 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating Innovation Using Large Language Models
May 06, 2026Forecasting innovation, intended as the emergence of new technological combinations, is a fundamental challenge for science and policy. We show that forthcoming combinations leave an early trace in the collective language of patents, with predictive signals detectable even decades in advance. We show that signal is not attributable to any single inventor, but emerges as a collective shift in how technologies are described across thousands of patents. To this end, we introduce TechToken, a transformer-based model that treats technologies, classified by International Patent Classification codes, as words in its vocabulary, learning the language of technologies by embedding these codes during fine-tuning. We define context similarity between code embeddings as a measure of linguistic convergence and show that it accurately predicts first technological combinations. TechToken also improves general representation quality, outperforming state-of-the-art models across different patent-related tasks.
Follow the money: a startup-based measure of AI exposure across occupations, industries and regions
Dec 06, 2024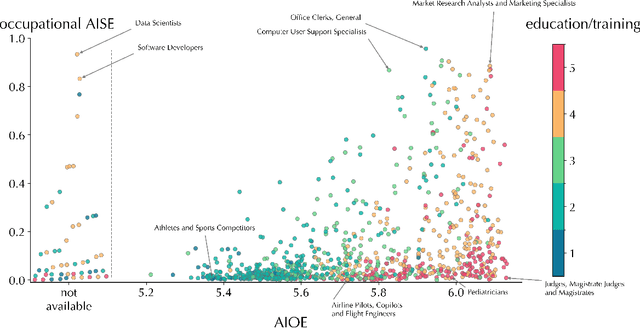
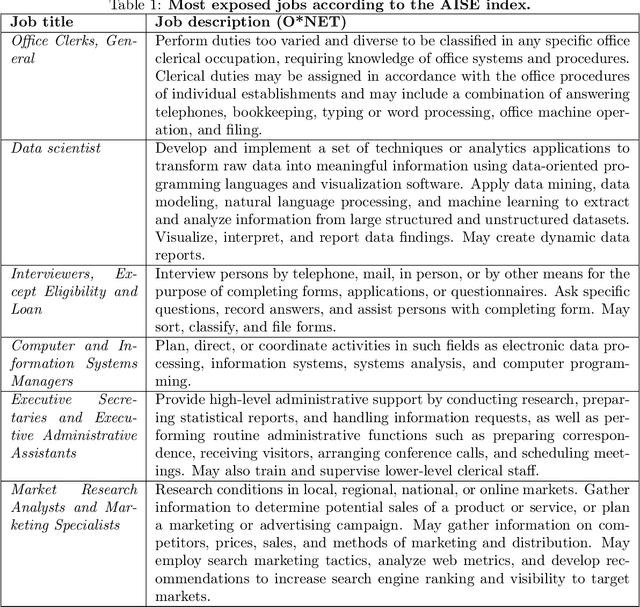
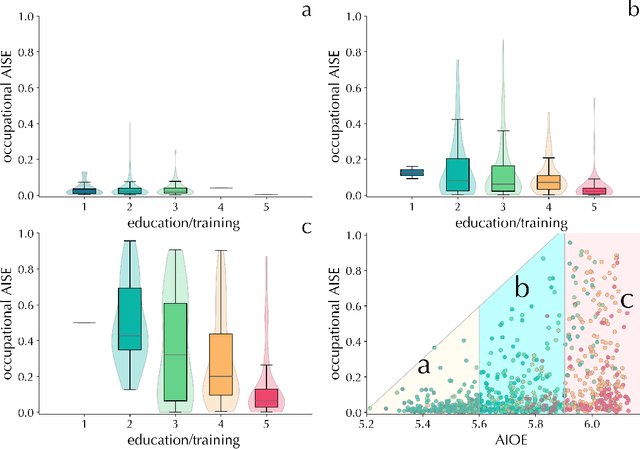
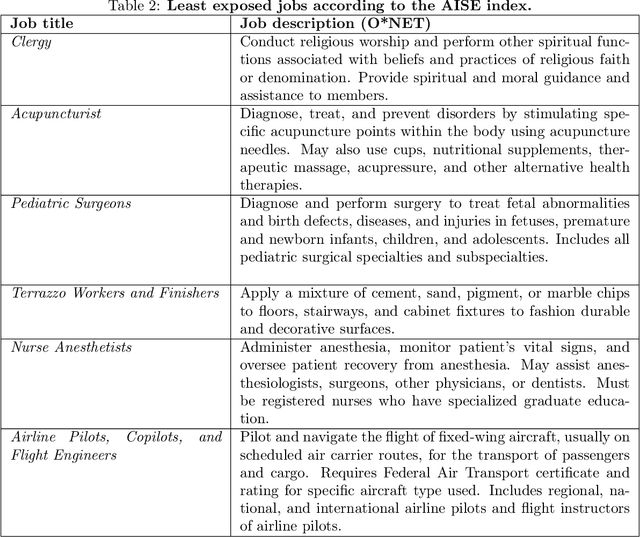
The integration of artificial intelligence (AI) into the workplace is advancing rapidly, necessitating robust metrics to evaluate its tangible impact on the labour market. Existing measures of AI occupational exposure largely focus on AI's theoretical potential to substitute or complement human labour on the basis of technical feasibility, providing limited insight into actual adoption and offering inadequate guidance for policymakers. To address this gap, we introduce the AI Startup Exposure (AISE) index-a novel metric based on occupational descriptions from O*NET and AI applications developed by startups funded by the Y Combinator accelerator. Our findings indicate that while high-skilled professions are theoretically highly exposed according to conventional metrics, they are heterogeneously targeted by startups. Roles involving routine organizational tasks-such as data analysis and office management-display significant exposure, while occupations involving tasks that are less amenable to AI automation due to ethical or high-stakes, more than feasibility, considerations -- such as judges or surgeons -- present lower AISE scores. By focusing on venture-backed AI applications, our approach offers a nuanced perspective on how AI is reshaping the labour market. It challenges the conventional assumption that high-skilled jobs uniformly face high AI risks, highlighting instead the role of today's AI players' societal desirability-driven and market-oriented choices as critical determinants of AI exposure. Contrary to fears of widespread job displacement, our findings suggest that AI adoption will be gradual and shaped by social factors as much as by the technical feasibility of AI applications. This framework provides a dynamic, forward-looking tool for policymakers and stakeholders to monitor AI's evolving impact and navigate the changing labour landscape.
Which products activate a product? An explainable machine learning approach
Dec 05, 2022Tree-based machine learning algorithms provide the most precise assessment of the feasibility for a country to export a target product given its export basket. However, the high number of parameters involved prevents a straightforward interpretation of the results and, in turn, the explainability of policy indications. In this paper, we propose a procedure to statistically validate the importance of the products used in the feasibility assessment. In this way, we are able to identify which products, called explainers, significantly increase the probability to export a target product in the near future. The explainers naturally identify a low dimensional representation, the Feature Importance Product Space, that enhances the interpretability of the recommendations and provides out-of-sample forecasts of the export baskets of countries. Interestingly, we detect a positive correlation between the complexity of a product and the complexity of its explainers.
A Bayesian approach to translators' reliability assessment
Apr 12, 2022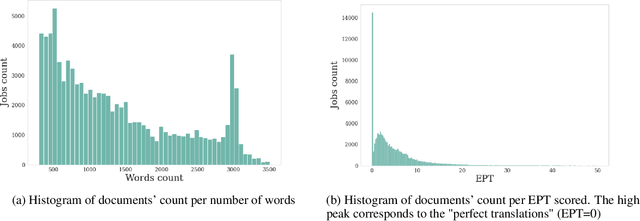
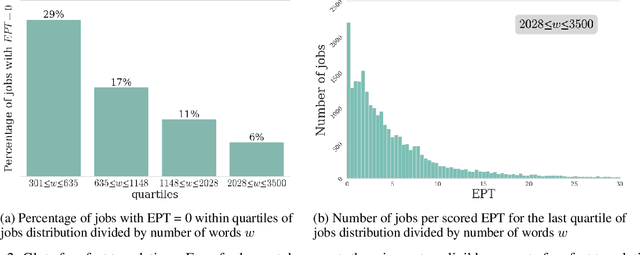
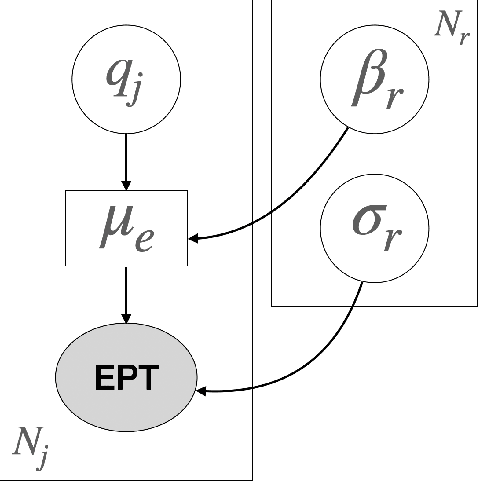
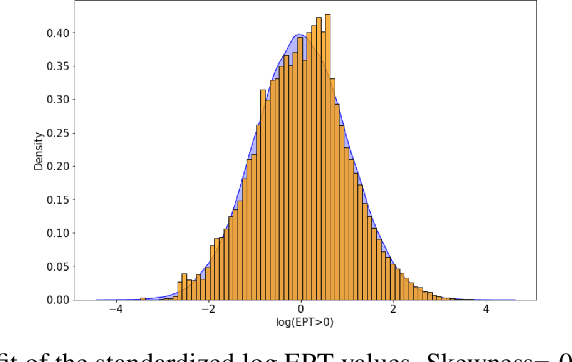
Translation Quality Assessment (TQA) is a process conducted by human translators and is widely used, both for estimating the performance of (increasingly used) Machine Translation, and for finding an agreement between translation providers and their customers. While translation scholars are aware of the importance of having a reliable way to conduct the TQA process, it seems that there is limited literature that tackles the issue of reliability with a quantitative approach. In this work, we consider the TQA as a complex process from the point of view of physics of complex systems and approach the reliability issue from the Bayesian paradigm. Using a dataset of translation quality evaluations (in the form of error annotations), produced entirely by the Professional Translation Service Provider Translated SRL, we compare two Bayesian models that parameterise the following features involved in the TQA process: the translation difficulty, the characteristics of the translators involved in producing the translation, and of those assessing its quality - the reviewers. We validate the models in an unsupervised setting and show that it is possible to get meaningful insights into translators even with just one review per translation; subsequently, we extract information like translators' skills and reviewers' strictness, as well as their consistency in their respective roles. Using this, we show that the reliability of reviewers cannot be taken for granted even in the case of expert translators: a translator's expertise can induce a cognitive bias when reviewing a translation produced by another translator. The most expert translators, however, are characterised by the highest level of consistency, both in translating and in assessing the translation quality.
Product Progression: a machine learning approach to forecasting industrial upgrading
May 31, 2021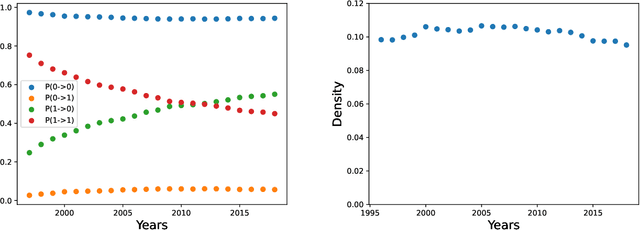
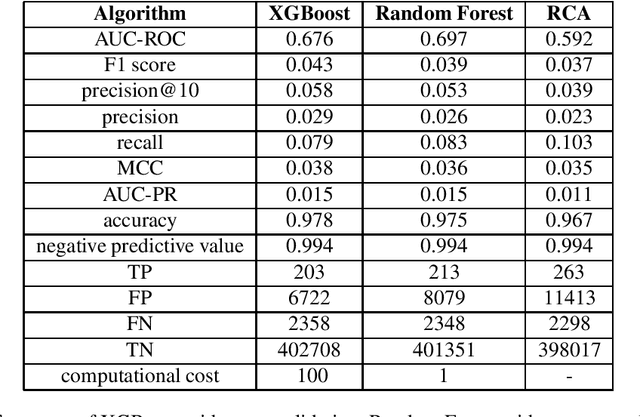
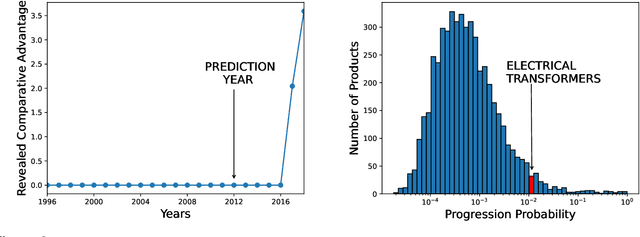
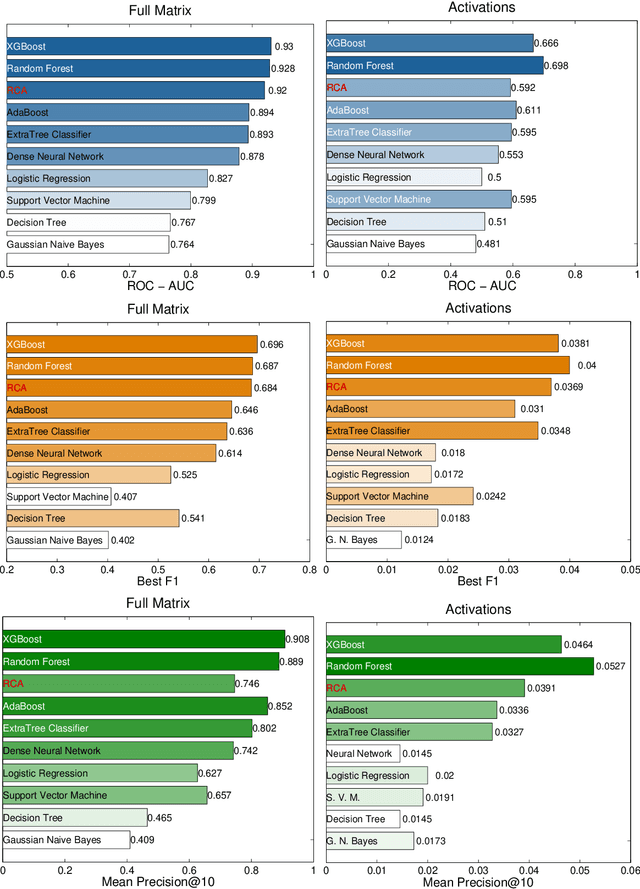
Economic complexity methods, and in particular relatedness measures, lack a systematic evaluation and comparison framework. We argue that out-of-sample forecast exercises should play this role, and we compare various machine learning models to set the prediction benchmark. We find that the key object to forecast is the activation of new products, and that tree-based algorithms clearly overperform both the quite strong auto-correlation benchmark and the other supervised algorithms. Interestingly, we find that the best results are obtained in a cross-validation setting, when data about the predicted country was excluded from the training set. Our approach has direct policy implications, providing a quantitative and scientifically tested measure of the feasibility of introducing a new product in a given country.