 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Vision-Language-Action Finetuning with Feasible Action Neighborhood Prior
Apr 02, 2026In real-world robotic manipulation, states typically admit a neighborhood of near-equivalent actions. That is, for each state, there exist a feasible action neighborhood (FAN) rather than a single correct action, within which motions yield indistinguishable progress. However, prevalent VLA training methodologies are directly inherited from linguistic settings and do not exploit the FAN property, thus leading to poor generalization and low sample efficiency. To address this limitation, we introduce a FAN-guided regularizer that shapes the model's output distribution to align with the geometry of FAN. Concretely, we introduce a Gaussian prior that promotes locally smooth and unimodal predictions around the preferred direction and magnitude. In extensive experiments across both reinforced finetuning (RFT) and supervised finetuning (SFT), our method achieves significant improvement in sample efficiency, and success rate in both in-distribution and out-of-distribution (OOD) scenarios. By aligning with the intrinsic action tolerance of physical manipulation, FAN-guided regularization provides a principled and practical method for sample-efficient, and generalizable VLA adaptation.
SSMG-Nav: Enhancing Lifelong Object Navigation with Semantic Skeleton Memory Graph
Mar 02, 2026Navigating to out-of-sight targets from human instructions in unfamiliar environments is a core capability for service robots. Despite substantial progress, most approaches underutilize reusable, persistent memory, constraining performance in lifelong settings. Many are additionally limited to single-modality inputs and employ myopic greedy policies, which often induce inefficient back-and-forth maneuvers (BFMs). To address such limitations, we introduce SSMG-Nav, a framework for object navigation built on a \textit{Semantic Skeleton Memory Graph} (SSMG) that consolidates past observations into a spatially aligned, persistent memory anchored by topological keypoints (e.g., junctions, room centers). SSMG clusters nearby entities into subgraphs, unifying entity- and space-level semantics to yield a compact set of candidate destinations. To support multimodal targets (images, objects, and text), we integrate a vision-language model (VLM). For each subgraph, a multimodal prompt synthesized from memory guides the VLM to infer a target belief over destinations. A long-horizon planner then trades off this belief against traversability costs to produce a visit sequence that minimizes expected path length, thereby reducing backtracking. Extensive experiments on challenging lifelong benchmarks and standard ObjectNav benchmarks demonstrate that, compared to strong baselines, our method achieves higher success rates and greater path efficiency, validating the effectiveness of SSMG-Nav.
Switchcodec: Adaptive residual-expert sparse quantization for high-fidelity neural audio coding
Jan 28, 2026Recent neural audio compression models often rely on residual vector quantization for high-fidelity coding, but using a fixed number of per-frame codebooks is suboptimal for the wide variability of audio content-especially for signals that are either very simple or highly complex. To address this limitation, we propose SwitchCodec, a neural audio codec based on Residual Experts Vector Quantization (REVQ). REVQ combines a shared quantizer with dynamically routed expert quantizers that are activated according to the input audio, decoupling bitrate from codebook capacity and improving compression efficiency. This design ensures full training and utilization of each quantizer. In addition, a variable-bitrate mechanism adjusts the number of active expert quantizers at inference, enabling multi-bitrate operation without retraining. Experiments demonstrate that SwitchCodec surpasses existing baselines on both objective metrics and subjective listening tests.
An Online Adaptation Method for Robust Depth Estimation and Visual Odometry in the Open World
Apr 16, 2025Recently, learning-based robotic navigation systems have gained extensive research attention and made significant progress. However, the diversity of open-world scenarios poses a major challenge for the generalization of such systems to practical scenarios. Specifically, learned systems for scene measurement and state estimation tend to degrade when the application scenarios deviate from the training data, resulting to unreliable depth and pose estimation. Toward addressing this problem, this work aims to develop a visual odometry system that can fast adapt to diverse novel environments in an online manner. To this end, we construct a self-supervised online adaptation framework for monocular visual odometry aided by an online-updated depth estimation module. Firstly, we design a monocular depth estimation network with lightweight refiner modules, which enables efficient online adaptation. Then, we construct an objective for self-supervised learning of the depth estimation module based on the output of the visual odometry system and the contextual semantic information of the scene. Specifically, a sparse depth densification module and a dynamic consistency enhancement module are proposed to leverage camera poses and contextual semantics to generate pseudo-depths and valid masks for the online adaptation. Finally, we demonstrate the robustness and generalization capability of the proposed method in comparison with state-of-the-art learning-based approaches on urban, in-house datasets and a robot platform. Code is publicly available at: https://github.com/jixingwu/SOL-SLAM.
A Skeleton-Based Topological Planner for Exploration in Complex Unknown Environments
Dec 18, 2024



The capability of autonomous exploration in complex, unknown environments is important in many robotic applications. While recent research on autonomous exploration have achieved much progress, there are still limitations, e.g., existing methods relying on greedy heuristics or optimal path planning are often hindered by repetitive paths and high computational demands. To address such limitations, we propose a novel exploration framework that utilizes the global topology information of observed environment to improve exploration efficiency while reducing computational overhead. Specifically, global information is utilized based on a skeletal topological graph representation of the environment geometry. We first propose an incremental skeleton extraction method based on wavefront propagation, based on which we then design an approach to generate a lightweight topological graph that can effectively capture the environment's structural characteristics. Building upon this, we introduce a finite state machine that leverages the topological structure to efficiently plan coverage paths, which can substantially mitigate the back-and-forth maneuvers (BFMs) problem. Experimental results demonstrate the superiority of our method in comparison with state-of-the-art methods. The source code will be made publicly available at: \url{https://github.com/Haochen-Niu/STGPlanner}.
VLTP: Vision-Language Guided Token Pruning for Task-Oriented Segmentation
Sep 13, 2024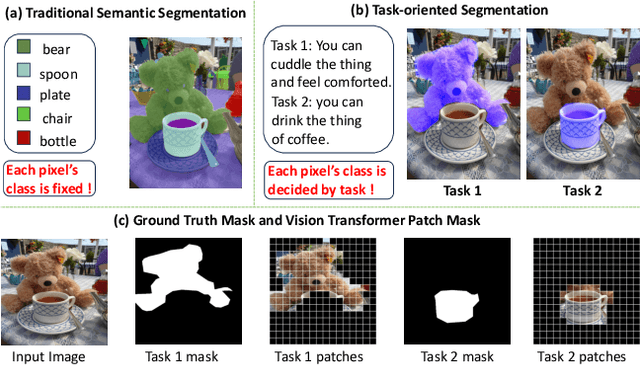
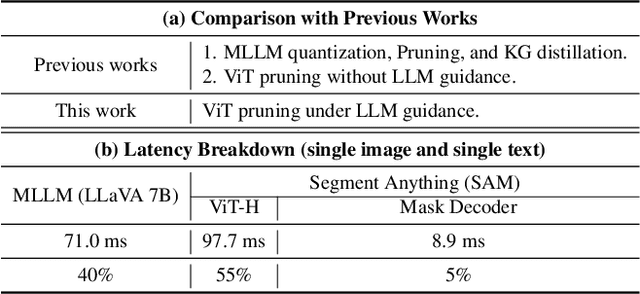
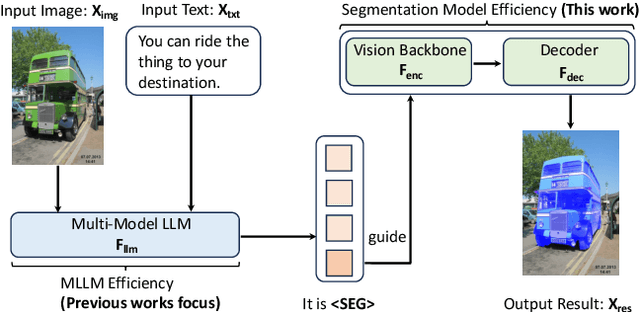
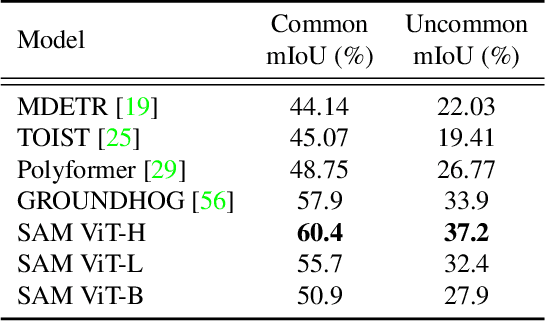
Vision Transformers (ViTs) have emerged as the backbone of many segmentation models, consistently achieving state-of-the-art (SOTA) performance. However, their success comes at a significant computational cost. Image token pruning is one of the most effective strategies to address this complexity. However, previous approaches fall short when applied to more complex task-oriented segmentation (TOS), where the class of each image patch is not predefined but dependent on the specific input task. This work introduces the Vision Language Guided Token Pruning (VLTP), a novel token pruning mechanism that can accelerate ViTbased segmentation models, particularly for TOS guided by multi-modal large language model (MLLM). We argue that ViT does not need to process every image token through all of its layers only the tokens related to reasoning tasks are necessary. We design a new pruning decoder to take both image tokens and vision-language guidance as input to predict the relevance of each image token to the task. Only image tokens with high relevance are passed to deeper layers of the ViT. Experiments show that the VLTP framework reduces the computational costs of ViT by approximately 25% without performance degradation and by around 40% with only a 1% performance drop.
Explicit Mutual Information Maximization for Self-Supervised Learning
Sep 11, 2024Recently, self-supervised learning (SSL) has been extensively studied. Theoretically, mutual information maximization (MIM) is an optimal criterion for SSL, with a strong theoretical foundation in information theory. However, it is difficult to directly apply MIM in SSL since the data distribution is not analytically available in applications. In practice, many existing methods can be viewed as approximate implementations of the MIM criterion. This work shows that, based on the invariance property of MI, explicit MI maximization can be applied to SSL under a generic distribution assumption, i.e., a relaxed condition of the data distribution. We further illustrate this by analyzing the generalized Gaussian distribution. Based on this result, we derive a loss function based on the MIM criterion using only second-order statistics. We implement the new loss for SSL and demonstrate its effectiveness via extensive experiments.
Brain-Inspired Online Adaptation for Remote Sensing with Spiking Neural Network
Sep 03, 2024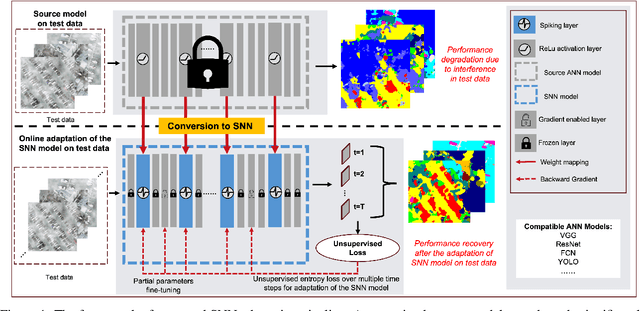
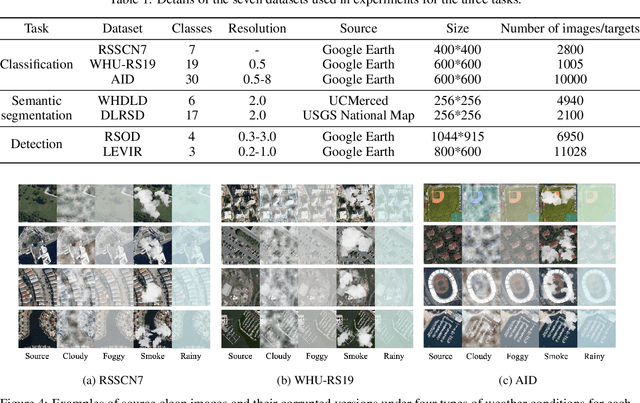
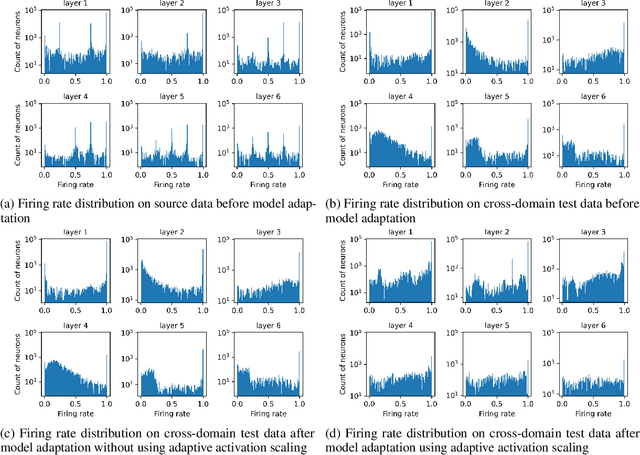
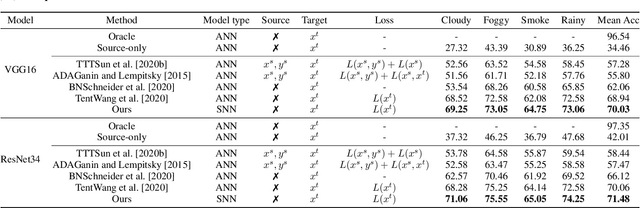
On-device computing, or edge computing, is becoming increasingly important for remote sensing, particularly in applications like deep network-based perception on on-orbit satellites and unmanned aerial vehicles (UAVs). In these scenarios, two brain-like capabilities are crucial for remote sensing models: (1) high energy efficiency, allowing the model to operate on edge devices with limited computing resources, and (2) online adaptation, enabling the model to quickly adapt to environmental variations, weather changes, and sensor drift. This work addresses these needs by proposing an online adaptation framework based on spiking neural networks (SNNs) for remote sensing. Starting with a pretrained SNN model, we design an efficient, unsupervised online adaptation algorithm, which adopts an approximation of the BPTT algorithm and only involves forward-in-time computation that significantly reduces the computational complexity of SNN adaptation learning. Besides, we propose an adaptive activation scaling scheme to boost online SNN adaptation performance, particularly in low time-steps. Furthermore, for the more challenging remote sensing detection task, we propose a confidence-based instance weighting scheme, which substantially improves adaptation performance in the detection task. To our knowledge, this work is the first to address the online adaptation of SNNs. Extensive experiments on seven benchmark datasets across classification, segmentation, and detection tasks demonstrate that our proposed method significantly outperforms existing domain adaptation and domain generalization approaches under varying weather conditions. The proposed method enables energy-efficient and fast online adaptation on edge devices, and has much potential in applications such as remote perception on on-orbit satellites and UAV.
Recoverable Anonymization for Pose Estimation: A Privacy-Enhancing Approach
Sep 01, 2024Human pose estimation (HPE) is crucial for various applications. However, deploying HPE algorithms in surveillance contexts raises significant privacy concerns due to the potential leakage of sensitive personal information (SPI) such as facial features, and ethnicity. Existing privacy-enhancing methods often compromise either privacy or performance, or they require costly additional modalities. We propose a novel privacy-enhancing system that generates privacy-enhanced portraits while maintaining high HPE performance. Our key innovations include the reversible recovery of SPI for authorized personnel and the preservation of contextual information. By jointly optimizing a privacy-enhancing module, a privacy recovery module, and a pose estimator, our system ensures robust privacy protection, efficient SPI recovery, and high-performance HPE. Experimental results demonstrate the system's robust performance in privacy enhancement, SPI recovery, and HPE.
Analyzing and Bridging the Gap between Maximizing Total Reward and Discounted Reward in Deep Reinforcement Learning
Jul 18, 2024In deep reinforcement learning applications, maximizing discounted reward is often employed instead of maximizing total reward to ensure the convergence and stability of algorithms, even though the performance metric for evaluating the policy remains the total reward. However, the optimal policies corresponding to these two objectives may not always be consistent. To address this issue, we analyzed the suboptimality of the policy obtained through maximizing discounted reward in relation to the policy that maximizes total reward and identified the influence of hyperparameters. Additionally, we proposed sufficient conditions for aligning the optimal policies of these two objectives under various settings. The primary contributions are as follows: We theoretically analyzed the factors influencing performance when using discounted reward as a proxy for total reward, thereby enhancing the theoretical understanding of this scenario. Furthermore, we developed methods to align the optimal policies of the two objectives in certain situations, which can improve the performance of reinforcement learning algorithms.