Recursive Early Exit Neural Networks
Dec 27, 2024



This paper presents a novel framework for goal-oriented semantic communications leveraging recursive early exit models. The proposed approach is built on two key components. First, we introduce an innovative early exit strategy that dynamically partitions computations, enabling samples to be offloaded to a server based on layer-wise recursive prediction dynamics that detect samples for which the confidence is not increasing fast enough over layers. Second, we develop a Reinforcement Learning-based online optimization framework that jointly determines early exit points, computation splitting, and offloading strategies, while accounting for wireless conditions, inference accuracy, and resource costs. Numerical evaluations in an edge inference scenario demonstrate the method's adaptability and effectiveness in striking an excellent trade-off between performance, latency, and resource efficiency.
Task Singular Vectors: Reducing Task Interference in Model Merging
Nov 26, 2024



Task Arithmetic has emerged as a simple yet effective method to merge models without additional training. However, by treating entire networks as flat parameter vectors, it overlooks key structural information and is susceptible to task interference. In this paper, we study task vectors at the layer level, focusing on task layer matrices and their singular value decomposition. In particular, we concentrate on the resulting singular vectors, which we refer to as Task Singular Vectors (TSV). Recognizing that layer task matrices are often low-rank, we propose TSV-Compress (TSV-C), a simple procedure that compresses them to 10% of their original size while retaining 99% of accuracy. We further leverage this low-rank space to define a new measure of task interference based on the interaction of singular vectors from different tasks. Building on these findings, we introduce TSV-Merge (TSV-M), a novel model merging approach that combines compression with interference reduction, significantly outperforming existing methods.
Interpreting Temporal Graph Neural Networks with Koopman Theory
Oct 17, 2024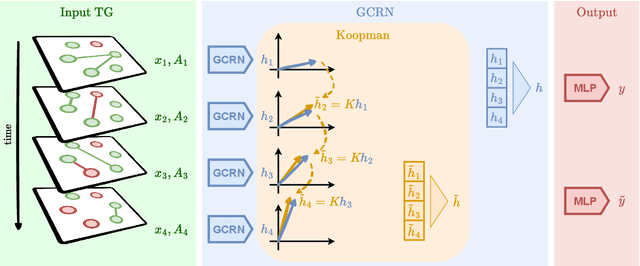
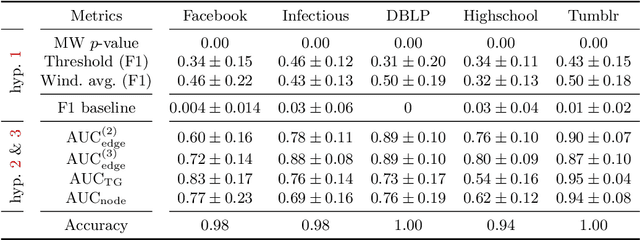
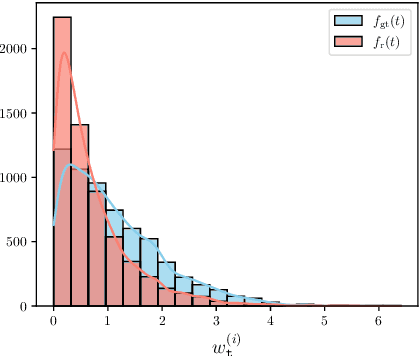
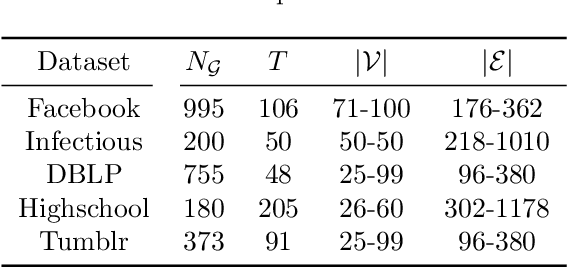
Spatiotemporal graph neural networks (STGNNs) have shown promising results in many domains, from forecasting to epidemiology. However, understanding the dynamics learned by these models and explaining their behaviour is significantly more complex than for models dealing with static data. Inspired by Koopman theory, which allows a simpler description of intricate, nonlinear dynamical systems, we introduce an explainability approach for temporal graphs. We present two methods to interpret the STGNN's decision process and identify the most relevant spatial and temporal patterns in the input for the task at hand. The first relies on dynamic mode decomposition (DMD), a Koopman-inspired dimensionality reduction method. The second relies on sparse identification of nonlinear dynamics (SINDy), a popular method for discovering governing equations, which we use for the first time as a general tool for explainability. We show how our methods can correctly identify interpretable features such as infection times and infected nodes in the context of dissemination processes.
How to Connect Speech Foundation Models and Large Language Models? What Matters and What Does Not
Sep 25, 2024



The remarkable performance achieved by Large Language Models (LLM) has driven research efforts to leverage them for a wide range of tasks and input modalities. In speech-to-text (S2T) tasks, the emerging solution consists of projecting the output of the encoder of a Speech Foundational Model (SFM) into the LLM embedding space through an adapter module. However, no work has yet investigated how much the downstream-task performance depends on each component (SFM, adapter, LLM) nor whether the best design of the adapter depends on the chosen SFM and LLM. To fill this gap, we evaluate the combination of 5 adapter modules, 2 LLMs (Mistral and Llama), and 2 SFMs (Whisper and SeamlessM4T) on two widespread S2T tasks, namely Automatic Speech Recognition and Speech Translation. Our results demonstrate that the SFM plays a pivotal role in downstream performance, while the adapter choice has moderate impact and depends on the SFM and LLM.