 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-assisted coding: Experiments with GPT-4
Paper and Code
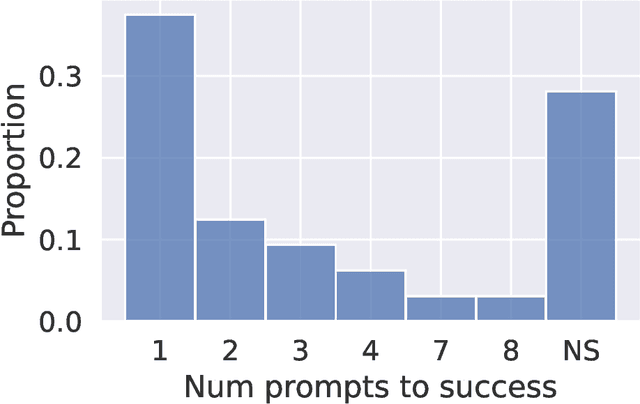

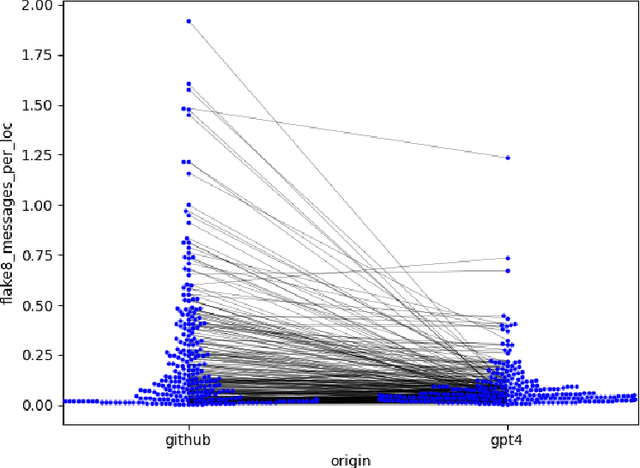
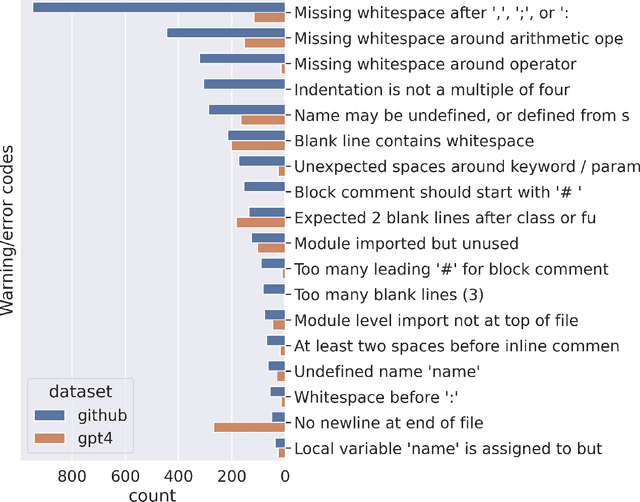
Artificial intelligence (AI) tools based on large language models have acheived human-level performance on some computer programming tasks. We report several experiments using GPT-4 to generate computer code. These experiments demonstrate that AI code generation using the current generation of tools, while powerful, requires substantial human validation to ensure accurate performance. We also demonstrate that GPT-4 refactoring of existing code can significantly improve that code along several established metrics for code quality, and we show that GPT-4 can generate tests with substantial coverage, but that many of the tests fail when applied to the associated code. These findings suggest that while AI coding tools are very powerful, they still require humans in the loop to ensure validity and accuracy of the results.