 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian approach to translators' reliability assessment
Apr 12, 2022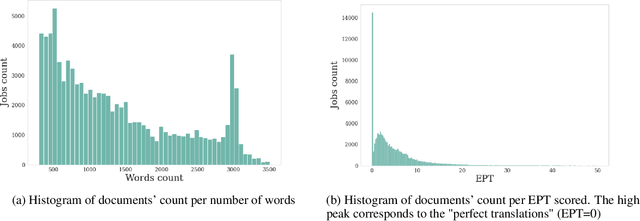
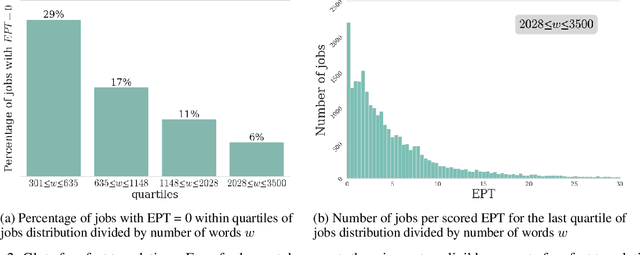
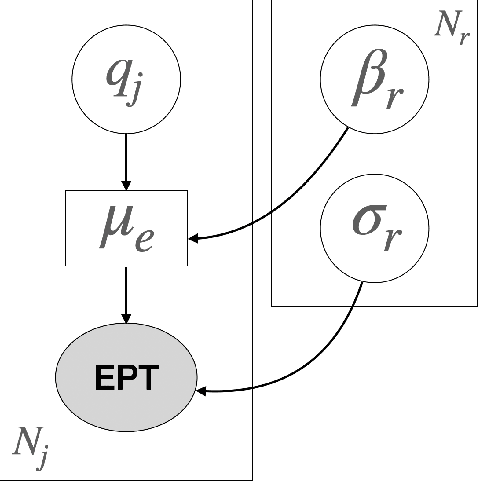
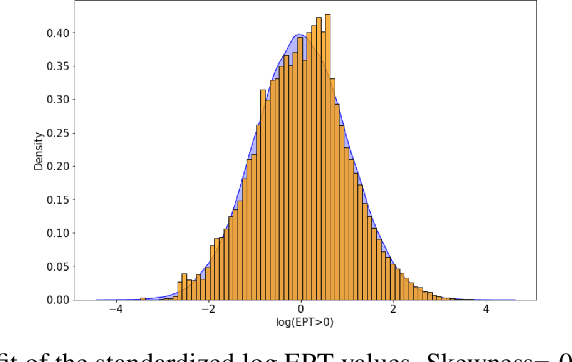
Translation Quality Assessment (TQA) is a process conducted by human translators and is widely used, both for estimating the performance of (increasingly used) Machine Translation, and for finding an agreement between translation providers and their customers. While translation scholars are aware of the importance of having a reliable way to conduct the TQA process, it seems that there is limited literature that tackles the issue of reliability with a quantitative approach. In this work, we consider the TQA as a complex process from the point of view of physics of complex systems and approach the reliability issue from the Bayesian paradigm. Using a dataset of translation quality evaluations (in the form of error annotations), produced entirely by the Professional Translation Service Provider Translated SRL, we compare two Bayesian models that parameterise the following features involved in the TQA process: the translation difficulty, the characteristics of the translators involved in producing the translation, and of those assessing its quality - the reviewers. We validate the models in an unsupervised setting and show that it is possible to get meaningful insights into translators even with just one review per translation; subsequently, we extract information like translators' skills and reviewers' strictness, as well as their consistency in their respective roles. Using this, we show that the reliability of reviewers cannot be taken for granted even in the case of expert translators: a translator's expertise can induce a cognitive bias when reviewing a translation produced by another translator. The most expert translators, however, are characterised by the highest level of consistency, both in translating and in assessing the translation quality.