 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional autoencoders know the score
Paper and Code
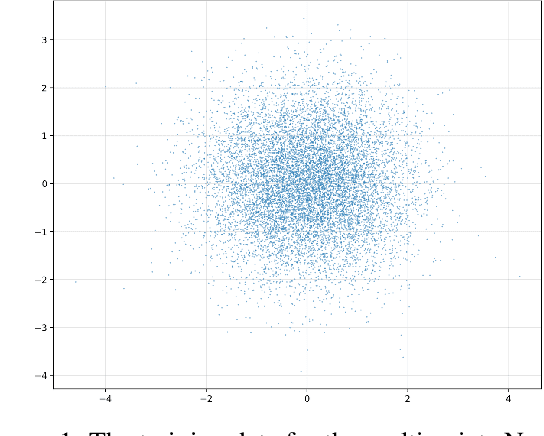
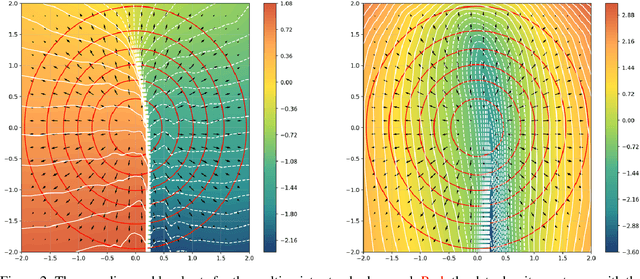
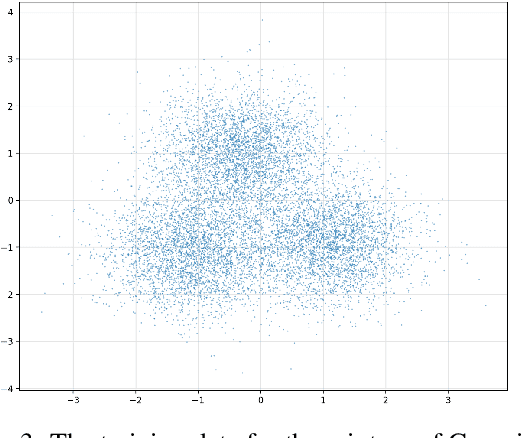
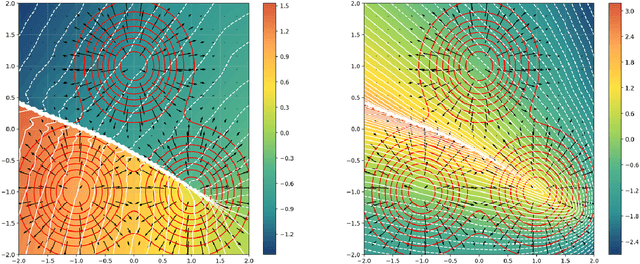
This work presents novel and desirable properties of a recently introduced class of autoencoders -- the Distributional Principal Autoencoder (DPA) -- that combines distributionally correct reconstruction with principal components-like interpretability of the encodings. First, we show that the level sets of the encoder orient themselves exactly with regard to the score of the data distribution. This both explains the method's often remarkable performance in disentangling the the factors of variation of the data, as well as opens up possibilities of recovering its distribution while having access to samples only. In settings where the score itself has physical meaning -- such as when the data obey the Boltzmann distribution -- we demonstrate that the method can recover scientifically important quantities such as the \textit{minimum free energy path}. Second, we show that if the data lie on a manifold that can be approximated by the encoder, the optimal encoder's components beyond the dimension of the manifold will carry absolutely no additional information about the data distribution. This promises new ways of determining the number of relevant dimensions of the data beyond common heuristics such as the scree plot. Finally, the fact that the method is learning the score means that it could have promise as a generative model, potentially rivaling approaches such as diffusion, which similarly attempts to approximate the score of the data distribution.