 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConlangCrafter: Constructing Languages with a Multi-Hop LLM Pipeline
Aug 08, 2025Constructed languages (conlangs) such as Esperanto and Quenya have played diverse roles in art, philosophy, and international communication. Meanwhile, large-scale foundation models have revolutionized creative generation in text, images, and beyond. In this work, we leverage modern LLMs as computational creativity aids for end-to-end conlang creation. We introduce ConlangCrafter, a multi-hop pipeline that decomposes language design into modular stages -- phonology, morphology, syntax, lexicon generation, and translation. At each stage, our method leverages LLMs' meta-linguistic reasoning capabilities, injecting randomness to encourage diversity and leveraging self-refinement feedback to encourage consistency in the emerging language description. We evaluate ConlangCrafter on metrics measuring coherence and typological diversity, demonstrating its ability to produce coherent and varied conlangs without human linguistic expertise.
CiwaGAN: Articulatory information exchange
Sep 14, 2023



Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
Large language models and linguistic recursion
Jun 12, 2023Recursion is one of the hallmarks of human language. While many design features of language have been shown to exist in animal communication systems, recursion has not. Previous research shows that GPT-4 is the first large language model (LLM) to exhibit metalinguistic abilities (Begu\v{s}, D\k{a}bkowski, and Rhodes 2023). Here, we propose several prompt designs aimed at eliciting and analyzing recursive behavior in LLMs, both linguistic and non-linguistic. We demonstrate that when explicitly prompted, GPT-4 can both produce and analyze recursive structures. Thus, we present one of the first studies investigating whether meta-linguistic awareness of recursion -- a uniquely human cognitive property -- can emerge in transformers with a high number of parameters such as GPT-4.
Basic syntax from speech: Spontaneous concatenation in unsupervised deep neural networks
May 02, 2023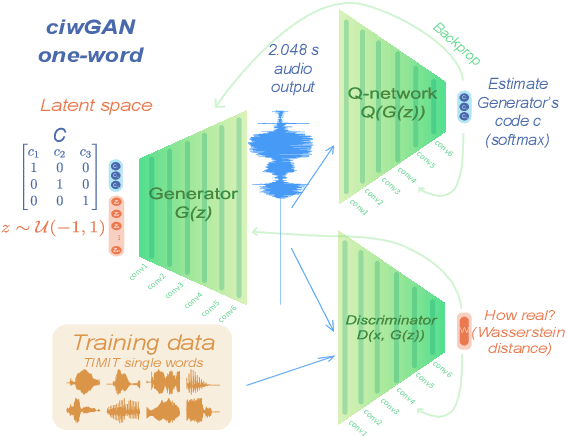

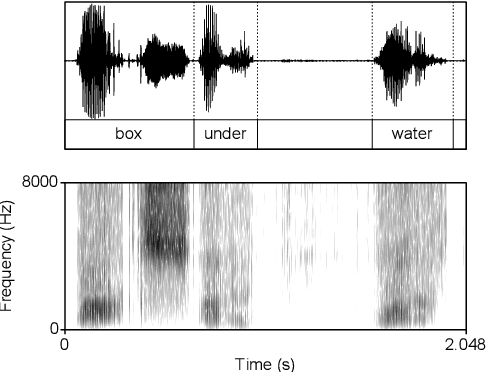
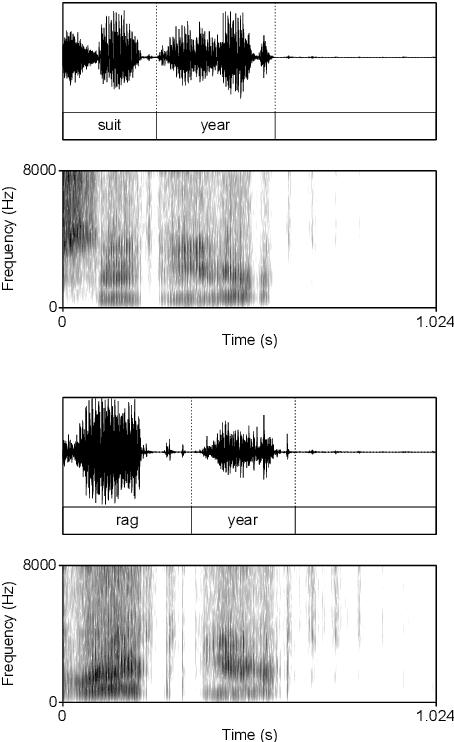
Computational models of syntax are predominantly text-based. Here we propose that basic syntax can be modeled directly from raw speech in a fully unsupervised way. We focus on one of the most ubiquitous and basic properties of syntax -- concatenation. We introduce spontaneous concatenation: a phenomenon where convolutional neural networks (CNNs) trained on acoustic recordings of individual words start generating outputs with two or even three words concatenated without ever accessing data with multiple words in the input. Additionally, networks trained on two words learn to embed words into novel unobserved word combinations. To our knowledge, this is a previously unreported property of CNNs trained on raw speech in the Generative Adversarial Network setting and has implications both for our understanding of how these architectures learn as well as for modeling syntax and its evolution from raw acoustic inputs.
Large Linguistic Models: Analyzing theoretical linguistic abilities of LLMs
May 01, 2023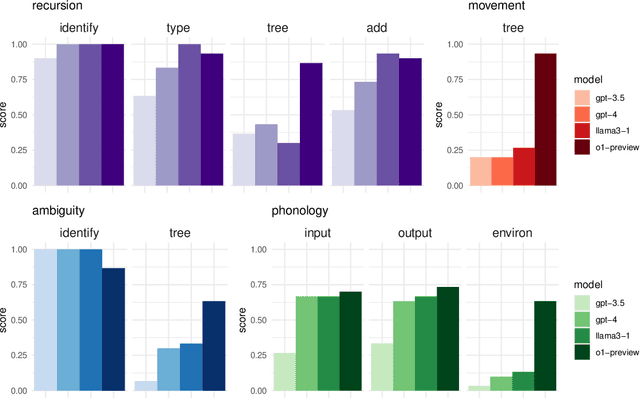
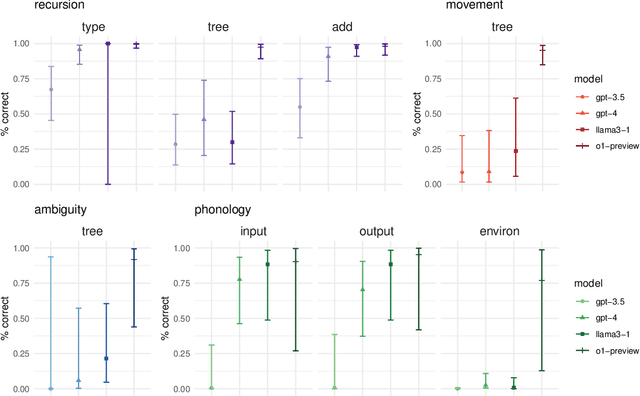
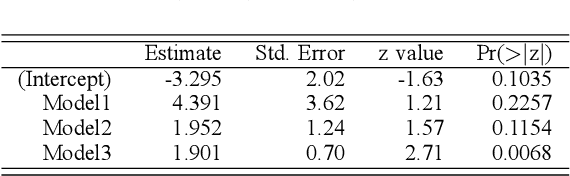
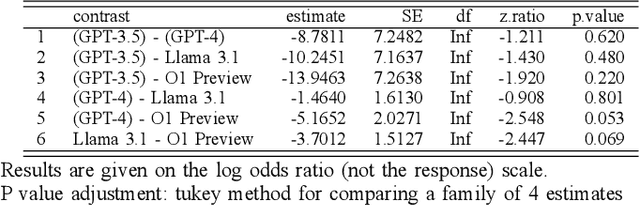
The performance of large language models (LLMs) has recently improved to the point where the models can generate valid and coherent meta-linguistic analyses of data. This paper illustrates a vast potential for analyses of the meta-linguistic abilities of large language models. LLMs are primarily trained on language data in the form of text; analyzing their meta-linguistic abilities is informative both for our understanding of the general capabilities of LLMs as well as for models of linguistics. In this paper, we propose several types of experiments and prompt designs that allow us to analyze the ability of GPT-4 to generate meta-linguistic analyses. We focus on three linguistics subfields with formalisms that allow for a detailed analysis of GPT-4's theoretical capabilities: theoretical syntax, phonology, and semantics. We identify types of experiments, provide general guidelines, discuss limitations, and offer future directions for this research program.
AI-assisted coding: Experiments with GPT-4
Apr 25, 2023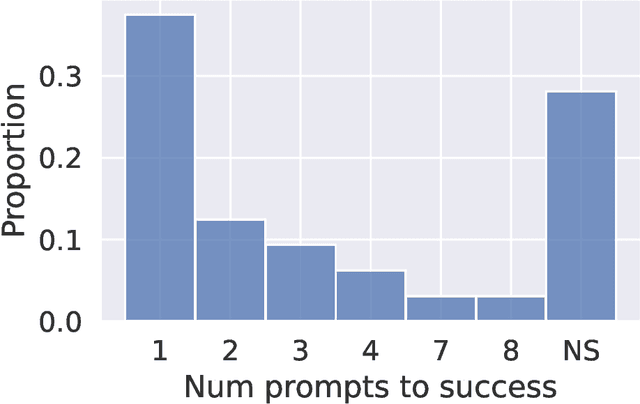

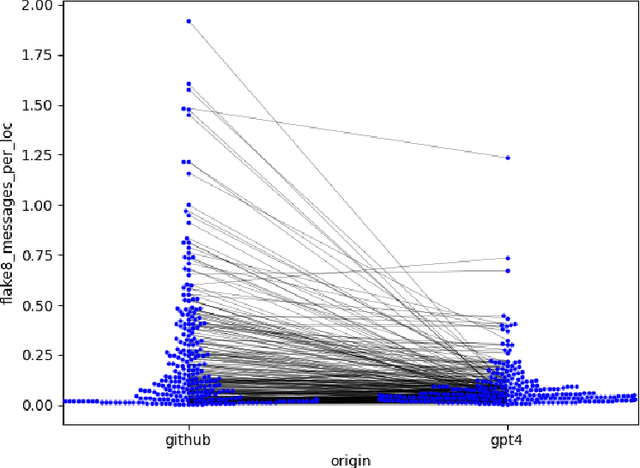
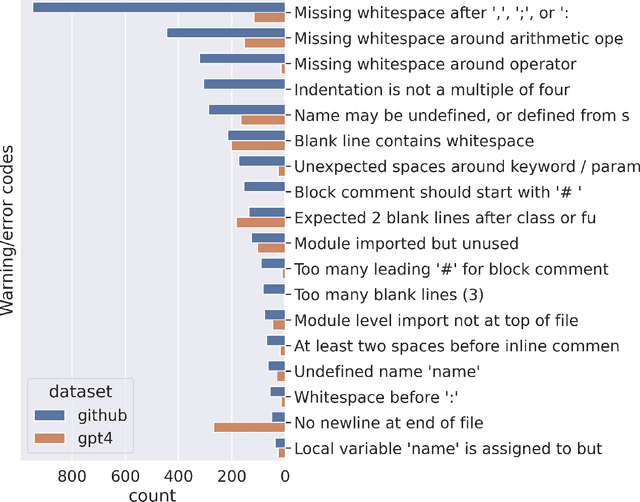
Artificial intelligence (AI) tools based on large language models have acheived human-level performance on some computer programming tasks. We report several experiments using GPT-4 to generate computer code. These experiments demonstrate that AI code generation using the current generation of tools, while powerful, requires substantial human validation to ensure accurate performance. We also demonstrate that GPT-4 refactoring of existing code can significantly improve that code along several established metrics for code quality, and we show that GPT-4 can generate tests with substantial coverage, but that many of the tests fail when applied to the associated code. These findings suggest that while AI coding tools are very powerful, they still require humans in the loop to ensure validity and accuracy of the results.
Approaching an unknown communication system by latent space exploration and causal inference
Mar 20, 2023

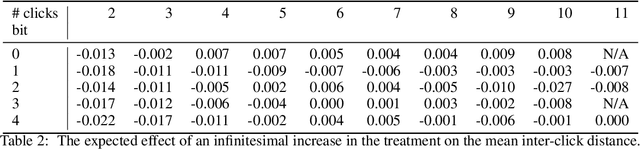

This paper proposes a methodology for discovering meaningful properties in data by exploring the latent space of unsupervised deep generative models. We combine manipulation of individual latent variables to extreme values outside the training range with methods inspired by causal inference into an approach we call causal disentanglement with extreme values (CDEV) and show that this approach yields insights for model interpretability. Using this technique, we can infer what properties of unknown data the model encodes as meaningful. We apply the methodology to test what is meaningful in the communication system of sperm whales, one of the most intriguing and understudied animal communication systems. We train a network that has been shown to learn meaningful representations of speech and test whether we can leverage such unsupervised learning to decipher the properties of another vocal communication system for which we have no ground truth. The proposed technique suggests that sperm whales encode information using the number of clicks in a sequence, the regularity of their timing, and audio properties such as the spectral mean and the acoustic regularity of the sequences. Some of these findings are consistent with existing hypotheses, while others are proposed for the first time. We also argue that our models uncover rules that govern the structure of communication units in the sperm whale communication system and apply them while generating innovative data not shown during training. This paper suggests that an interpretation of the outputs of deep neural networks with causal methodology can be a viable strategy for approaching data about which little is known and presents another case of how deep learning can limit the hypothesis space. Finally, the proposed approach combining latent space manipulation and causal inference can be extended to other architectures and arbitrary datasets.
Articulation GAN: Unsupervised modeling of articulatory learning
Oct 27, 2022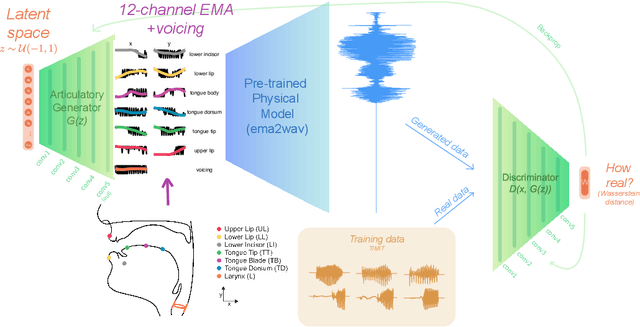

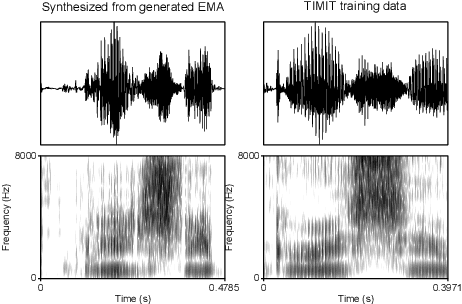
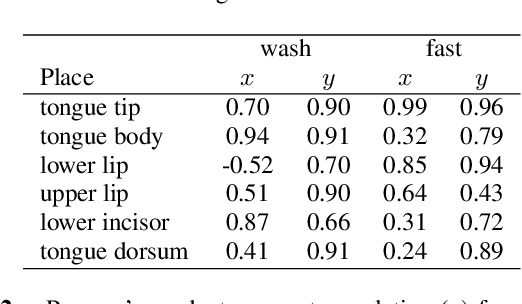
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We propose a new unsupervised generative model of speech production/synthesis that includes articulatory representations and thus more closely mimics human speech production. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm. The Articulatory Generator needs to learn to generate articulatory representations (electromagnetic articulography or EMA) in a fully unsupervised manner without ever accessing EMA data. A separate pre-trained physical model (ema2wav) then transforms the generated EMA representations to speech waveforms, which get sent to the Discriminator for evaluation. Articulatory analysis of the generated EMA representations suggests that the network learns to control articulators in a manner that closely follows human articulators during speech production. Acoustic analysis of the outputs suggest that the network learns to generate words that are part of training data as well as novel innovative words that are absent from training data. Our proposed architecture thus allows modeling of articulatory learning with deep neural networks from raw audio inputs in a fully unsupervised manner. We additionally discuss implications of articulatory representations for cognitive models of human language and speech technology in general.
Modeling speech recognition and synthesis simultaneously: Encoding and decoding lexical and sublexical semantic information into speech with no direct access to speech data
Mar 29, 2022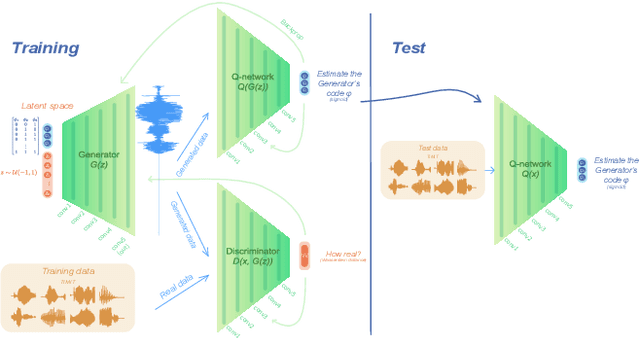
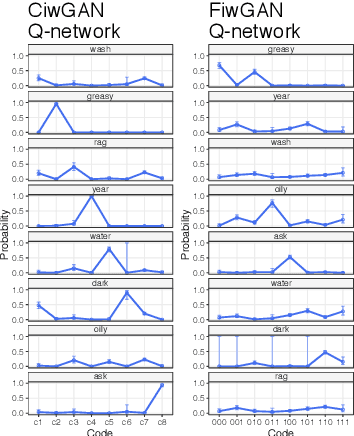
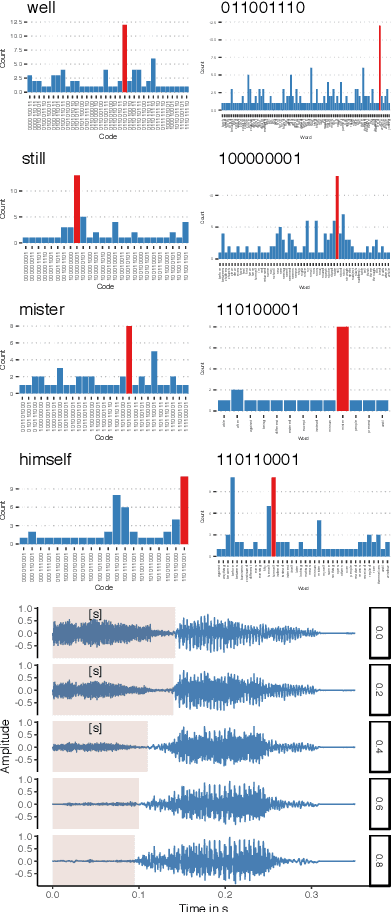
Human speakers encode information into raw speech which is then decoded by the listeners. This complex relationship between encoding (production) and decoding (perception) is often modeled separately. Here, we test how encoding and decoding of lexical semantic information can emerge automatically from raw speech in unsupervised generative deep convolutional networks that combine the production and perception principles of speech. We introduce, to our knowledge, the most challenging objective in unsupervised lexical learning: a network that must learn unique representations for lexical items with no direct access to training data. We train several models (ciwGAN and fiwGAN arXiv:2006.02951) and test how the networks classify acoustic lexical items in unobserved test data. Strong evidence in favor of lexical learning and a causal relationship between latent codes and meaningful sublexical units emerge. The architecture that combines the production and perception principles is thus able to learn to decode unique information from raw acoustic data without accessing real training data directly. We propose a technique to explore lexical (holistic) and sublexical (featural) learned representations in the classifier network. The results bear implications for unsupervised speech technology, as well as for unsupervised semantic modeling as language models increasingly bypass text and operate from raw acoustics.
Interpreting intermediate convolutional layers in unsupervised acoustic word classification
Oct 05, 2021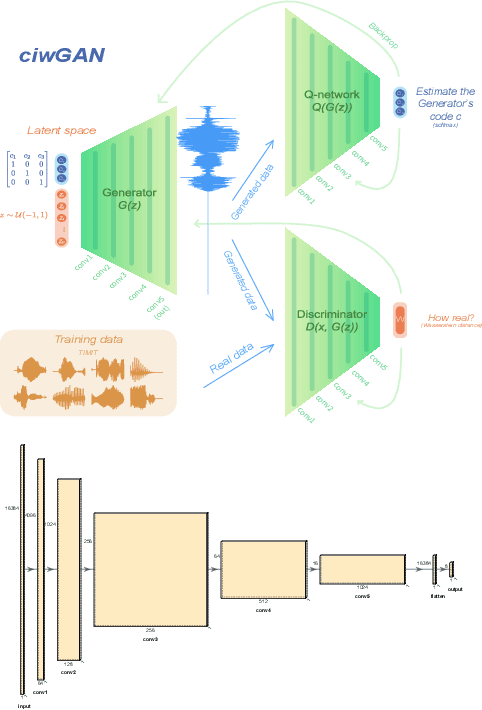
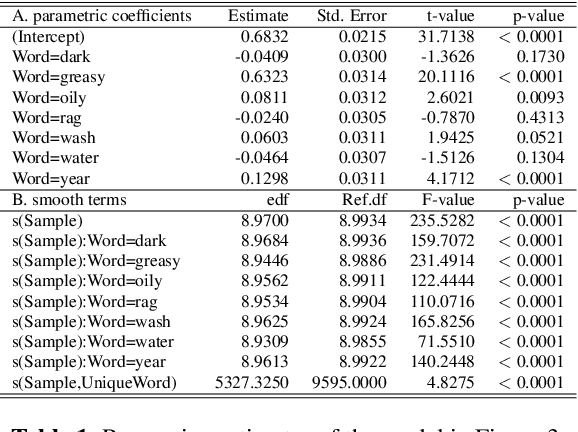
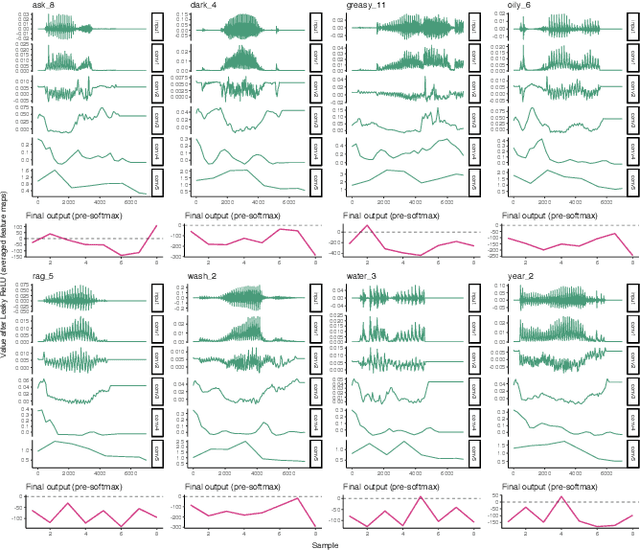
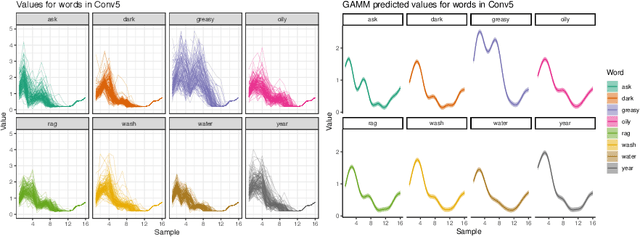
Understanding how deep convolutional neural networks classify data has been subject to extensive research. This paper proposes a technique to visualize and interpret intermediate layers of unsupervised deep convolutional neural networks by averaging over individual feature maps in each convolutional layer and inferring underlying distributions of words with non-linear regression techniques. A GAN-based architecture (ciwGAN arXiv:2006.02951) that includes three convolutional networks (a Generator, a Discriminator, and a classifier) was trained on unlabeled sliced lexical items from TIMIT. The training results in a deep convolutional network that learns to classify words into discrete classes only from the requirement of the Generator to output informative data. The classifier network has no access to the training data -- only to the generated data -- which means lexical learning needs to emerge in a fully unsupervised manner. We propose a technique to visualize individual convolutional layers in the classifier that yields highly informative time-series data for each convolutional layer and apply it to unobserved test data. Using non-linear regression, we infer underlying distributions for each word which allows us to analyze both absolute values and shapes of individual words at different convolutional layers as well as perform hypothesis testing on their acoustic properties. The technique also allows us to tests individual phone contrasts and how they are represented at each layer.