 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Flow Signatures for Self-Checking and Refinement in LLMs
Feb 02, 2026Large language models can generate fluent answers that are unfaithful to the provided context, while many safeguards rely on external verification or a separate judge after generation. We introduce \emph{internal flow signatures} that audit decision formation from depthwise dynamics at a fixed inter-block monitoring boundary. The method stabilizes token-wise motion via bias-centered monitoring, then summarizes trajectories in compact \emph{moving} readout-aligned subspaces constructed from the top token and its close competitors within each depth window. Neighboring window frames are aligned by an orthogonal transport, yielding depth-comparable transported step lengths, turning angles, and subspace drift summaries that are invariant to within-window basis choices. A lightweight GRU validator trained on these signatures performs self-checking without modifying the base model. Beyond detection, the validator localizes a culprit depth event and enables a targeted refinement: the model rolls back to the culprit token and clamps an abnormal transported step at the identified block while preserving the orthogonal residual. The resulting pipeline provides actionable localization and low-overhead self-checking from internal decision dynamics. \emph{Code is available at} \texttt{github.com/EavnJeong/Internal-Flow-Signatures-for-Self-Checking-and-Refinement-in-LLMs}.
TorchTraceAP: A New Benchmark Dataset for Detecting Performance Anti-Patterns in Computer Vision Models
Dec 16, 2025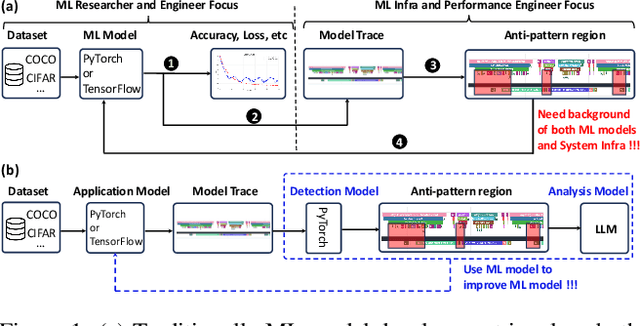
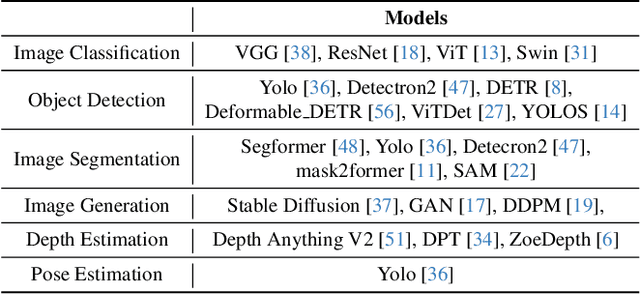
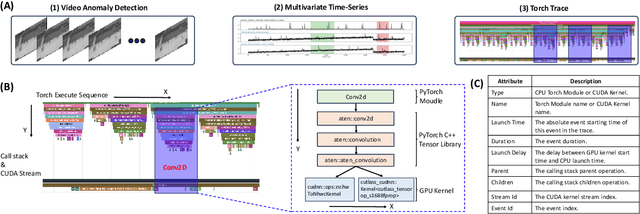

Identifying and addressing performance anti-patterns in machine learning (ML) models is critical for efficient training and inference, but it typically demands deep expertise spanning system infrastructure, ML models and kernel development. While large tech companies rely on dedicated ML infrastructure engineers to analyze torch traces and benchmarks, such resource-intensive workflows are largely inaccessible to computer vision researchers in general. Among the challenges, pinpointing problematic trace segments within lengthy execution traces remains the most time-consuming task, and is difficult to automate with current ML models, including LLMs. In this work, we present the first benchmark dataset specifically designed to evaluate and improve ML models' ability to detect anti patterns in traces. Our dataset contains over 600 PyTorch traces from diverse computer vision models classification, detection, segmentation, and generation collected across multiple hardware platforms. We also propose a novel iterative approach: a lightweight ML model first detects trace segments with anti patterns, followed by a large language model (LLM) for fine grained classification and targeted feedback. Experimental results demonstrate that our method significantly outperforms unsupervised clustering and rule based statistical techniques for detecting anti pattern regions. Our method also effectively compensates LLM's limited context length and reasoning inefficiencies.
Are Hypervectors Enough? Single-Call LLM Reasoning over Knowledge Graphs
Dec 10, 2025Recent advances in large language models (LLMs) have enabled strong reasoning over both structured and unstructured knowledge. When grounded on knowledge graphs (KGs), however, prevailing pipelines rely on heavy neural encoders to embed and score symbolic paths or on repeated LLM calls to rank candidates, leading to high latency, GPU cost, and opaque decisions that hinder faithful, scalable deployment. We propose PathHD, a lightweight and encoder-free KG reasoning framework that replaces neural path scoring with hyperdimensional computing (HDC) and uses only a single LLM call per query. PathHD encodes relation paths into block-diagonal GHRR hypervectors, ranks candidates with blockwise cosine similarity and Top-K pruning, and then performs a one-shot LLM adjudication to produce the final answer together with cited supporting paths. Technically, PathHD is built on three ingredients: (i) an order-aware, non-commutative binding operator for path composition, (ii) a calibrated similarity for robust hypervector-based retrieval, and (iii) a one-shot adjudication step that preserves interpretability while eliminating per-path LLM scoring. On WebQSP, CWQ, and the GrailQA split, PathHD (i) attains comparable or better Hits@1 than strong neural baselines while using one LLM call per query; (ii) reduces end-to-end latency by $40-60\%$ and GPU memory by $3-5\times$ thanks to encoder-free retrieval; and (iii) delivers faithful, path-grounded rationales that improve error diagnosis and controllability. These results indicate that carefully designed HDC representations provide a practical substrate for efficient KG-LLM reasoning, offering a favorable accuracy-efficiency-interpretability trade-off.
Cauchy-Schwarz Fairness Regularizer
Dec 10, 2025



Group fairness in machine learning is often enforced by adding a regularizer that reduces the dependence between model predictions and sensitive attributes. However, existing regularizers are built on heterogeneous distance measures and design choices, which makes their behavior hard to reason about and their performance inconsistent across tasks. This raises a basic question: what properties make a good fairness regularizer? We address this question by first organizing existing in-process methods into three families: (i) matching prediction statistics across sensitive groups, (ii) aligning latent representations, and (iii) directly minimizing dependence between predictions and sensitive attributes. Through this lens, we identify desirable properties of the underlying distance measure, including tight generalization bounds, robustness to scale differences, and the ability to handle arbitrary prediction distributions. Motivated by these properties, we propose a Cauchy-Schwarz (CS) fairness regularizer that penalizes the empirical CS divergence between prediction distributions conditioned on sensitive groups. Under a Gaussian comparison, we show that CS divergence yields a tighter bound than Kullback-Leibler divergence, Maximum Mean Discrepancy, and the mean disparity used in Demographic Parity, and we discuss how these advantages translate to a distribution-free, kernel-based estimator that naturally extends to multiple sensitive attributes. Extensive experiments on four tabular benchmarks and one image dataset demonstrate that the proposed CS regularizer consistently improves Demographic Parity and Equal Opportunity metrics while maintaining competitive accuracy, and achieves a more stable utility-fairness trade-off across hyperparameter settings compared to prior regularizers.
LUNE: Efficient LLM Unlearning via LoRA Fine-Tuning with Negative Examples
Dec 08, 2025Large language models (LLMs) possess vast knowledge acquired from extensive training corpora, but they often cannot remove specific pieces of information when needed, which makes it hard to handle privacy, bias mitigation, and knowledge correction. Traditional model unlearning approaches require computationally expensive fine-tuning or direct weight editing, making them impractical for real-world deployment. In this work, we introduce LoRA-based Unlearning with Negative Examples (LUNE), a lightweight framework that performs negative-only unlearning by updating only low-rank adapters while freezing the backbone, thereby localizing edits and avoiding disruptive global changes. Leveraging Low-Rank Adaptation (LoRA), LUNE targets intermediate representations to suppress (or replace) requested knowledge with an order-of-magnitude lower compute and memory than full fine-tuning or direct weight editing. Extensive experiments on multiple factual unlearning tasks show that LUNE: (I) achieves effectiveness comparable to full fine-tuning and memory-editing methods, and (II) reduces computational cost by about an order of magnitude.
Mitigating Bias in Graph Hyperdimensional Computing
Dec 08, 2025Graph hyperdimensional computing (HDC) has emerged as a promising paradigm for cognitive tasks, emulating brain-like computation with high-dimensional vectors known as hypervectors. While HDC offers robustness and efficiency on graph-structured data, its fairness implications remain largely unexplored. In this paper, we study fairness in graph HDC, where biases in data representation and decision rules can lead to unequal treatment of different groups. We show how hypervector encoding and similarity-based classification can propagate or even amplify such biases, and we propose a fairness-aware training framework, FairGHDC, to mitigate them. FairGHDC introduces a bias correction term, derived from a gap-based demographic-parity regularizer, and converts it into a scalar fairness factor that scales the update of the class hypervector for the ground-truth label. This enables debiasing directly in the hypervector space without modifying the graph encoder or requiring backpropagation. Experimental results on six benchmark datasets demonstrate that FairGHDC substantially reduces demographic-parity and equal-opportunity gaps while maintaining accuracy comparable to standard GNNs and fairness-aware GNNs. At the same time, FairGHDC preserves the computational advantages of HDC, achieving up to about one order of magnitude ($\approx 10\times$) speedup in training time on GPU compared to GNN and fairness-aware GNN baselines.
Recover-to-Forget: Gradient Reconstruction from LoRA for Efficient LLM Unlearning
Dec 08, 2025



Unlearning in large foundation models (e.g., LLMs) is essential for enabling dynamic knowledge updates, enforcing data deletion rights, and correcting model behavior. However, existing unlearning methods often require full-model fine-tuning or access to the original training data, which limits their scalability and practicality. In this work, we introduce Recover-to-Forget (R2F), a novel framework for efficient unlearning in LLMs based on reconstructing full-model gradient directions from low-rank LoRA adapter updates. Rather than performing backpropagation through the full model, we compute gradients with respect to LoRA parameters using multiple paraphrased prompts and train a gradient decoder to approximate the corresponding full-model gradients. To ensure applicability to larger or black-box models, the decoder is trained on a proxy model and transferred to target models. We provide a theoretical analysis of cross-model generalization and demonstrate that our method achieves effective unlearning while preserving general model performance. Experimental results demonstrate that R2F offers a scalable and lightweight alternative for unlearning in pretrained LLMs without requiring full retraining or access to internal parameters.
QUILL: An Algorithm-Architecture Co-Design for Cache-Local Deformable Attention
Nov 17, 2025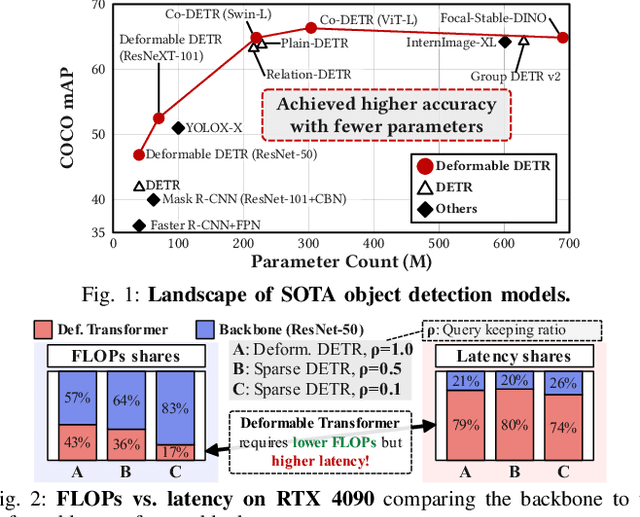
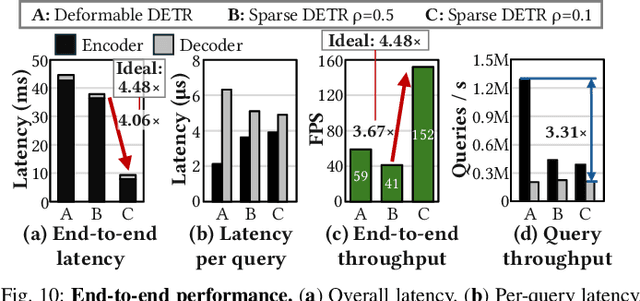
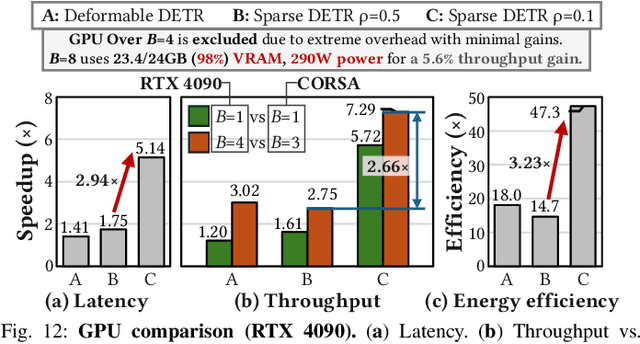
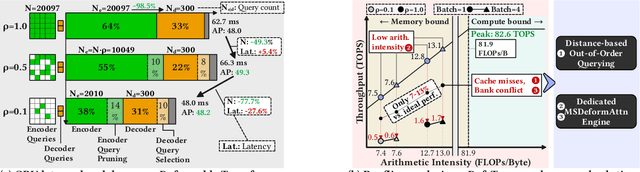
Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.
T-SAR: A Full-Stack Co-design for CPU-Only Ternary LLM Inference via In-Place SIMD ALU Reorganization
Nov 17, 2025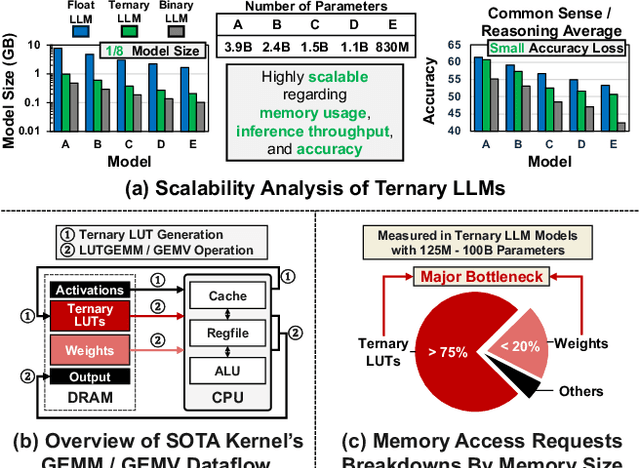
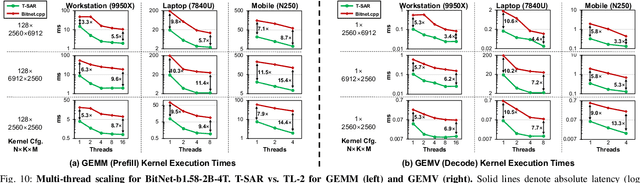
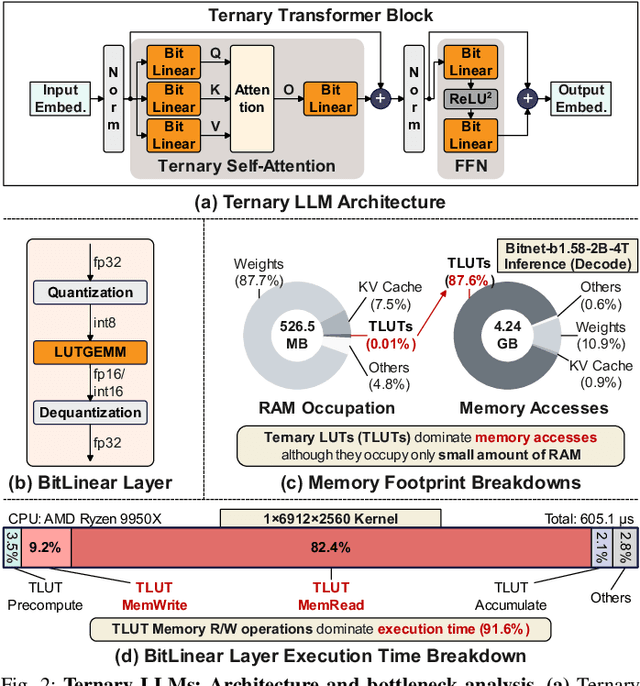
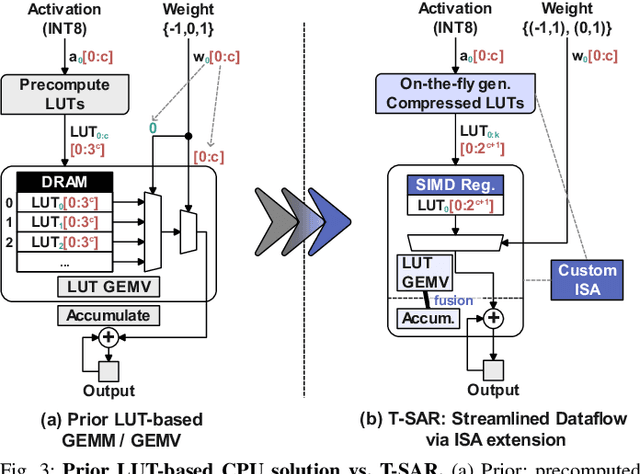
Recent advances in LLMs have outpaced the computational and memory capacities of edge platforms that primarily employ CPUs, thereby challenging efficient and scalable deployment. While ternary quantization enables significant resource savings, existing CPU solutions rely heavily on memory-based lookup tables (LUTs) which limit scalability, and FPGA or GPU accelerators remain impractical for edge use. This paper presents T-SAR, the first framework to achieve scalable ternary LLM inference on CPUs by repurposing the SIMD register file for dynamic, in-register LUT generation with minimal hardware modifications. T-SAR eliminates memory bottlenecks and maximizes data-level parallelism, delivering 5.6-24.5x and 1.1-86.2x improvements in GEMM latency and GEMV throughput, respectively, with only 3.2% power and 1.4% area overheads in SIMD units. T-SAR achieves up to 2.5-4.9x the energy efficiency of an NVIDIA Jetson AGX Orin, establishing a practical approach for efficient LLM inference on edge platforms.
Draft and Refine with Visual Experts
Nov 14, 2025While recent Large Vision-Language Models (LVLMs) exhibit strong multimodal reasoning abilities, they often produce ungrounded or hallucinated responses because they rely too heavily on linguistic priors instead of visual evidence. This limitation highlights the absence of a quantitative measure of how much these models actually use visual information during reasoning. We propose Draft and Refine (DnR), an agent framework driven by a question-conditioned utilization metric. The metric quantifies the model's reliance on visual evidence by first constructing a query-conditioned relevance map to localize question-specific cues and then measuring dependence through relevance-guided probabilistic masking. Guided by this metric, the DnR agent refines its initial draft using targeted feedback from external visual experts. Each expert's output (such as boxes or masks) is rendered as visual cues on the image, and the model is re-queried to select the response that yields the largest improvement in utilization. This process strengthens visual grounding without retraining or architectural changes. Experiments across VQA and captioning benchmarks show consistent accuracy gains and reduced hallucination, demonstrating that measuring visual utilization provides a principled path toward more interpretable and evidence-driven multimodal agent systems.