 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Atoms Model with Application to Clustering Big Population-Scale Single-Cell Data
Apr 13, 2026We consider the problem of clustering nested or hierarchical data, where observations are grouped and there are both group-level and observation-level variables. In our motivating OneK1K dataset, observations consist of single-cell RNA-sequencing (scRNA-seq) data from 982 individuals (groups), totaling 1.27 million cells (observations), along with individual-specific genotype data. This type of data would enable the identification of cell types and the investigation of how genetic variations among individuals influence differences in cell-type profiles. Our goal, therefore, is to jointly cluster cells and individuals to capture the heterogeneity across both levels using cell-specific gene expressions as well as individual-specific genotypes. However, existing grouped clustering methods do not incorporate group-level variables, thereby limiting their ability to capture the heterogeneity of genotypes in our motivating application. To address this, we propose the Nested Atoms Model (NAM), a new Bayesian nonparametric approach that enables the desired two-layered clustering, accounting for both group-level and observation-level variables. To scale NAM for high-dimensional data, we develop a fast variational Bayesian inference algorithm. Simulations show that NAM outperforms existing methods that ignore group-level variables. Applied to the OneK1K dataset, NAM identifies clusters of genetically similar individuals with homogeneous cell-type profiles. The resulting cell clusters align with known immune cell types based on differential gene expression, underscoring the ability of NAM to capture nested heterogeneity and provide biologically meaningful insights.
Vertical Consensus Inference for High-Dimensional Random Partition
Mar 29, 2026We review recently proposed Bayesian approaches for clustering high-dimensional data. After identifying the main limitations of available approaches, we introduce an alternative framework based on vertical consensus inference (VCI) to mitigate the curse of dimensionality in high-dimensional Bayesian clustering. VCI builds on the idea of consensus Monte Carlo by dividing the data into multiple shards (smaller subsets of variables), performing posterior inference on each shard, and then combining the shard-level posteriors to obtain a consensus posterior. The key distinction is that VCI splits the data vertically, producing vertical shards that retain the same number of observations but have lower dimensionality. We use an entropic regularized Wasserstein barycenter to define a consensus posterior. The shard-specific barycenter weights are constructed to favor shards that provide meaningful partitions, distinct from a trivial single cluster or all singleton clusters, favoring balanced cluster sizes and precise shard-specific posterior random partitions. We show that VCI can be interpreted as a variational approximation to the posterior under a hierarchical model with a generalized Bayes prior. For relatively low-dimensional problems, experiments suggest that VCI closely approximates inference based on clustering the entire multivariate data. For high-dimensional data and in the presence of many noninformative dimensions, VCI introduces a new framework for model-based and principled inference on random partitions. Although our focus here is on random partitions, VCI can be applied to any dimension-independent parameters and serves as a bridge to emerging areas in statistics such as consensus Monte Carlo, optimal transport, variational inference, and generalized Bayes.
MERIT: Multi-domain Efficient RAW Image Translation
Mar 21, 2026RAW images captured by different camera sensors exhibit substantial domain shifts due to varying spectral responses, noise characteristics, and tone behaviors, complicating their direct use in downstream computer vision tasks. Prior methods address this problem by training domain-specific RAW-to-RAW translators for each source-target pair, but such approaches do not scale to real-world scenarios involving multiple types of commercial cameras. In this work, we introduce MERIT, the first unified framework for multi-domain RAW image translation, which leverages a single model to perform translations across arbitrary camera domains. To address domain-specific noise discrepancies, we propose a sensor-aware noise modeling loss that explicitly aligns the signal-dependent noise statistics of the generated images with those of the target domain. We further enhance the generator with a conditional multi-scale large kernel attention module for improved context and sensor-aware feature modeling. To facilitate standardized evaluation, we introduce MDRAW, the first dataset tailored for multi-domain RAW image translation, comprising both paired and unpaired RAW captures from five diverse camera sensors across a wide range of scenes. Extensive experiments demonstrate that MERIT outperforms prior models in both quality (5.56 dB improvement) and scalability (80% reduction in training iterations).
A Scoping Review of AI-Driven Digital Interventions in Mental Health Care: Mapping Applications Across Screening, Support, Monitoring, Prevention, and Clinical Education
Mar 17, 2026Artificial intelligence (AI)-enabled digital interventions, including Generative AI (GenAI) and Human-Centered AI (HCAI), are increasingly used to expand access to digital psychiatry and mental health care. This PRISMA-ScR scoping review maps the landscape of AI-driven mental health (mHealth) technologies across five critical phases: pre-treatment (screening/triage), treatment (therapeutic support), post-treatment (remote patient monitoring), clinical education, and population-level prevention. We synthesized 36 empirical studies implemented through early 2024, focusing on Large Language Models (LLMs), machine learning (ML) models, and autonomous conversational agents. Key use cases involve referral triage, empathic communication enhancement, and AI-assisted psychotherapy delivered via chatbots and voice agents. While benefits include reduced wait times and increased patient engagement, we address recurring challenges like algorithmic bias, data privacy, and human-AI collaboration barriers. By introducing a novel four-pillar framework, this review provides a comprehensive roadmap for AI-augmented mental health care, offering actionable insights for researchers, clinicians, and policymakers to develop safe, effective, and equitable digital health interventions.
* Please cite the published version. Thank you. Y. Ni and F. Jia. 2025. A Scoping Review of AI-Driven Digital Interventions in Mental Health Care: Mapping Applications Across Screening, Support, Monitoring, Prevention, and Clinical Education. Healthcare 13, 10 (2025), 1205. DOI:https://doi.org/10.3390/healthcare13101205
Bayesian Multiple Multivariate Density-Density Regression
Jan 06, 2026We propose the first approach for multiple multivariate density-density regression (MDDR), making it possible to consider the regression of a multivariate density-valued response on multiple multivariate density-valued predictors. The core idea is to define a fitted distribution using a sliced Wasserstein barycenter (SWB) of push-forwards of the predictors and to quantify deviations from the observed response using the sliced Wasserstein (SW) distance. Regression functions, which map predictors' supports to the response support, and barycenter weights are inferred within a generalized Bayes framework, enabling principled uncertainty quantification without requiring a fully specified likelihood. The inference process can be seen as an instance of an inverse SWB problem. We establish theoretical guarantees, including the stability of the SWB under perturbations of marginals and barycenter weights, sample complexity of the generalized likelihood, and posterior consistency. For practical inference, we introduce a differentiable approximation of the SWB and a smooth reparameterization to handle the simplex constraint on barycenter weights, allowing efficient gradient-based MCMC sampling. We demonstrate MDDR in an application to inference for population-scale single-cell data. Posterior analysis under the MDDR model in this example includes inference on communication between multiple source/sender cell types and a target/receiver cell type. The proposed approach provides accurate fits, reliable predictions, and interpretable posterior estimates of barycenter weights, which can be used to construct sparse cell-cell communication networks.
Cauchy-Schwarz Fairness Regularizer
Dec 10, 2025



Group fairness in machine learning is often enforced by adding a regularizer that reduces the dependence between model predictions and sensitive attributes. However, existing regularizers are built on heterogeneous distance measures and design choices, which makes their behavior hard to reason about and their performance inconsistent across tasks. This raises a basic question: what properties make a good fairness regularizer? We address this question by first organizing existing in-process methods into three families: (i) matching prediction statistics across sensitive groups, (ii) aligning latent representations, and (iii) directly minimizing dependence between predictions and sensitive attributes. Through this lens, we identify desirable properties of the underlying distance measure, including tight generalization bounds, robustness to scale differences, and the ability to handle arbitrary prediction distributions. Motivated by these properties, we propose a Cauchy-Schwarz (CS) fairness regularizer that penalizes the empirical CS divergence between prediction distributions conditioned on sensitive groups. Under a Gaussian comparison, we show that CS divergence yields a tighter bound than Kullback-Leibler divergence, Maximum Mean Discrepancy, and the mean disparity used in Demographic Parity, and we discuss how these advantages translate to a distribution-free, kernel-based estimator that naturally extends to multiple sensitive attributes. Extensive experiments on four tabular benchmarks and one image dataset demonstrate that the proposed CS regularizer consistently improves Demographic Parity and Equal Opportunity metrics while maintaining competitive accuracy, and achieves a more stable utility-fairness trade-off across hyperparameter settings compared to prior regularizers.
Mitigating Bias in Graph Hyperdimensional Computing
Dec 08, 2025Graph hyperdimensional computing (HDC) has emerged as a promising paradigm for cognitive tasks, emulating brain-like computation with high-dimensional vectors known as hypervectors. While HDC offers robustness and efficiency on graph-structured data, its fairness implications remain largely unexplored. In this paper, we study fairness in graph HDC, where biases in data representation and decision rules can lead to unequal treatment of different groups. We show how hypervector encoding and similarity-based classification can propagate or even amplify such biases, and we propose a fairness-aware training framework, FairGHDC, to mitigate them. FairGHDC introduces a bias correction term, derived from a gap-based demographic-parity regularizer, and converts it into a scalar fairness factor that scales the update of the class hypervector for the ground-truth label. This enables debiasing directly in the hypervector space without modifying the graph encoder or requiring backpropagation. Experimental results on six benchmark datasets demonstrate that FairGHDC substantially reduces demographic-parity and equal-opportunity gaps while maintaining accuracy comparable to standard GNNs and fairness-aware GNNs. At the same time, FairGHDC preserves the computational advantages of HDC, achieving up to about one order of magnitude ($\approx 10\times$) speedup in training time on GPU compared to GNN and fairness-aware GNN baselines.
LUNE: Efficient LLM Unlearning via LoRA Fine-Tuning with Negative Examples
Dec 08, 2025Large language models (LLMs) possess vast knowledge acquired from extensive training corpora, but they often cannot remove specific pieces of information when needed, which makes it hard to handle privacy, bias mitigation, and knowledge correction. Traditional model unlearning approaches require computationally expensive fine-tuning or direct weight editing, making them impractical for real-world deployment. In this work, we introduce LoRA-based Unlearning with Negative Examples (LUNE), a lightweight framework that performs negative-only unlearning by updating only low-rank adapters while freezing the backbone, thereby localizing edits and avoiding disruptive global changes. Leveraging Low-Rank Adaptation (LoRA), LUNE targets intermediate representations to suppress (or replace) requested knowledge with an order-of-magnitude lower compute and memory than full fine-tuning or direct weight editing. Extensive experiments on multiple factual unlearning tasks show that LUNE: (I) achieves effectiveness comparable to full fine-tuning and memory-editing methods, and (II) reduces computational cost by about an order of magnitude.
Recover-to-Forget: Gradient Reconstruction from LoRA for Efficient LLM Unlearning
Dec 08, 2025



Unlearning in large foundation models (e.g., LLMs) is essential for enabling dynamic knowledge updates, enforcing data deletion rights, and correcting model behavior. However, existing unlearning methods often require full-model fine-tuning or access to the original training data, which limits their scalability and practicality. In this work, we introduce Recover-to-Forget (R2F), a novel framework for efficient unlearning in LLMs based on reconstructing full-model gradient directions from low-rank LoRA adapter updates. Rather than performing backpropagation through the full model, we compute gradients with respect to LoRA parameters using multiple paraphrased prompts and train a gradient decoder to approximate the corresponding full-model gradients. To ensure applicability to larger or black-box models, the decoder is trained on a proxy model and transferred to target models. We provide a theoretical analysis of cross-model generalization and demonstrate that our method achieves effective unlearning while preserving general model performance. Experimental results demonstrate that R2F offers a scalable and lightweight alternative for unlearning in pretrained LLMs without requiring full retraining or access to internal parameters.
QUILL: An Algorithm-Architecture Co-Design for Cache-Local Deformable Attention
Nov 17, 2025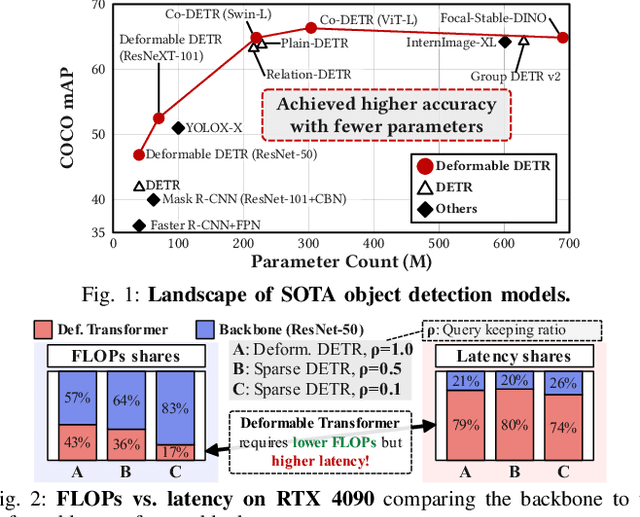
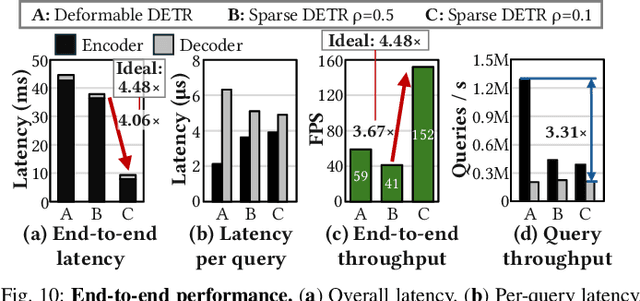
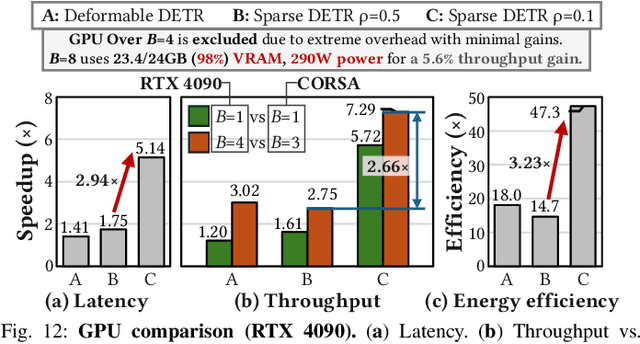
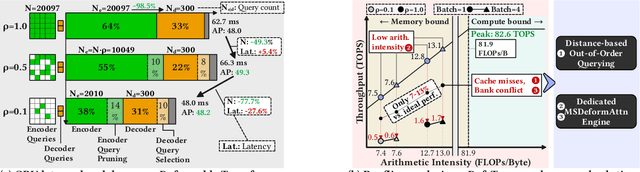
Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.