 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeanTutor: Towards a Verified AI Mathematical Proof Tutor
Jan 24, 2026This paper considers the development of an AI-based provably-correct mathematical proof tutor. While Large Language Models (LLMs) allow seamless communication in natural language, they are error prone. Theorem provers such as Lean allow for provable-correctness, but these are hard for students to learn. We present a proof-of-concept system (LeanTutor) by combining the complementary strengths of LLMs and theorem provers. LeanTutor is composed of three modules: (i) an autoformalizer/proof-checker, (ii) a next-step generator, and (iii) a natural language feedback generator. To evaluate the system, we introduce PeanoBench, a dataset of 371 Peano Arithmetic proofs in human-written natural language and formal language, derived from the Natural Numbers Game.
Enhancing Fault-Tolerant Space Computing: Guidance Navigation and Control (GNC) and Landing Vision System (LVS) Implementations on Next-Gen Multi-Core Processors
Nov 06, 2025Future planetary exploration missions demand high-performance, fault-tolerant computing to enable autonomous Guidance, Navigation, and Control (GNC) and Lander Vision System (LVS) operations during Entry, Descent, and Landing (EDL). This paper evaluates the deployment of GNC and LVS algorithms on next-generation multi-core processors--HPSC, Snapdragon VOXL2, and AMD Xilinx Versal--demonstrating up to 15x speedup for LVS image processing and over 250x speedup for Guidance for Fuel-Optimal Large Divert (GFOLD) trajectory optimization compared to legacy spaceflight hardware. To ensure computational reliability, we present ARBITER (Asynchronous Redundant Behavior Inspection for Trusted Execution and Recovery), a Multi-Core Voting (MV) mechanism that performs real-time fault detection and correction across redundant cores. ARBITER is validated in both static optimization tasks (GFOLD) and dynamic closed-loop control (Attitude Control System). A fault injection study further identifies the gradient computation stage in GFOLD as the most sensitive to bit-level errors, motivating selective protection strategies and vector-based output arbitration. This work establishes a scalable and energy-efficient architecture for future missions, including Mars Sample Return, Enceladus Orbilander, and Ceres Sample Return, where onboard autonomy, low latency, and fault resilience are critical.
LeanTutor: A Formally-Verified AI Tutor for Mathematical Proofs
Jun 10, 2025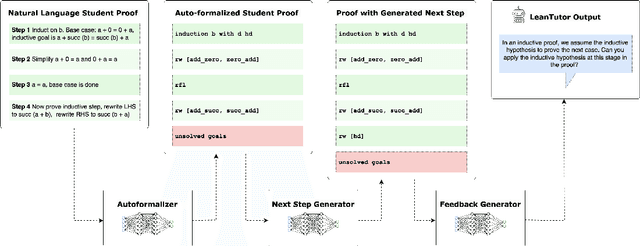

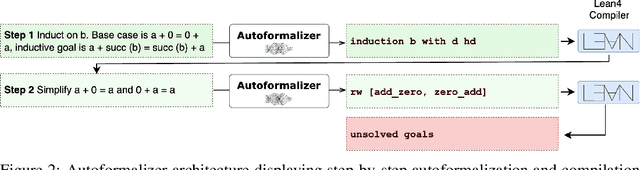
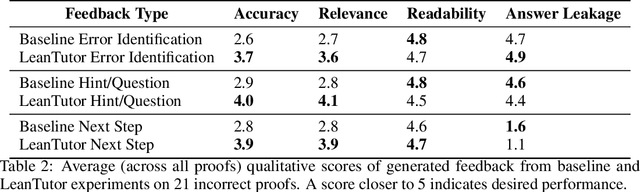
We present LeanTutor, a Large Language Model (LLM)-based tutoring system for math proofs. LeanTutor interacts with the student in natural language, formally verifies student-written math proofs in Lean, generates correct next steps, and provides the appropriate instructional guidance. LeanTutor is composed of three modules: (i) an autoformalizer/proof-checker, (ii) a next-step generator, and (iii) a natural language feedback generator. The first module faithfully autoformalizes student proofs into Lean and verifies proof accuracy via successful code compilation. If the proof has an error, the incorrect step is identified. The next-step generator module outputs a valid next Lean tactic for incorrect proofs via LLM-based candidate generation and proof search. The feedback generator module leverages Lean data to produce a pedagogically-motivated natural language hint for the student user. To evaluate our system, we introduce PeanoBench, a human-written dataset derived from the Natural Numbers Game, consisting of 371 Peano Arithmetic proofs, where each natural language proof step is paired with the corresponding logically equivalent tactic in Lean. The Autoformalizer correctly formalizes 57% of tactics in correct proofs and accurately identifies the incorrect step in 30% of incorrect proofs. In generating natural language hints for erroneous proofs, LeanTutor outperforms a simple baseline on accuracy and relevance metrics.
CiwaGAN: Articulatory information exchange
Sep 14, 2023



Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
Basic syntax from speech: Spontaneous concatenation in unsupervised deep neural networks
May 02, 2023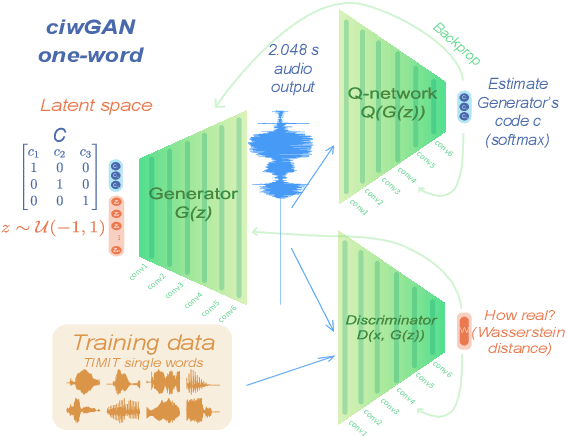

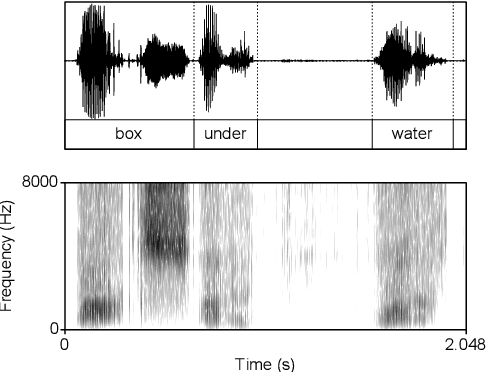
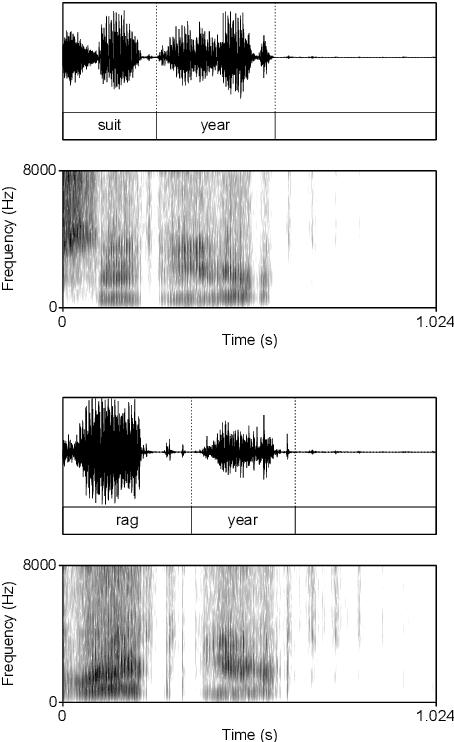
Computational models of syntax are predominantly text-based. Here we propose that basic syntax can be modeled directly from raw speech in a fully unsupervised way. We focus on one of the most ubiquitous and basic properties of syntax -- concatenation. We introduce spontaneous concatenation: a phenomenon where convolutional neural networks (CNNs) trained on acoustic recordings of individual words start generating outputs with two or even three words concatenated without ever accessing data with multiple words in the input. Additionally, networks trained on two words learn to embed words into novel unobserved word combinations. To our knowledge, this is a previously unreported property of CNNs trained on raw speech in the Generative Adversarial Network setting and has implications both for our understanding of how these architectures learn as well as for modeling syntax and its evolution from raw acoustic inputs.
AI-assisted coding: Experiments with GPT-4
Apr 25, 2023

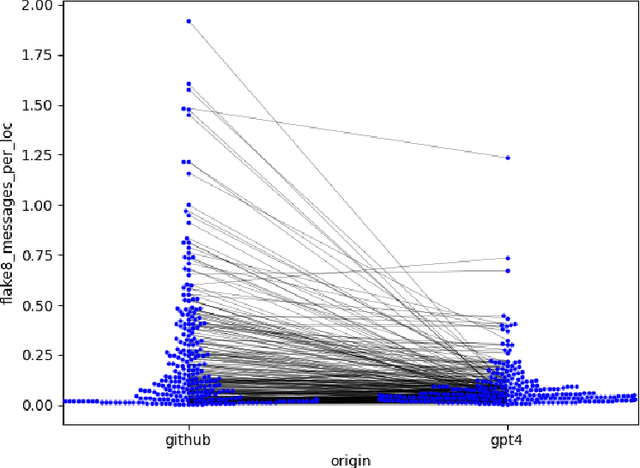
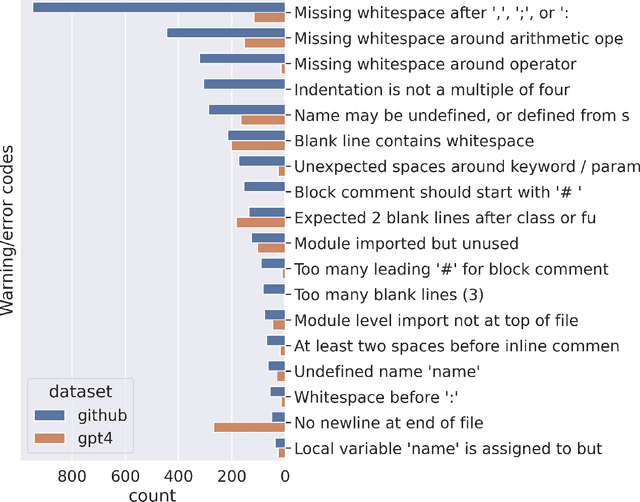
Artificial intelligence (AI) tools based on large language models have acheived human-level performance on some computer programming tasks. We report several experiments using GPT-4 to generate computer code. These experiments demonstrate that AI code generation using the current generation of tools, while powerful, requires substantial human validation to ensure accurate performance. We also demonstrate that GPT-4 refactoring of existing code can significantly improve that code along several established metrics for code quality, and we show that GPT-4 can generate tests with substantial coverage, but that many of the tests fail when applied to the associated code. These findings suggest that while AI coding tools are very powerful, they still require humans in the loop to ensure validity and accuracy of the results.
Device Image-IV Mapping using Variational Autoencoder for Inverse Design and Forward Prediction
Apr 03, 2023



This paper demonstrates the learning of the underlying device physics by mapping device structure images to their corresponding Current-Voltage (IV) characteristics using a novel framework based on variational autoencoders (VAE). Since VAE is used, domain expertise is not required and the framework can be quickly deployed on any new device and measurement. This is expected to be useful in the compact modeling of novel devices when only device cross-sectional images and electrical characteristics are available (e.g. novel emerging memory). Technology Computer-Aided Design (TCAD) generated and hand-drawn Metal-Oxide-Semiconductor (MOS) device images and noisy drain-current-gate-voltage curves (IDVG) are used for the demonstration. The framework is formed by stacking two VAEs (one for image manifold learning and one for IDVG manifold learning) which communicate with each other through the latent variables. Five independent variables with different strengths are used. It is shown that it can perform inverse design (generate a design structure for a given IDVG) and forward prediction (predict IDVG for a given structure image, which can be used for compact modeling if the image is treated as device parameters) successfully. Since manifold learning is used, the machine is shown to be robust against noise in the inputs (i.e. using hand-drawn images and noisy IDVG curves) and not confused by weak and irrelevant independent variables.
Remote estimation of geologic composition using interferometric synthetic-aperture radar in California's Central Valley
Dec 04, 2022California's Central Valley is the national agricultural center, producing 1/4 of the nation's food. However, land in the Central Valley is sinking at a rapid rate (as much as 20 cm per year) due to continued groundwater pumping. Land subsidence has a significant impact on infrastructure resilience and groundwater sustainability. In this study, we aim to identify specific regions with different temporal dynamics of land displacement and find relationships with underlying geological composition. Then, we aim to remotely estimate geologic composition using interferometric synthetic aperture radar (InSAR)-based land deformation temporal changes using machine learning techniques. We identified regions with different temporal characteristics of land displacement in that some areas (e.g., Helm) with coarser grain geologic compositions exhibited potentially reversible land deformation (elastic land compaction). We found a significant correlation between InSAR-based land deformation and geologic composition using random forest and deep neural network regression models. We also achieved significant accuracy with 1/4 sparse sampling to reduce any spatial correlations among data, suggesting that the model has the potential to be generalized to other regions for indirect estimation of geologic composition. Our results indicate that geologic composition can be estimated using InSAR-based land deformation data. In-situ measurements of geologic composition can be expensive and time consuming and may be impractical in some areas. The generalizability of the model sheds light on high spatial resolution geologic composition estimation utilizing existing measurements.
Material Prediction for Design Automation Using Graph Representation Learning
Sep 26, 2022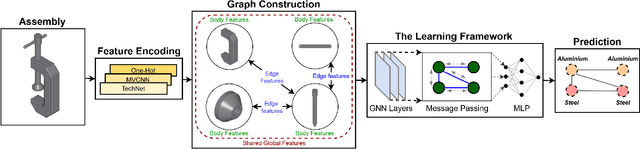

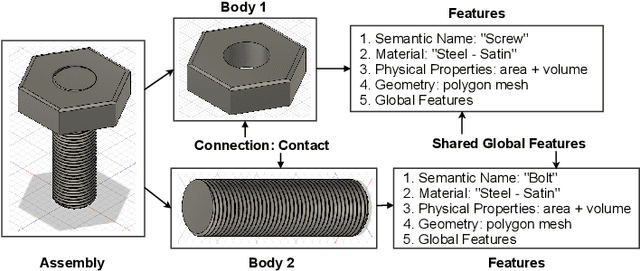
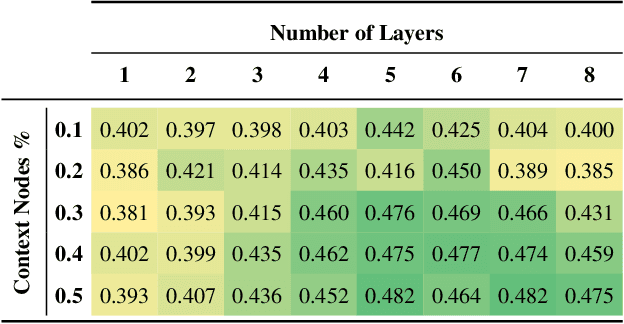
Successful material selection is critical in designing and manufacturing products for design automation. Designers leverage their knowledge and experience to create high-quality designs by selecting the most appropriate materials through performance, manufacturability, and sustainability evaluation. Intelligent tools can help designers with varying expertise by providing recommendations learned from prior designs. To enable this, we introduce a graph representation learning framework that supports the material prediction of bodies in assemblies. We formulate the material selection task as a node-level prediction task over the assembly graph representation of CAD models and tackle it using Graph Neural Networks (GNNs). Evaluations over three experimental protocols performed on the Fusion 360 Gallery dataset indicate the feasibility of our approach, achieving a 0.75 top-3 micro-f1 score. The proposed framework can scale to large datasets and incorporate designers' knowledge into the learning process. These capabilities allow the framework to serve as a recommendation system for design automation and a baseline for future work, narrowing the gap between human designers and intelligent design agents.
Neurosymbolic hybrid approach to driver collision warning
Mar 28, 2022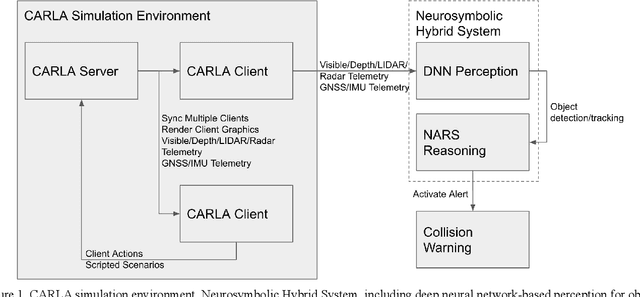

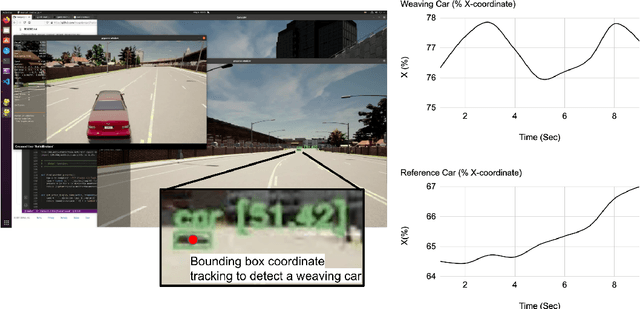

There are two main algorithmic approaches to autonomous driving systems: (1) An end-to-end system in which a single deep neural network learns to map sensory input directly into appropriate warning and driving responses. (2) A mediated hybrid recognition system in which a system is created by combining independent modules that detect each semantic feature. While some researchers believe that deep learning can solve any problem, others believe that a more engineered and symbolic approach is needed to cope with complex environments with less data. Deep learning alone has achieved state-of-the-art results in many areas, from complex gameplay to predicting protein structures. In particular, in image classification and recognition, deep learning models have achieved accuracies as high as humans. But sometimes it can be very difficult to debug if the deep learning model doesn't work. Deep learning models can be vulnerable and are very sensitive to changes in data distribution. Generalization can be problematic. It's usually hard to prove why it works or doesn't. Deep learning models can also be vulnerable to adversarial attacks. Here, we combine deep learning-based object recognition and tracking with an adaptive neurosymbolic network agent, called the Non-Axiomatic Reasoning System (NARS), that can adapt to its environment by building concepts based on perceptual sequences. We achieved an improved intersection-over-union (IOU) object recognition performance of 0.65 in the adaptive retraining model compared to IOU 0.31 in the COCO data pre-trained model. We improved the object detection limits using RADAR sensors in a simulated environment, and demonstrated the weaving car detection capability by combining deep learning-based object detection and tracking with a neurosymbolic model.