 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-SAR: A Full-Stack Co-design for CPU-Only Ternary LLM Inference via In-Place SIMD ALU Reorganization
Nov 17, 2025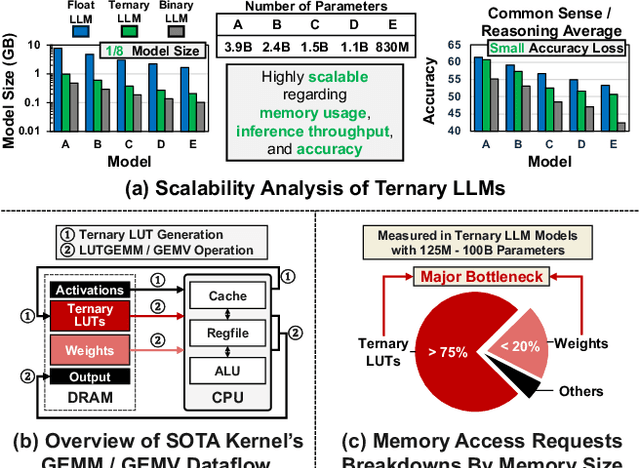
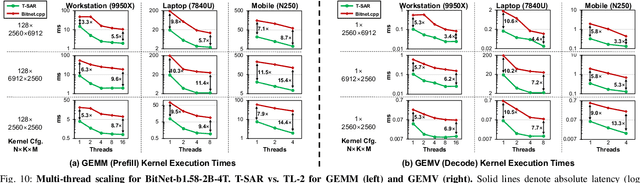
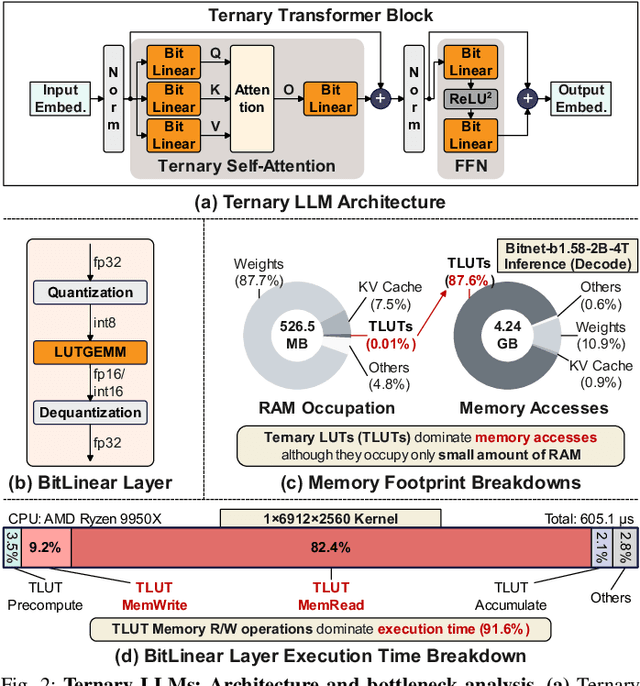
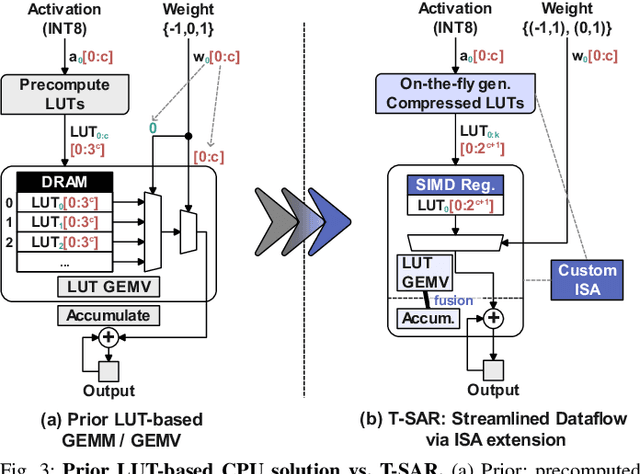
Recent advances in LLMs have outpaced the computational and memory capacities of edge platforms that primarily employ CPUs, thereby challenging efficient and scalable deployment. While ternary quantization enables significant resource savings, existing CPU solutions rely heavily on memory-based lookup tables (LUTs) which limit scalability, and FPGA or GPU accelerators remain impractical for edge use. This paper presents T-SAR, the first framework to achieve scalable ternary LLM inference on CPUs by repurposing the SIMD register file for dynamic, in-register LUT generation with minimal hardware modifications. T-SAR eliminates memory bottlenecks and maximizes data-level parallelism, delivering 5.6-24.5x and 1.1-86.2x improvements in GEMM latency and GEMV throughput, respectively, with only 3.2% power and 1.4% area overheads in SIMD units. T-SAR achieves up to 2.5-4.9x the energy efficiency of an NVIDIA Jetson AGX Orin, establishing a practical approach for efficient LLM inference on edge platforms.
QUILL: An Algorithm-Architecture Co-Design for Cache-Local Deformable Attention
Nov 17, 2025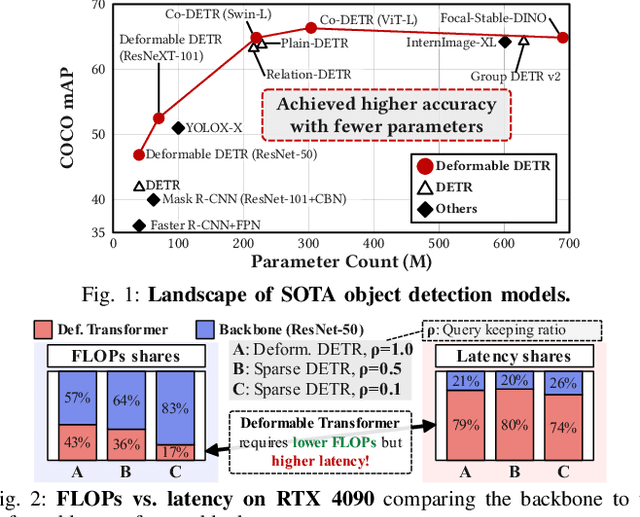
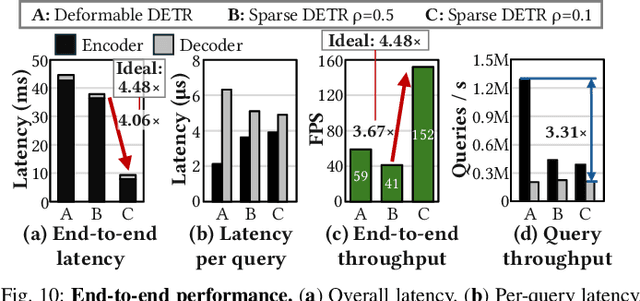
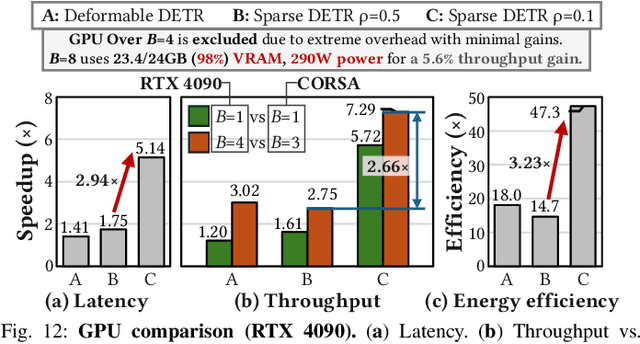
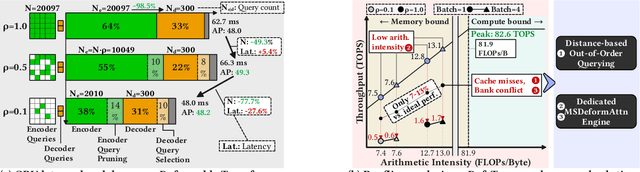
Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.
ASTER: Attention-based Spiking Transformer Engine for Event-driven Reasoning
Nov 10, 2025The integration of spiking neural networks (SNNs) with transformer-based architectures has opened new opportunities for bio-inspired low-power, event-driven visual reasoning on edge devices. However, the high temporal resolution and binary nature of spike-driven computation introduce architectural mismatches with conventional digital hardware (CPU/GPU). Prior neuromorphic and Processing-in-Memory (PIM) accelerators struggle with high sparsity and complex operations prevalent in such models. To address these challenges, we propose a memory-centric hardware accelerator tailored for spiking transformers, optimized for deployment in real-time event-driven frameworks such as classification with both static and event-based input frames. Our design leverages a hybrid analog-digital PIM architecture with input sparsity optimizations, and a custom-designed dataflow to minimize memory access overhead and maximize data reuse under spatiotemporal sparsity, for compute and memory-efficient end-to-end execution of spiking transformers. We subsequently propose inference-time software optimizations for layer skipping, and timestep reduction, leveraging Bayesian Optimization with surrogate modeling to perform robust, efficient co-exploration of the joint algorithmic-microarchitectural design spaces under tight computational budgets. Evaluated on both image(ImageNet) and event-based (CIFAR-10 DVS, DVSGesture) classification, the accelerator achieves up to ~467x and ~1.86x energy reduction compared to edge GPU (Jetson Orin Nano) and previous PIM accelerators for spiking transformers, while maintaining competitive task accuracy on ImageNet dataset. This work enables a new class of intelligent ubiquitous edge AI, built using spiking transformer acceleration for low-power, real-time visual processing at the extreme edge.
LVLM_CSP: Accelerating Large Vision Language Models via Clustering, Scattering, and Pruning for Reasoning Segmentation
Apr 15, 2025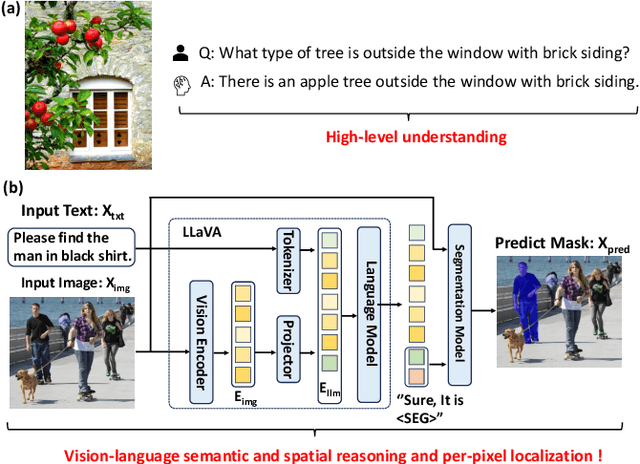
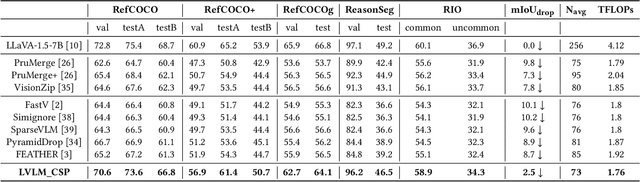
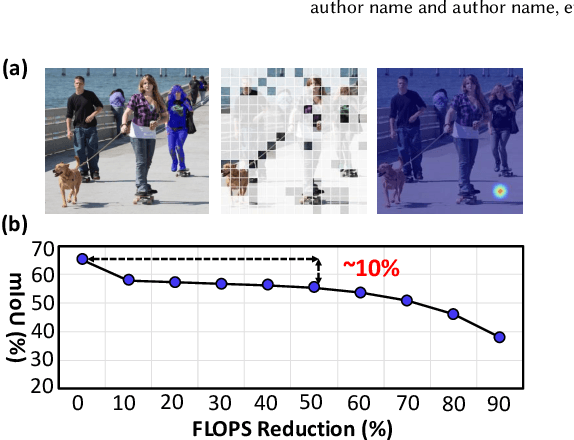
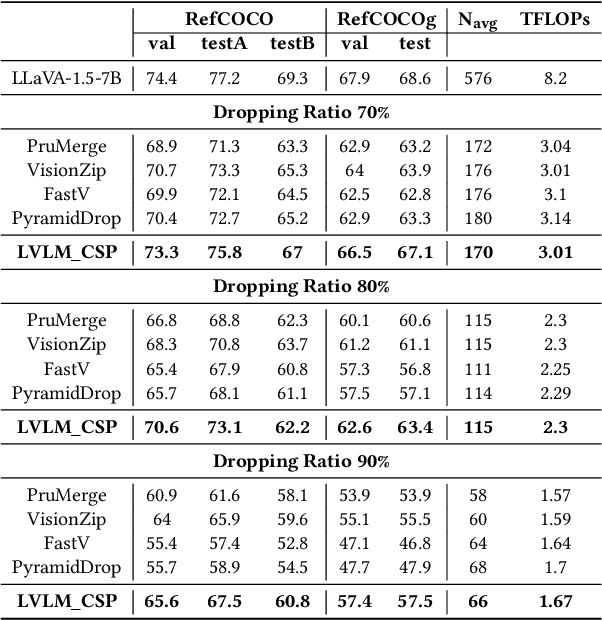
Large Vision Language Models (LVLMs) have been widely adopted to guide vision foundation models in performing reasoning segmentation tasks, achieving impressive performance. However, the substantial computational overhead associated with LVLMs presents a new challenge. The primary source of this computational cost arises from processing hundreds of image tokens. Therefore, an effective strategy to mitigate such overhead is to reduce the number of image tokens, a process known as image token pruning. Previous studies on image token pruning for LVLMs have primarily focused on high level visual understanding tasks, such as visual question answering and image captioning. In contrast, guiding vision foundation models to generate accurate visual masks based on textual queries demands precise semantic and spatial reasoning capabilities. Consequently, pruning methods must carefully control individual image tokens throughout the LVLM reasoning process. Our empirical analysis reveals that existing methods struggle to adequately balance reductions in computational overhead with the necessity to maintain high segmentation accuracy. In this work, we propose LVLM_CSP, a novel training free visual token pruning method specifically designed for LVLM based reasoning segmentation tasks. LVLM_CSP consists of three stages: clustering, scattering, and pruning. Initially, the LVLM performs coarse-grained visual reasoning using a subset of selected image tokens. Next, fine grained reasoning is conducted, and finally, most visual tokens are pruned in the last stage. Extensive experiments demonstrate that LVLM_CSP achieves a 65% reduction in image token inference FLOPs with virtually no accuracy degradation, and a 70% reduction with only a minor 1% drop in accuracy on the 7B LVLM.