 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrarily Applicable Same/Opposite Relational Responding with NARS
May 11, 2025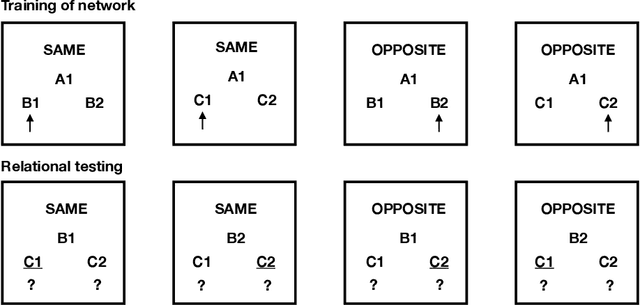
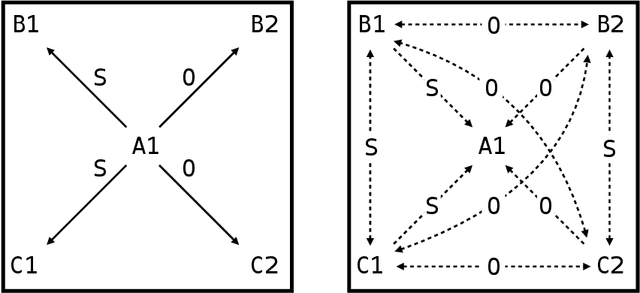
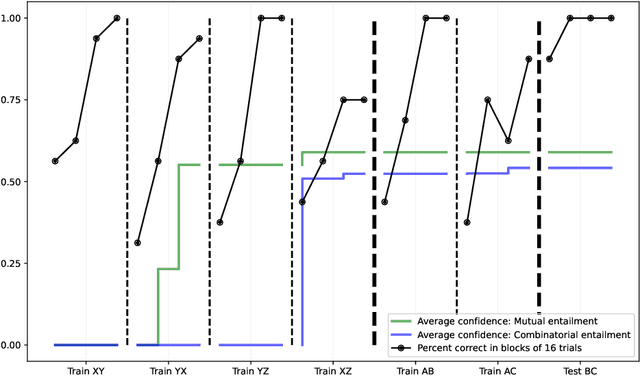
Same/opposite relational responding, a fundamental aspect of human symbolic cognition, allows the flexible generalization of stimulus relationships based on minimal experience. In this study, we demonstrate the emergence of \textit{arbitrarily applicable} same/opposite relational responding within the Non-Axiomatic Reasoning System (NARS), a computational cognitive architecture designed for adaptive reasoning under uncertainty. Specifically, we extend NARS with an implementation of \textit{acquired relations}, enabling the system to explicitly derive both symmetric (mutual entailment) and novel relational combinations (combinatorial entailment) from minimal explicit training in a contextually controlled matching-to-sample (MTS) procedure. Experimental results show that NARS rapidly internalizes explicitly trained relational rules and robustly demonstrates derived relational generalizations based on arbitrary contextual cues. Importantly, derived relational responding in critical test phases inherently combines both mutual and combinatorial entailments, such as deriving same-relations from multiple explicitly trained opposite-relations. Internal confidence metrics illustrate strong internalization of these relational principles, closely paralleling phenomena observed in human relational learning experiments. Our findings underscore the potential for integrating nuanced relational learning mechanisms inspired by learning psychology into artificial general intelligence frameworks, explicitly highlighting the arbitrary and context-sensitive relational capabilities modeled within NARS.
Functional Equivalence with NARS
May 06, 2024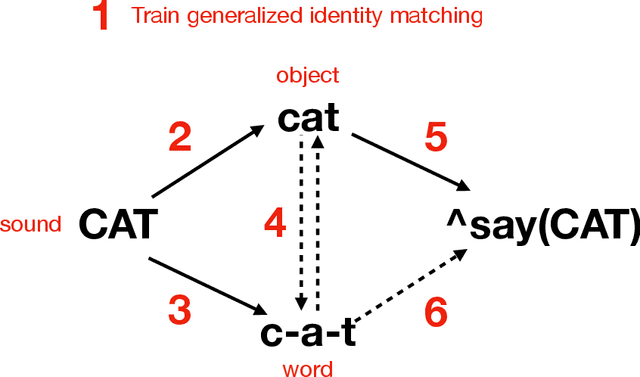
This study explores the concept of functional equivalence within the framework of the Non-Axiomatic Reasoning System (NARS), specifically through OpenNARS for Applications (ONA). Functional equivalence allows organisms to categorize and respond to varied stimuli based on their utility rather than perceptual similarity, thus enhancing cognitive efficiency and adaptability. In this study, ONA was modified to allow the derivation of functional equivalence. This paper provides practical examples of the capability of ONA to apply learned knowledge across different functional situations, demonstrating its utility in complex problem-solving and decision-making. An extended example is included, where training of ONA aimed to learn basic human-like language abilities, using a systematic procedure in relating spoken words, objects and written words. The research carried out as part of this study extends the understanding of functional equivalence in AGI systems, and argues for its necessity for level of flexibility in learning and adapting necessary for human-level AGI.
Ethosight: A Reasoning-Guided Iterative Learning System for Nuanced Perception based on Joint-Embedding & Contextual Label Affinity
Jul 21, 2023



Traditional computer vision models often require extensive manual effort for data acquisition, annotation and validation, particularly when detecting subtle behavioral nuances or events. The difficulty in distinguishing routine behaviors from potential risks in real-world applications, such as differentiating routine shopping from potential shoplifting, further complicates the process. Moreover, these models may demonstrate high false positive rates and imprecise event detection when exposed to real-world scenarios that differ significantly from the conditions of the training data. To overcome these hurdles, we present Ethosight, a novel zero-shot computer vision system. Ethosight initiates with a clean slate based on user requirements and semantic knowledge of interest. Using localized label affinity calculations and a reasoning-guided iterative learning loop, Ethosight infers scene details and iteratively refines the label set. Reasoning mechanisms can be derived from large language models like GPT4, symbolic reasoners like OpenNARS\cite{wang2013}\cite{wang2006}, or hybrid systems. Our evaluations demonstrate Ethosight's efficacy across 40 complex use cases, spanning domains such as health, safety, and security. Detailed results and case studies within the main body of this paper and an appendix underscore a promising trajectory towards enhancing the adaptability and resilience of computer vision models in detecting and extracting subtle and nuanced behaviors.
Neurosymbolic hybrid approach to driver collision warning
Mar 28, 2022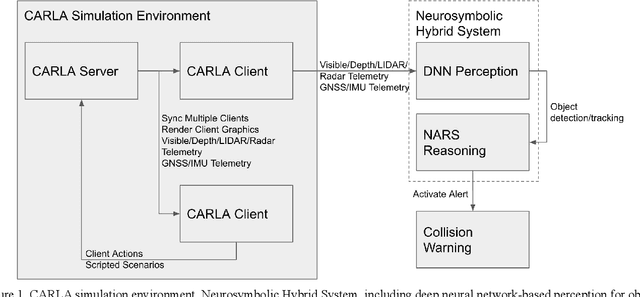

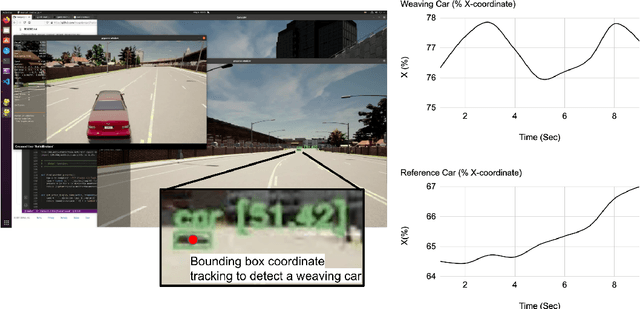

There are two main algorithmic approaches to autonomous driving systems: (1) An end-to-end system in which a single deep neural network learns to map sensory input directly into appropriate warning and driving responses. (2) A mediated hybrid recognition system in which a system is created by combining independent modules that detect each semantic feature. While some researchers believe that deep learning can solve any problem, others believe that a more engineered and symbolic approach is needed to cope with complex environments with less data. Deep learning alone has achieved state-of-the-art results in many areas, from complex gameplay to predicting protein structures. In particular, in image classification and recognition, deep learning models have achieved accuracies as high as humans. But sometimes it can be very difficult to debug if the deep learning model doesn't work. Deep learning models can be vulnerable and are very sensitive to changes in data distribution. Generalization can be problematic. It's usually hard to prove why it works or doesn't. Deep learning models can also be vulnerable to adversarial attacks. Here, we combine deep learning-based object recognition and tracking with an adaptive neurosymbolic network agent, called the Non-Axiomatic Reasoning System (NARS), that can adapt to its environment by building concepts based on perceptual sequences. We achieved an improved intersection-over-union (IOU) object recognition performance of 0.65 in the adaptive retraining model compared to IOU 0.31 in the COCO data pre-trained model. We improved the object detection limits using RADAR sensors in a simulated environment, and demonstrated the weaving car detection capability by combining deep learning-based object detection and tracking with a neurosymbolic model.
Neurosymbolic Systems of Perception & Cognition: The Role of Attention
Dec 02, 2021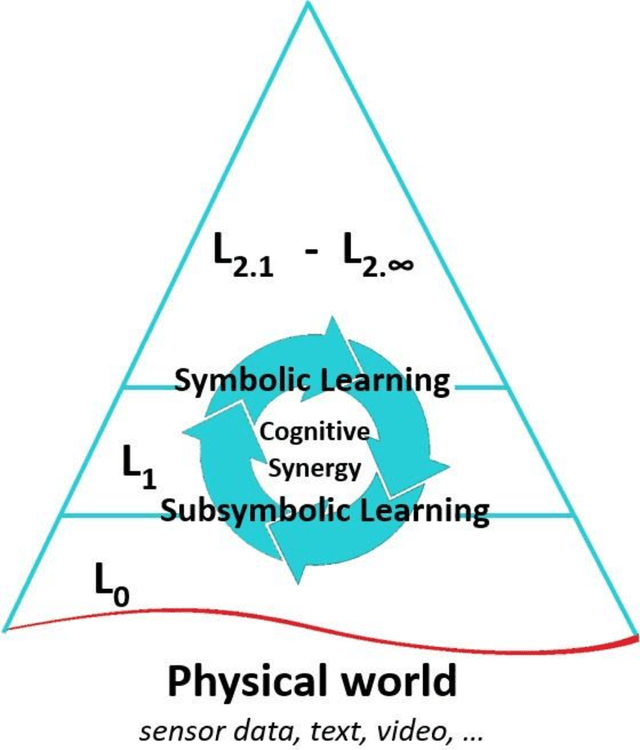

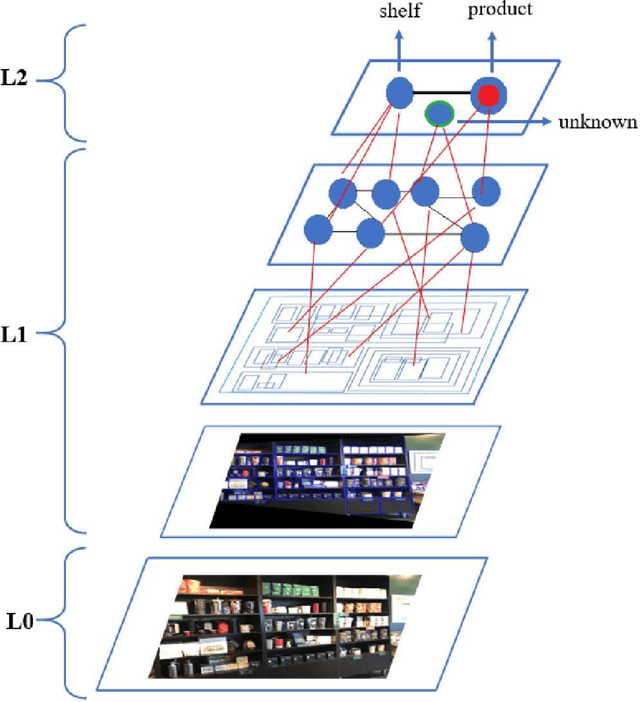
A cognitive architecture aimed at cumulative learning must provide the necessary information and control structures to allow agents to learn incrementally and autonomously from their experience. This involves managing an agent's goals as well as continuously relating sensory information to these in its perception-cognition information stack. The more varied the environment of a learning agent is, the more general and flexible must be these mechanisms to handle a wider variety of relevant patterns, tasks, and goal structures. While many researchers agree that information at different levels of abstraction likely differs in its makeup and structure and processing mechanisms, agreement on the particulars of such differences is not generally shared in the research community. A binary processing architecture (often referred to as System-1 and System-2) has been proposed as a model of cognitive processing for low- and high-level information, respectively. We posit that cognition is not binary in this way and that knowledge at any level of abstraction involves what we refer to as neurosymbolic information, meaning that data at both high and low levels must contain both symbolic and subsymbolic information. Further, we argue that the main differentiating factor between the processing of high and low levels of data abstraction can be largely attributed to the nature of the involved attention mechanisms. We describe the key arguments behind this view and review relevant evidence from the literature.