 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFood Pairing Unveiled: Exploring Recipe Creation Dynamics through Recommender Systems
Jun 21, 2024In the early 2000s, renowned chef Heston Blumenthal formulated his "food pairing" hypothesis, positing that if foods share many flavor compounds, then they tend to taste good when eaten together. In 2011, Ahn et al. conducted a study using a dataset of recipes, ingredients, and flavor compounds, finding that, in Western cuisine, ingredients in recipes often share more flavor compounds than expected by chance, indicating a natural tendency towards food pairing. Building upon Ahn's research, our work applies state-of-the-art collaborative filtering techniques to the dataset, providing a tool that can recommend new foods to add in recipes, retrieve missing ingredients and advise against certain combinations. We create our recommender in two ways, by taking into account ingredients appearances in recipes or shared flavor compounds between foods. While our analysis confirms the existence of food pairing, the recipe-based recommender performs significantly better than the flavor-based one, leading to the conclusion that food pairing is just one of the principles to take into account when creating recipes. Furthermore, and more interestingly, we find that food pairing in data is mostly due to trivial couplings of very similar ingredients, leading to a reconsideration of its current role in recipes, from being an already existing feature to a key to open up new scenarios in gastronomy. Our flavor-based recommender can thus leverage this novel concept and provide a new tool to lead culinary innovation.
Which products activate a product? An explainable machine learning approach
Dec 05, 2022Tree-based machine learning algorithms provide the most precise assessment of the feasibility for a country to export a target product given its export basket. However, the high number of parameters involved prevents a straightforward interpretation of the results and, in turn, the explainability of policy indications. In this paper, we propose a procedure to statistically validate the importance of the products used in the feasibility assessment. In this way, we are able to identify which products, called explainers, significantly increase the probability to export a target product in the near future. The explainers naturally identify a low dimensional representation, the Feature Importance Product Space, that enhances the interpretability of the recommendations and provides out-of-sample forecasts of the export baskets of countries. Interestingly, we detect a positive correlation between the complexity of a product and the complexity of its explainers.
Sapling Similarity outperforms other local similarity metrics in collaborative filtering
Oct 13, 2022

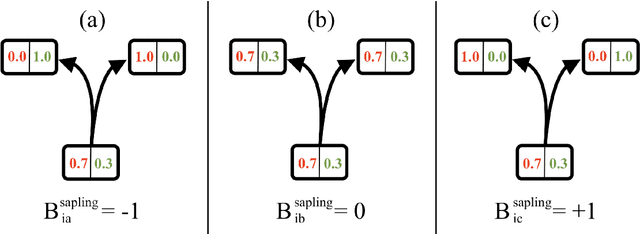

Many bipartite networks describe systems where a link represents a relation between a user and an item. Measuring the similarity between either users or items is the basis of memory-based collaborative filtering, a widely used method to build a recommender system with the purpose of proposing items to users. When the edges of the network are unweighted, traditional approaches allow only positive similarity values, so neglecting the possibility and the effect of two users (or two items) being very dissimilar. Here we propose a method to compute similarity that allows also negative values, the Sapling Similarity. The key idea is to look at how the information that a user is connected to an item influences our prior estimation of the probability that another user is connected to the same item: if it is reduced, then the similarity between the two users will be negative, otherwise it will be positive. Using different datasets, we show that the Sapling Similarity outperforms other similarity metrics when it is used to recommend new items to users.
Firm-based relatedness using machine learning
Feb 01, 2022
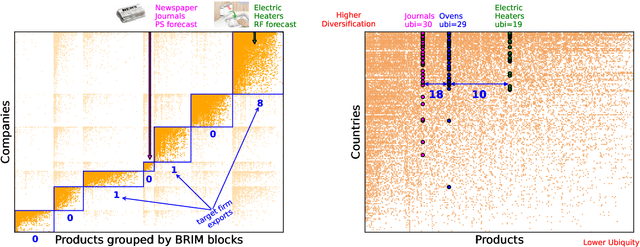
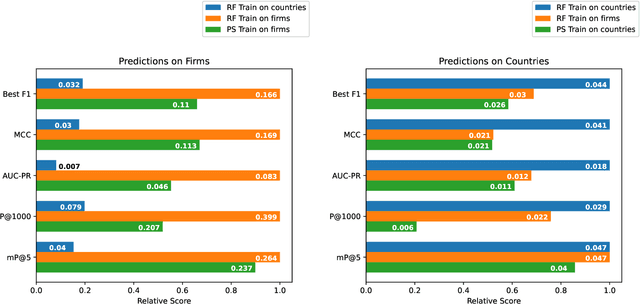
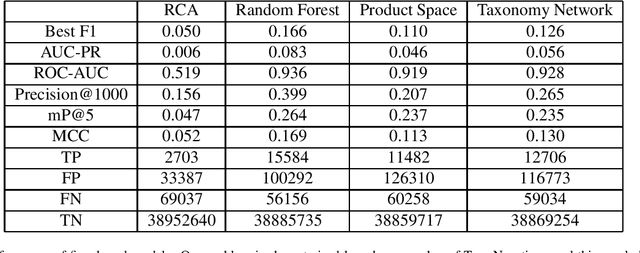
The relatedness between an economic actor (for instance a country, or a firm) and a product is a measure of the feasibility of that economic activity. As such, it is a driver for investments both at a private and institutional level. Traditionally, relatedness is measured using complex networks approaches derived by country-level co-occurrences. In this work, we compare complex networks and machine learning algorithms trained on both country and firm-level data. In order to quantitatively compare the different measures of relatedness, we use them to predict the future exports at country and firm-level, assuming that more related products have higher likelihood to be exported in the near future. Our results show that relatedness is scale-dependent: the best assessments are obtained by using machine learning on the same typology of data one wants to predict. Moreover, while relatedness measures based on country data are not suitable for firms, firm-level data are quite informative also to predict the development of countries. In this sense, models built on firm data provide a better assessment of relatedness with respect to country-level data. We also discuss the effect of using community detection algorithms and parameter optimization, finding that a partition into a higher number of blocks decreases the computational time while maintaining a prediction performance that is well above the network based benchmarks.
Product Progression: a machine learning approach to forecasting industrial upgrading
May 31, 2021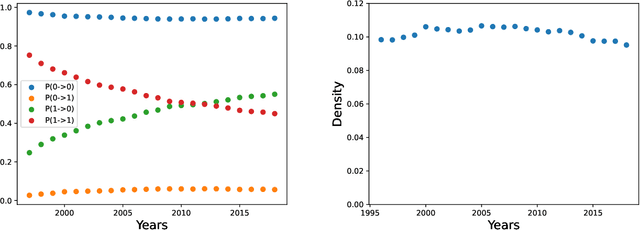
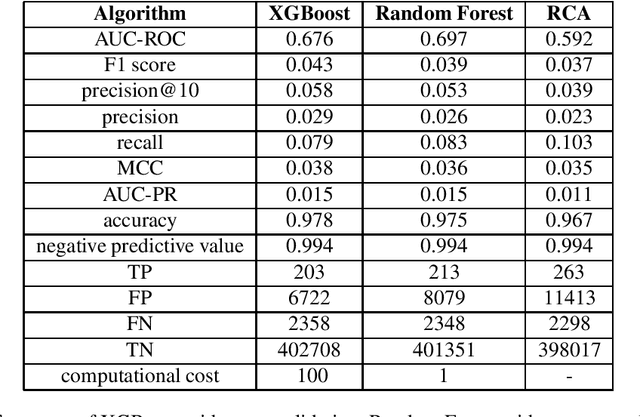
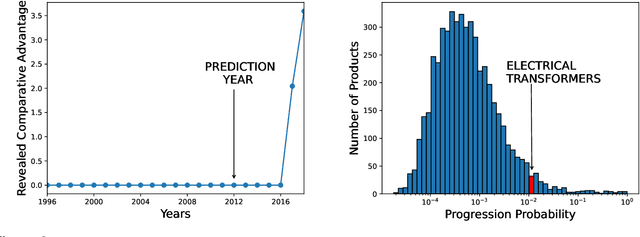
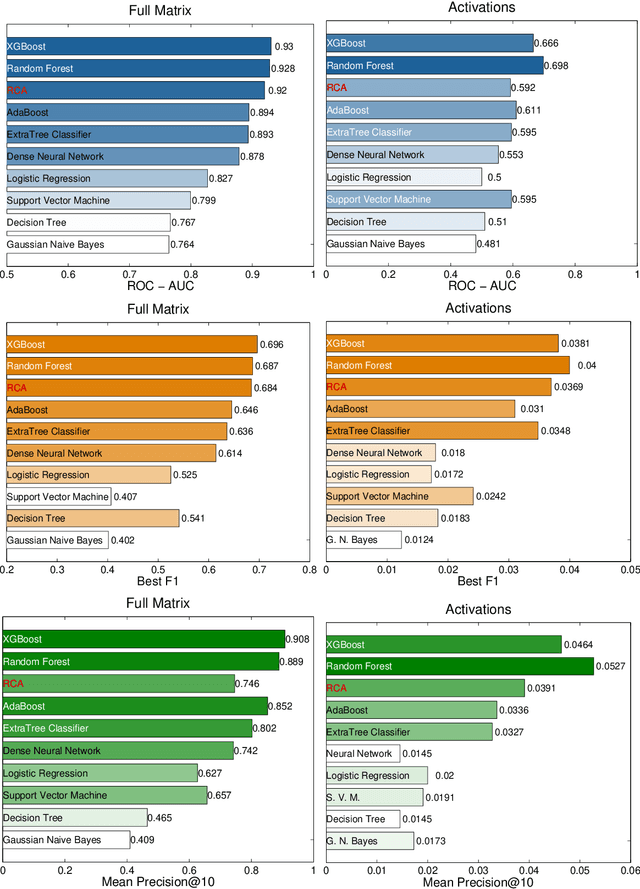
Economic complexity methods, and in particular relatedness measures, lack a systematic evaluation and comparison framework. We argue that out-of-sample forecast exercises should play this role, and we compare various machine learning models to set the prediction benchmark. We find that the key object to forecast is the activation of new products, and that tree-based algorithms clearly overperform both the quite strong auto-correlation benchmark and the other supervised algorithms. Interestingly, we find that the best results are obtained in a cross-validation setting, when data about the predicted country was excluded from the training set. Our approach has direct policy implications, providing a quantitative and scientifically tested measure of the feasibility of introducing a new product in a given country.