 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Tweedie: Score meets Score, Energy meets Energy
Dec 29, 2025Denoising and score estimation have long been known to be linked via the classical Tweedie's formula. In this work, we first extend the latter to a wider range of distributions often called "energy models" and denoted elliptical distributions in this work. Next, we examine an alternative view: we consider the denoising posterior $P(X|Y)$ as the optimizer of the energy score (a scoring rule) and derive a fundamental identity that connects the (path-) derivative of a (possibly) non-Euclidean energy score to the score of the noisy marginal. This identity can be seen as an analog of Tweedie's identity for the energy score, and allows for several interesting applications; for example, score estimation, noise distribution parameter estimation, as well as using energy score models in the context of "traditional" diffusion model samplers with a wider array of noising distributions.
Distributional autoencoders know the score
Feb 17, 2025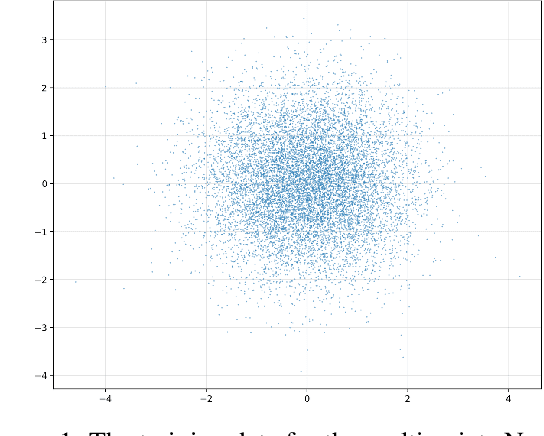
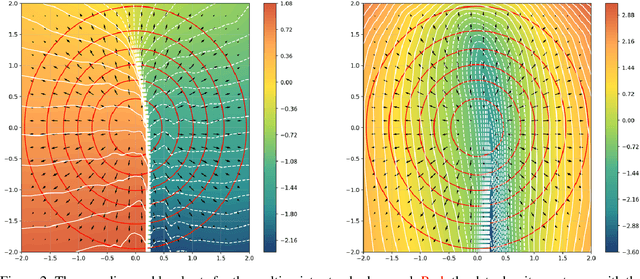
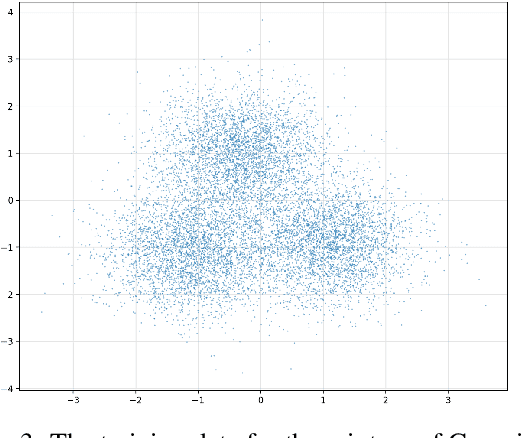
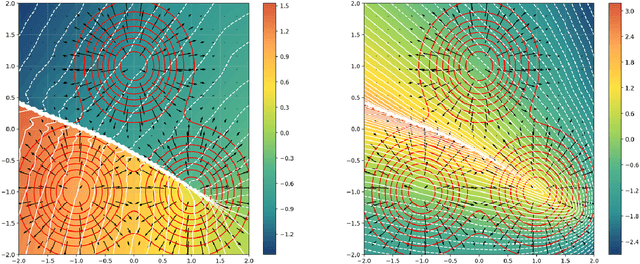
This work presents novel and desirable properties of a recently introduced class of autoencoders -- the Distributional Principal Autoencoder (DPA) -- that combines distributionally correct reconstruction with principal components-like interpretability of the encodings. First, we show that the level sets of the encoder orient themselves exactly with regard to the score of the data distribution. This both explains the method's often remarkable performance in disentangling the the factors of variation of the data, as well as opens up possibilities of recovering its distribution while having access to samples only. In settings where the score itself has physical meaning -- such as when the data obey the Boltzmann distribution -- we demonstrate that the method can recover scientifically important quantities such as the \textit{minimum free energy path}. Second, we show that if the data lie on a manifold that can be approximated by the encoder, the optimal encoder's components beyond the dimension of the manifold will carry absolutely no additional information about the data distribution. This promises new ways of determining the number of relevant dimensions of the data beyond common heuristics such as the scree plot. Finally, the fact that the method is learning the score means that it could have promise as a generative model, potentially rivaling approaches such as diffusion, which similarly attempts to approximate the score of the data distribution.
Approaching an unknown communication system by latent space exploration and causal inference
Mar 20, 2023

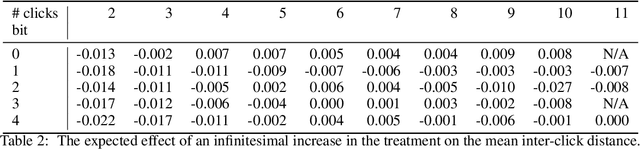

This paper proposes a methodology for discovering meaningful properties in data by exploring the latent space of unsupervised deep generative models. We combine manipulation of individual latent variables to extreme values outside the training range with methods inspired by causal inference into an approach we call causal disentanglement with extreme values (CDEV) and show that this approach yields insights for model interpretability. Using this technique, we can infer what properties of unknown data the model encodes as meaningful. We apply the methodology to test what is meaningful in the communication system of sperm whales, one of the most intriguing and understudied animal communication systems. We train a network that has been shown to learn meaningful representations of speech and test whether we can leverage such unsupervised learning to decipher the properties of another vocal communication system for which we have no ground truth. The proposed technique suggests that sperm whales encode information using the number of clicks in a sequence, the regularity of their timing, and audio properties such as the spectral mean and the acoustic regularity of the sequences. Some of these findings are consistent with existing hypotheses, while others are proposed for the first time. We also argue that our models uncover rules that govern the structure of communication units in the sperm whale communication system and apply them while generating innovative data not shown during training. This paper suggests that an interpretation of the outputs of deep neural networks with causal methodology can be a viable strategy for approaching data about which little is known and presents another case of how deep learning can limit the hypothesis space. Finally, the proposed approach combining latent space manipulation and causal inference can be extended to other architectures and arbitrary datasets.
A Bayesian approach to translators' reliability assessment
Apr 12, 2022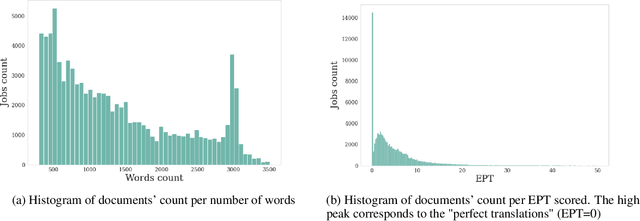
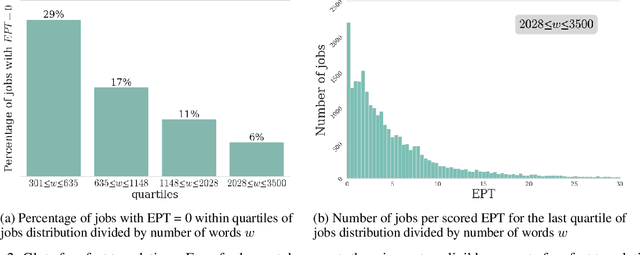
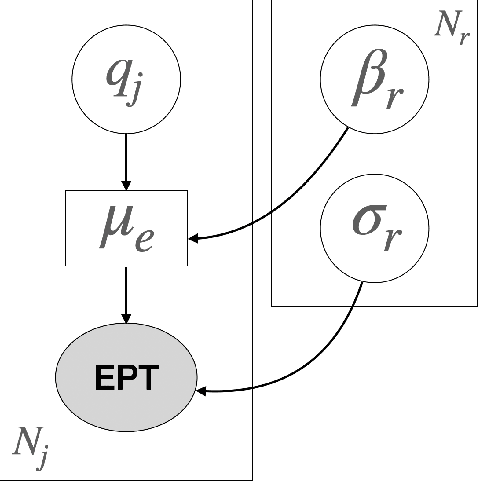
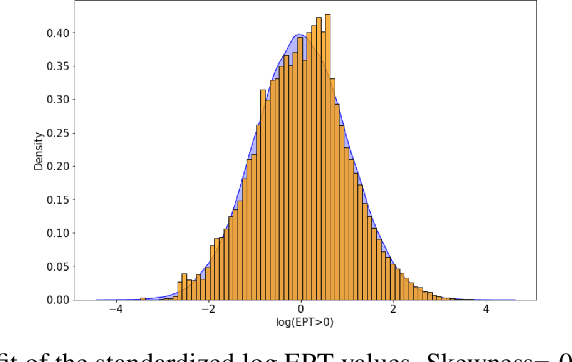
Translation Quality Assessment (TQA) is a process conducted by human translators and is widely used, both for estimating the performance of (increasingly used) Machine Translation, and for finding an agreement between translation providers and their customers. While translation scholars are aware of the importance of having a reliable way to conduct the TQA process, it seems that there is limited literature that tackles the issue of reliability with a quantitative approach. In this work, we consider the TQA as a complex process from the point of view of physics of complex systems and approach the reliability issue from the Bayesian paradigm. Using a dataset of translation quality evaluations (in the form of error annotations), produced entirely by the Professional Translation Service Provider Translated SRL, we compare two Bayesian models that parameterise the following features involved in the TQA process: the translation difficulty, the characteristics of the translators involved in producing the translation, and of those assessing its quality - the reviewers. We validate the models in an unsupervised setting and show that it is possible to get meaningful insights into translators even with just one review per translation; subsequently, we extract information like translators' skills and reviewers' strictness, as well as their consistency in their respective roles. Using this, we show that the reliability of reviewers cannot be taken for granted even in the case of expert translators: a translator's expertise can induce a cognitive bias when reviewing a translation produced by another translator. The most expert translators, however, are characterised by the highest level of consistency, both in translating and in assessing the translation quality.