 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic hybrid approach to driver collision warning
Mar 28, 2022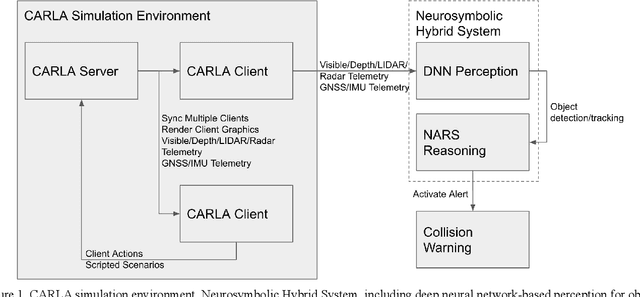

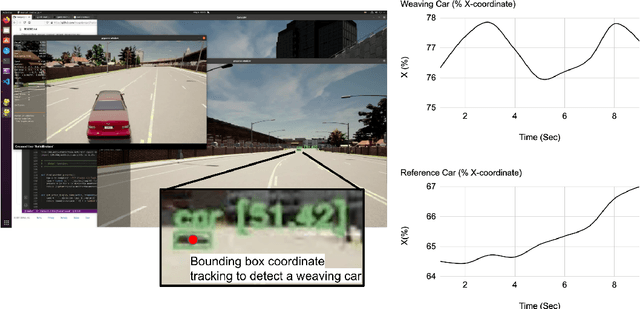

There are two main algorithmic approaches to autonomous driving systems: (1) An end-to-end system in which a single deep neural network learns to map sensory input directly into appropriate warning and driving responses. (2) A mediated hybrid recognition system in which a system is created by combining independent modules that detect each semantic feature. While some researchers believe that deep learning can solve any problem, others believe that a more engineered and symbolic approach is needed to cope with complex environments with less data. Deep learning alone has achieved state-of-the-art results in many areas, from complex gameplay to predicting protein structures. In particular, in image classification and recognition, deep learning models have achieved accuracies as high as humans. But sometimes it can be very difficult to debug if the deep learning model doesn't work. Deep learning models can be vulnerable and are very sensitive to changes in data distribution. Generalization can be problematic. It's usually hard to prove why it works or doesn't. Deep learning models can also be vulnerable to adversarial attacks. Here, we combine deep learning-based object recognition and tracking with an adaptive neurosymbolic network agent, called the Non-Axiomatic Reasoning System (NARS), that can adapt to its environment by building concepts based on perceptual sequences. We achieved an improved intersection-over-union (IOU) object recognition performance of 0.65 in the adaptive retraining model compared to IOU 0.31 in the COCO data pre-trained model. We improved the object detection limits using RADAR sensors in a simulated environment, and demonstrated the weaving car detection capability by combining deep learning-based object detection and tracking with a neurosymbolic model.
Explainability Tools Enabling Deep Learning in Future In-Situ Real-Time Planetary Explorations
Jan 15, 2022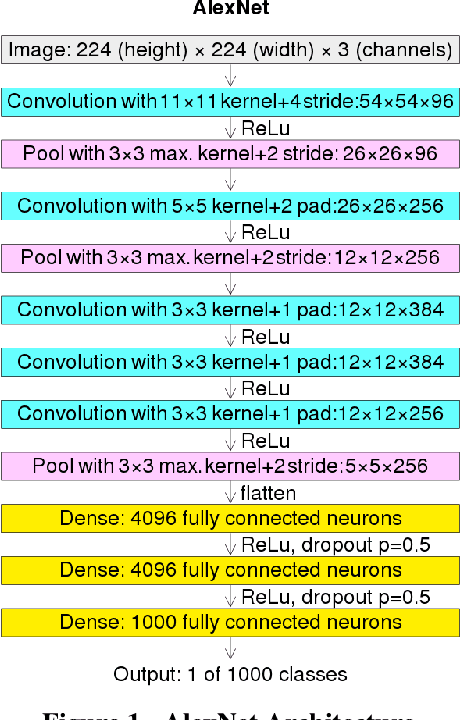
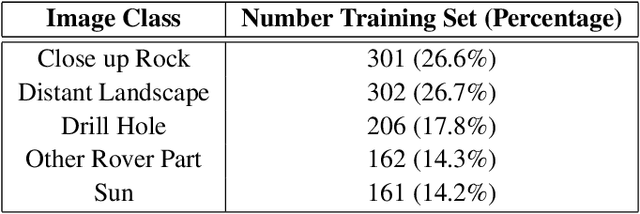


Deep learning (DL) has proven to be an effective machine learning and computer vision technique. DL-based image segmentation, object recognition and classification will aid many in-situ Mars rover tasks such as path planning and artifact recognition/extraction. However, most of the Deep Neural Network (DNN) architectures are so complex that they are considered a 'black box'. In this paper, we used integrated gradients to describe the attributions of each neuron to the output classes. It provides a set of explainability tools (ET) that opens the black box of a DNN so that the individual contribution of neurons to category classification can be ranked and visualized. The neurons in each dense layer are mapped and ranked by measuring expected contribution of a neuron to a class vote given a true image label. The importance of neurons is prioritized according to their correct or incorrect contribution to the output classes and suppression or bolstering of incorrect classes, weighted by the size of each class. ET provides an interface to prune the network to enhance high-rank neurons and remove low-performing neurons. ET technology will make DNNs smaller and more efficient for implementation in small embedded systems. It also leads to more explainable and testable DNNs that can make systems easier for Validation \& Verification. The goal of ET technology is to enable the adoption of DL in future in-situ planetary exploration missions.
Improved visible to IR image transformation using synthetic data augmentation with cycle-consistent adversarial networks
Apr 25, 2019Infrared (IR) images are essential to improve the visibility of dark or camouflaged objects. Object recognition and segmentation based on a neural network using IR images provide more accuracy and insight than color visible images. But the bottleneck is the amount of relevant IR images for training. It is difficult to collect real-world IR images for special purposes, including space exploration, military and fire-fighting applications. To solve this problem, we created color visible and IR images using a Unity-based 3D game editor. These synthetically generated color visible and IR images were used to train cycle consistent adversarial networks (CycleGAN) to convert visible images to IR images. CycleGAN has the advantage that it does not require precisely matching visible and IR pairs for transformation training. In this study, we discovered that additional synthetic data can help improve CycleGAN performance. Neural network training using real data (N = 20) performed more accurate transformations than training using real (N = 10) and synthetic (N = 10) data combinations. The result indicates that the synthetic data cannot exceed the quality of the real data. Neural network training using real (N = 10) and synthetic (N = 100) data combinations showed almost the same performance as training using real data (N = 20). At least 10 times more synthetic data than real data is required to achieve the same performance. In summary, CycleGAN is used with synthetic data to improve the IR image conversion performance of visible images.
Small Target Detection for Search and Rescue Operations using Distributed Deep Learning and Synthetic Data Generation
Apr 25, 2019It is important to find the target as soon as possible for search and rescue operations. Surveillance camera systems and unmanned aerial vehicles (UAVs) are used to support search and rescue. Automatic object detection is important because a person cannot monitor multiple surveillance screens simultaneously for 24 hours. Also, the object is often too small to be recognized by the human eye on the surveillance screen. This study used UAVs around the Port of Houston and fixed surveillance cameras to build an automatic target detection system that supports the US Coast Guard (USCG) to help find targets (e.g., person overboard). We combined image segmentation, enhancement, and convolution neural networks to reduce detection time to detect small targets. We compared the performance between the auto-detection system and the human eye. Our system detected the target within 8 seconds, but the human eye detected the target within 25 seconds. Our systems also used synthetic data generation and data augmentation techniques to improve target detection accuracy. This solution may help the search and rescue operations of the first responders in a timely manner.
Deep Neural Networks for Pattern Recognition
Sep 25, 2018

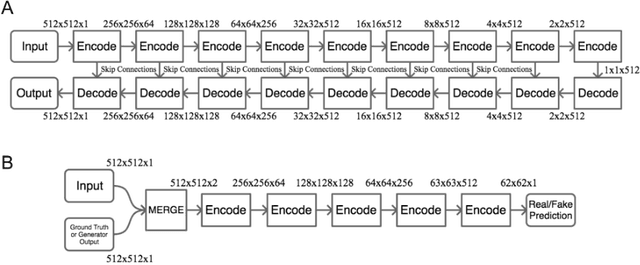

In the field of pattern recognition research, the method of using deep neural networks based on improved computing hardware recently attracted attention because of their superior accuracy compared to conventional methods. Deep neural networks simulate the human visual system and achieve human equivalent accuracy in image classification, object detection, and segmentation. This chapter introduces the basic structure of deep neural networks that simulate human neural networks. Then we identify the operational processes and applications of conditional generative adversarial networks, which are being actively researched based on the bottom-up and top-down mechanisms, the most important functions of the human visual perception process. Finally, recent developments in training strategies for effective learning of complex deep neural networks are addressed.