 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Connect Speech Foundation Models and Large Language Models? What Matters and What Does Not
Sep 25, 2024



The remarkable performance achieved by Large Language Models (LLM) has driven research efforts to leverage them for a wide range of tasks and input modalities. In speech-to-text (S2T) tasks, the emerging solution consists of projecting the output of the encoder of a Speech Foundational Model (SFM) into the LLM embedding space through an adapter module. However, no work has yet investigated how much the downstream-task performance depends on each component (SFM, adapter, LLM) nor whether the best design of the adapter depends on the chosen SFM and LLM. To fill this gap, we evaluate the combination of 5 adapter modules, 2 LLMs (Mistral and Llama), and 2 SFMs (Whisper and SeamlessM4T) on two widespread S2T tasks, namely Automatic Speech Recognition and Speech Translation. Our results demonstrate that the SFM plays a pivotal role in downstream performance, while the adapter choice has moderate impact and depends on the SFM and LLM.
Preserving Privacy in Large Language Models: A Survey on Current Threats and Solutions
Aug 10, 2024



Large Language Models (LLMs) represent a significant advancement in artificial intelligence, finding applications across various domains. However, their reliance on massive internet-sourced datasets for training brings notable privacy issues, which are exacerbated in critical domains (e.g., healthcare). Moreover, certain application-specific scenarios may require fine-tuning these models on private data. This survey critically examines the privacy threats associated with LLMs, emphasizing the potential for these models to memorize and inadvertently reveal sensitive information. We explore current threats by reviewing privacy attacks on LLMs and propose comprehensive solutions for integrating privacy mechanisms throughout the entire learning pipeline. These solutions range from anonymizing training datasets to implementing differential privacy during training or inference and machine unlearning after training. Our comprehensive review of existing literature highlights ongoing challenges, available tools, and future directions for preserving privacy in LLMs. This work aims to guide the development of more secure and trustworthy AI systems by providing a thorough understanding of privacy preservation methods and their effectiveness in mitigating risks.
A Bayesian approach to translators' reliability assessment
Apr 12, 2022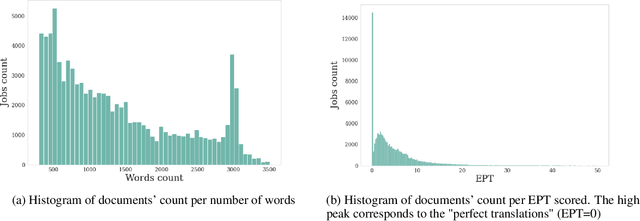
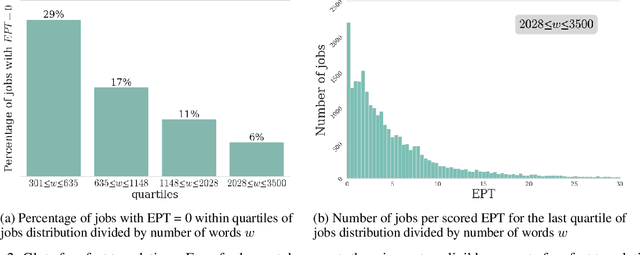
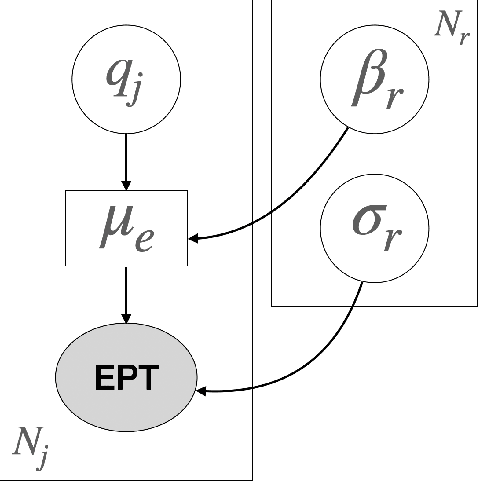
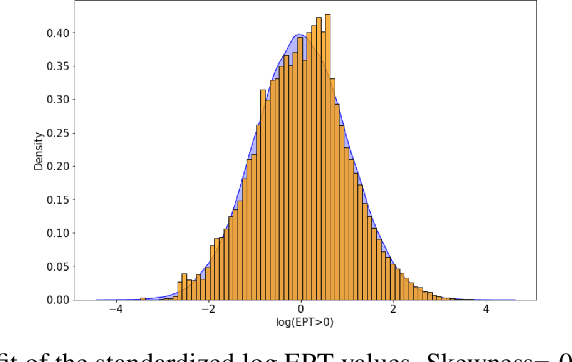
Translation Quality Assessment (TQA) is a process conducted by human translators and is widely used, both for estimating the performance of (increasingly used) Machine Translation, and for finding an agreement between translation providers and their customers. While translation scholars are aware of the importance of having a reliable way to conduct the TQA process, it seems that there is limited literature that tackles the issue of reliability with a quantitative approach. In this work, we consider the TQA as a complex process from the point of view of physics of complex systems and approach the reliability issue from the Bayesian paradigm. Using a dataset of translation quality evaluations (in the form of error annotations), produced entirely by the Professional Translation Service Provider Translated SRL, we compare two Bayesian models that parameterise the following features involved in the TQA process: the translation difficulty, the characteristics of the translators involved in producing the translation, and of those assessing its quality - the reviewers. We validate the models in an unsupervised setting and show that it is possible to get meaningful insights into translators even with just one review per translation; subsequently, we extract information like translators' skills and reviewers' strictness, as well as their consistency in their respective roles. Using this, we show that the reliability of reviewers cannot be taken for granted even in the case of expert translators: a translator's expertise can induce a cognitive bias when reviewing a translation produced by another translator. The most expert translators, however, are characterised by the highest level of consistency, both in translating and in assessing the translation quality.