 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSMG-Nav: Enhancing Lifelong Object Navigation with Semantic Skeleton Memory Graph
Mar 02, 2026Navigating to out-of-sight targets from human instructions in unfamiliar environments is a core capability for service robots. Despite substantial progress, most approaches underutilize reusable, persistent memory, constraining performance in lifelong settings. Many are additionally limited to single-modality inputs and employ myopic greedy policies, which often induce inefficient back-and-forth maneuvers (BFMs). To address such limitations, we introduce SSMG-Nav, a framework for object navigation built on a \textit{Semantic Skeleton Memory Graph} (SSMG) that consolidates past observations into a spatially aligned, persistent memory anchored by topological keypoints (e.g., junctions, room centers). SSMG clusters nearby entities into subgraphs, unifying entity- and space-level semantics to yield a compact set of candidate destinations. To support multimodal targets (images, objects, and text), we integrate a vision-language model (VLM). For each subgraph, a multimodal prompt synthesized from memory guides the VLM to infer a target belief over destinations. A long-horizon planner then trades off this belief against traversability costs to produce a visit sequence that minimizes expected path length, thereby reducing backtracking. Extensive experiments on challenging lifelong benchmarks and standard ObjectNav benchmarks demonstrate that, compared to strong baselines, our method achieves higher success rates and greater path efficiency, validating the effectiveness of SSMG-Nav.
An Online Adaptation Method for Robust Depth Estimation and Visual Odometry in the Open World
Apr 16, 2025Recently, learning-based robotic navigation systems have gained extensive research attention and made significant progress. However, the diversity of open-world scenarios poses a major challenge for the generalization of such systems to practical scenarios. Specifically, learned systems for scene measurement and state estimation tend to degrade when the application scenarios deviate from the training data, resulting to unreliable depth and pose estimation. Toward addressing this problem, this work aims to develop a visual odometry system that can fast adapt to diverse novel environments in an online manner. To this end, we construct a self-supervised online adaptation framework for monocular visual odometry aided by an online-updated depth estimation module. Firstly, we design a monocular depth estimation network with lightweight refiner modules, which enables efficient online adaptation. Then, we construct an objective for self-supervised learning of the depth estimation module based on the output of the visual odometry system and the contextual semantic information of the scene. Specifically, a sparse depth densification module and a dynamic consistency enhancement module are proposed to leverage camera poses and contextual semantics to generate pseudo-depths and valid masks for the online adaptation. Finally, we demonstrate the robustness and generalization capability of the proposed method in comparison with state-of-the-art learning-based approaches on urban, in-house datasets and a robot platform. Code is publicly available at: https://github.com/jixingwu/SOL-SLAM.
A Skeleton-Based Topological Planner for Exploration in Complex Unknown Environments
Dec 18, 2024



The capability of autonomous exploration in complex, unknown environments is important in many robotic applications. While recent research on autonomous exploration have achieved much progress, there are still limitations, e.g., existing methods relying on greedy heuristics or optimal path planning are often hindered by repetitive paths and high computational demands. To address such limitations, we propose a novel exploration framework that utilizes the global topology information of observed environment to improve exploration efficiency while reducing computational overhead. Specifically, global information is utilized based on a skeletal topological graph representation of the environment geometry. We first propose an incremental skeleton extraction method based on wavefront propagation, based on which we then design an approach to generate a lightweight topological graph that can effectively capture the environment's structural characteristics. Building upon this, we introduce a finite state machine that leverages the topological structure to efficiently plan coverage paths, which can substantially mitigate the back-and-forth maneuvers (BFMs) problem. Experimental results demonstrate the superiority of our method in comparison with state-of-the-art methods. The source code will be made publicly available at: \url{https://github.com/Haochen-Niu/STGPlanner}.
Loop Closure Detection Based on Object-level Spatial Layout and Semantic Consistency
Apr 14, 2023Visual simultaneous localization and mapping (SLAM) systems face challenges in detecting loop closure under the circumstance of large viewpoint changes. In this paper, we present an object-based loop closure detection method based on the spatial layout and semanic consistency of the 3D scene graph. Firstly, we propose an object-level data association approach based on the semantic information from semantic labels, intersection over union (IoU), object color, and object embedding. Subsequently, multi-view bundle adjustment with the associated objects is utilized to jointly optimize the poses of objects and cameras. We represent the refined objects as a 3D spatial graph with semantics and topology. Then, we propose a graph matching approach to select correspondence objects based on the structure layout and semantic property similarity of vertices' neighbors. Finally, we jointly optimize camera trajectories and object poses in an object-level pose graph optimization, which results in a globally consistent map. Experimental results demonstrate that our proposed data association approach can construct more accurate 3D semantic maps, and our loop closure method is more robust than point-based and object-based methods in circumstances with large viewpoint changes.
Optimal Transport for Unsupervised Restoration Learning
Aug 07, 2021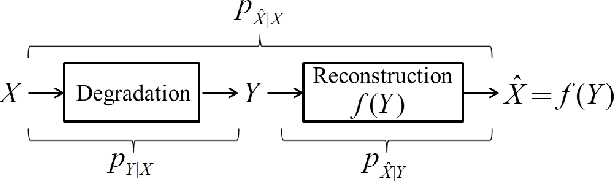
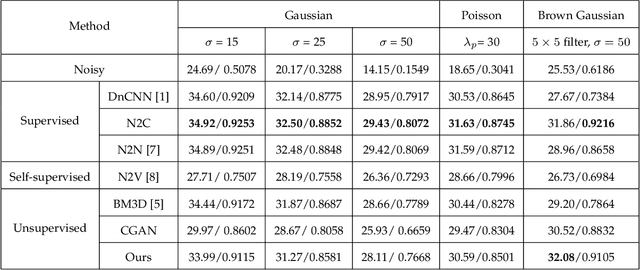
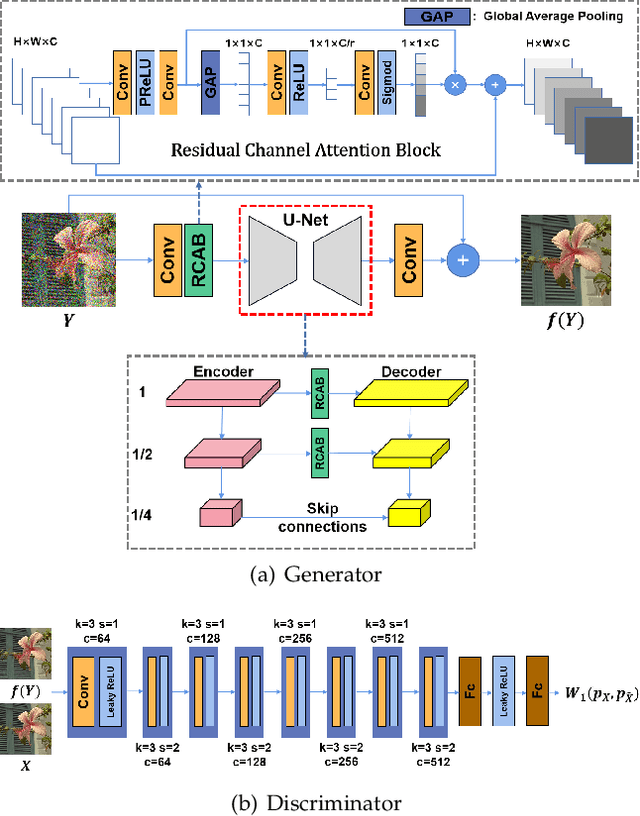

Recently, much progress has been made in unsupervised restoration learning. However, existing methods more or less rely on some assumptions on the signal and/or degradation model, which limits their practical performance. How to construct an optimal criterion for unsupervised restoration learning without any prior knowledge on the degradation model is still an open question. Toward answering this question, this work proposes a criterion for unsupervised restoration learning based on the optimal transport theory. This criterion has favorable properties, e.g., approximately maximal preservation of the information of the signal, whilst achieving perceptual reconstruction. Furthermore, though a relaxed unconstrained formulation is used in practical implementation, we show that the relaxed formulation in theory has the same solution as the original constrained formulation. Experiments on synthetic and real-world data, including realistic photographic, microscopy, depth, and raw depth images, demonstrate that the proposed method even compares favorably with supervised methods, e.g., approaching the PSNR of supervised methods while having better perceptual quality. Particularly, for spatially correlated noise and realistic microscopy images, the proposed method not only achieves better perceptual quality but also has higher PSNR than supervised methods. Besides, it shows remarkable superiority in harsh practical conditions with complex noise, e.g., raw depth images.
A life-long SLAM approach using adaptable local maps based on rasterized LIDAR images
Jul 15, 2021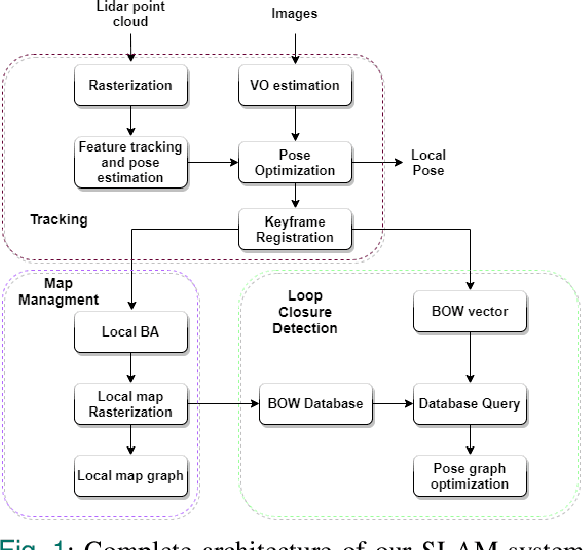
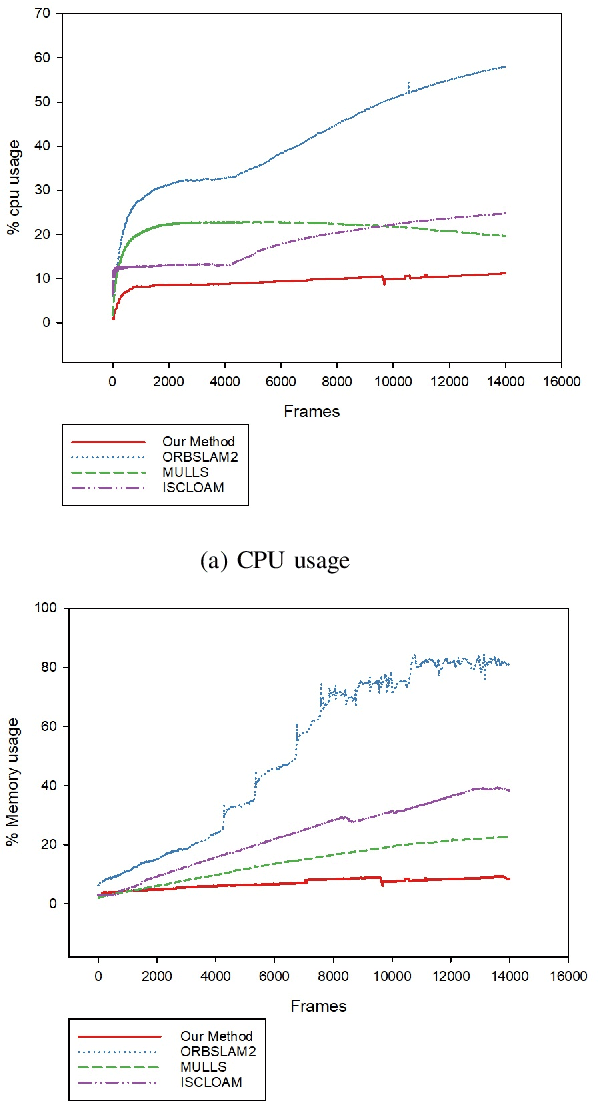
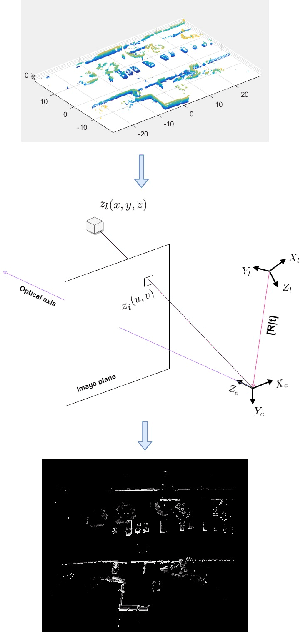
Most real-time autonomous robot applications require a robot to traverse through a dynamic space for a long time. In some cases, a robot needs to work in the same environment. Such applications give rise to the problem of a life-long SLAM system. Life-long SLAM presents two main challenges i.e. the tracking should not fail in a dynamic environment and the need for a robust and efficient mapping strategy. The system should update maps with new information; while also keeping track of older observations. But, mapping for a long time can require higher computational requirements. In this paper, we propose a solution to the problem of life-long SLAM. We represent the global map as a set of rasterized images of local maps along with a map management system responsible for updating local maps and keeping track of older values. We also present an efficient approach of using the bag of visual words method for loop closure detection and relocalization. We evaluate the performance of our system on the KITTI dataset and an indoor dataset. Our loop closure system reported recall and precision of above 90 percent. The computational cost of our system is much lower as compared to state-of-the-art methods. Our method reports lower computational requirements even for long-term operation.
On Perceptual Lossy Compression: The Cost of Perceptual Reconstruction and An Optimal Training Framework
Jun 05, 2021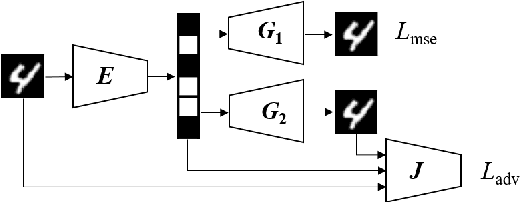
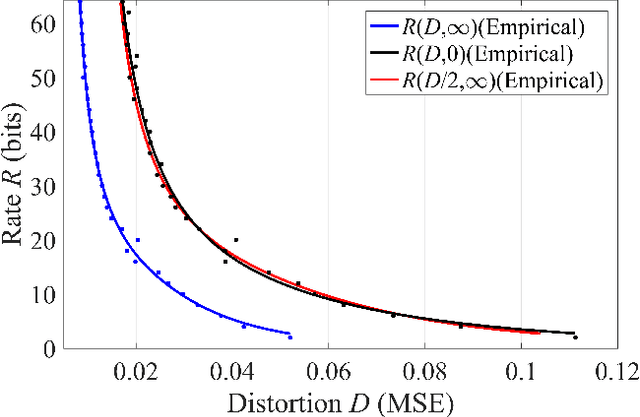
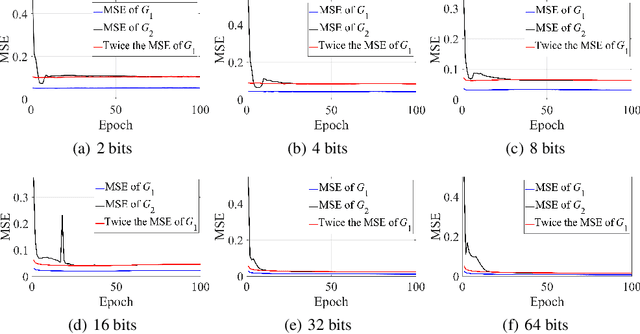

Lossy compression algorithms are typically designed to achieve the lowest possible distortion at a given bit rate. However, recent studies show that pursuing high perceptual quality would lead to increase of the lowest achievable distortion (e.g., MSE). This paper provides nontrivial results theoretically revealing that, \textit{1}) the cost of achieving perfect perception quality is exactly a doubling of the lowest achievable MSE distortion, \textit{2}) an optimal encoder for the "classic" rate-distortion problem is also optimal for the perceptual compression problem, \textit{3}) distortion loss is unnecessary for training a perceptual decoder. Further, we propose a novel training framework to achieve the lowest MSE distortion under perfect perception constraint at a given bit rate. This framework uses a GAN with discriminator conditioned on an MSE-optimized encoder, which is superior over the traditional framework using distortion plus adversarial loss. Experiments are provided to verify the theoretical finding and demonstrate the superiority of the proposed training framework.
6-DOF Feature based LIDAR SLAM using ORB Features from Rasterized Images of 3D LIDAR Point Cloud
Mar 19, 2021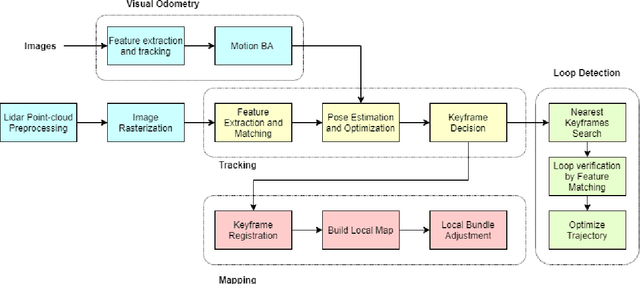
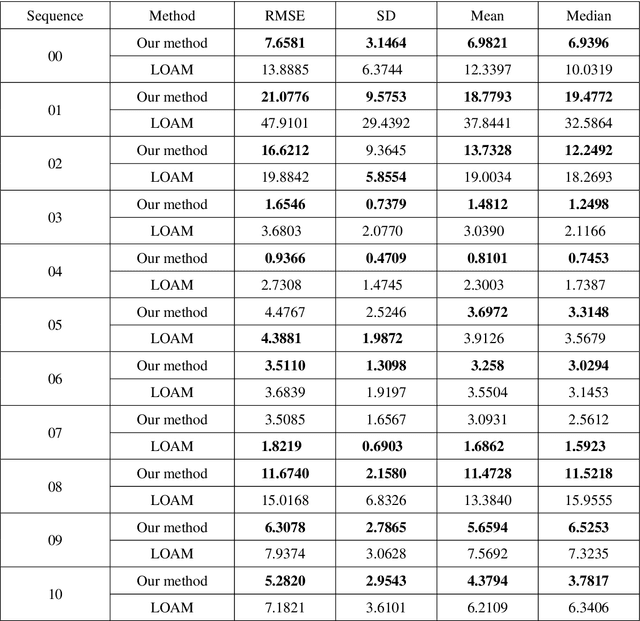
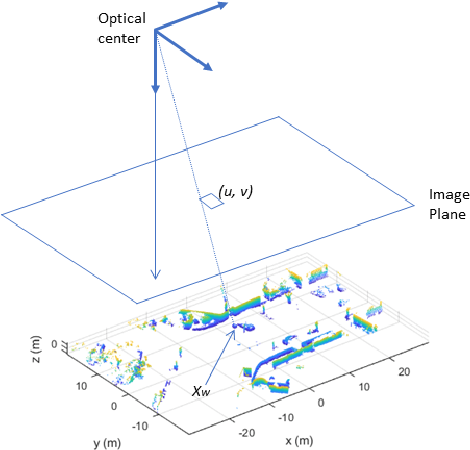
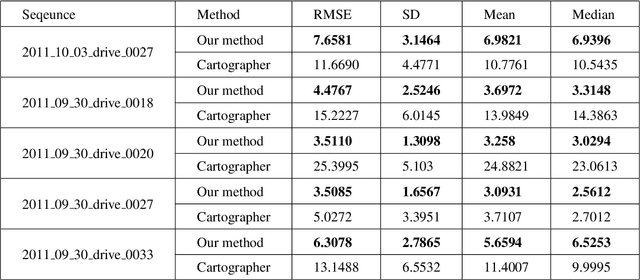
An accurate and computationally efficient SLAM algorithm is vital for modern autonomous vehicles. To make a lightweight the algorithm, most SLAM systems rely on feature detection from images for vision SLAM or point cloud for laser-based methods. Feature detection through a 3D point cloud becomes a computationally challenging task. In this paper, we propose a feature detection method by projecting a 3D point cloud to form an image and apply the vision-based feature detection technique. The proposed method gives repeatable and stable features in a variety of environments. Based on such features, we build a 6-DOF SLAM system consisting of tracking, mapping, and loop closure threads. For loop detection, we employ a 2-step approach i.e. nearest key-frames detection and loop candidate verification by matching features extracted from rasterized LIDAR images. Furthermore, we utilize a key-frame structure to achieve a lightweight SLAM system. The proposed system is evaluated with implementation on the KITTI dataset and the University of Michigan Ford Campus dataset. Through experimental results, we show that the algorithm presented in this paper can substantially reduce the computational cost of feature detection from the point cloud and the whole SLAM system while giving accurate results.
Matrix Completion via Nonconvex Regularization: Convergence of the Proximal Gradient Algorithm
Mar 02, 2019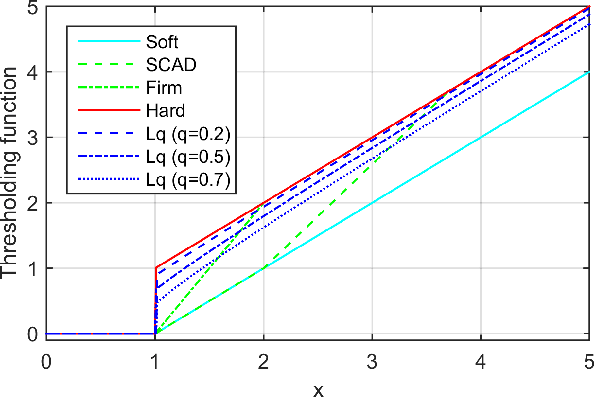
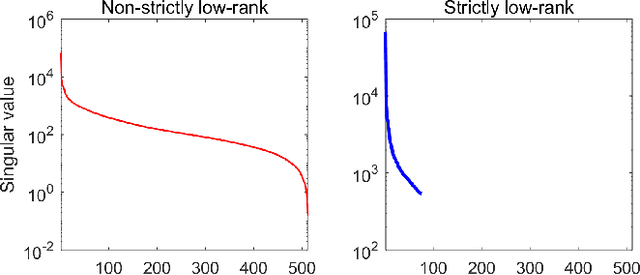
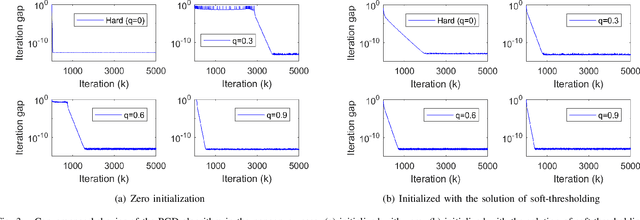
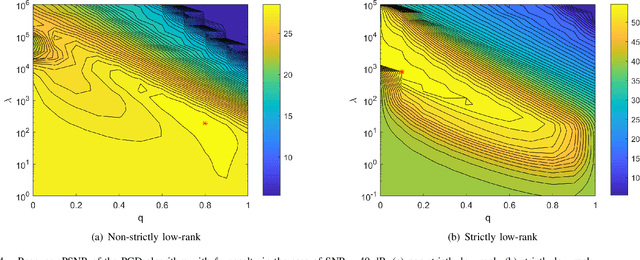
Matrix completion has attracted much interest in the past decade in machine learning and computer vision. For low-rank promotion in matrix completion, the nuclear norm penalty is convenient due to its convexity but has a bias problem. Recently, various algorithms using nonconvex penalties have been proposed, among which the proximal gradient descent (PGD) algorithm is one of the most efficient and effective. For the nonconvex PGD algorithm, whether it converges to a local minimizer and its convergence rate are still unclear. This work provides a nontrivial analysis on the PGD algorithm in the nonconvex case. Besides the convergence to a stationary point for a generalized nonconvex penalty, we provide more deep analysis on a popular and important class of nonconvex penalties which have discontinuous thresholding functions. For such penalties, we establish the finite rank convergence, convergence to restricted strictly local minimizer and eventually linear convergence rate of the PGD algorithm. Meanwhile, convergence to a local minimizer has been proved for the hard-thresholding penalty. Our result is the first shows that, nonconvex regularized matrix completion only has restricted strictly local minimizers, and the PGD algorithm can converge to such minimizers with eventually linear rate under certain conditions. Illustration of the PGD algorithm via experiments has also been provided. Code is available at https://github.com/FWen/nmc.
3DTI-Net: Learn Inner Transform Invariant 3D Geometry Features using Dynamic GCN
Dec 15, 2018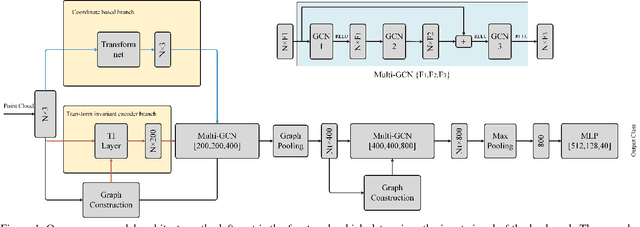
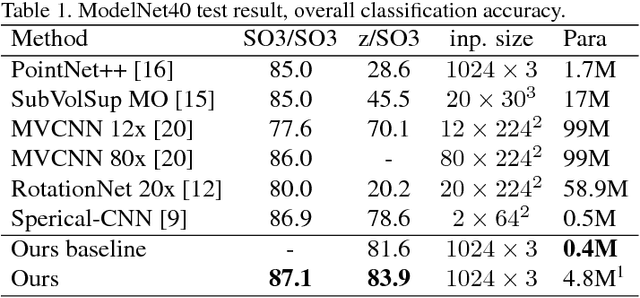
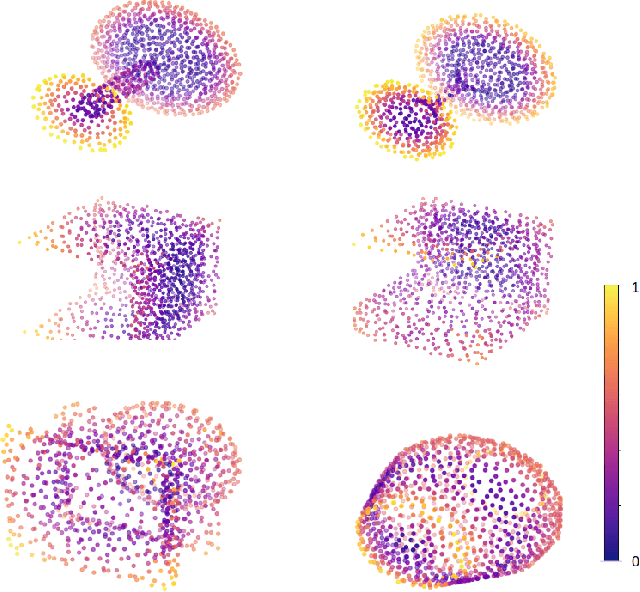
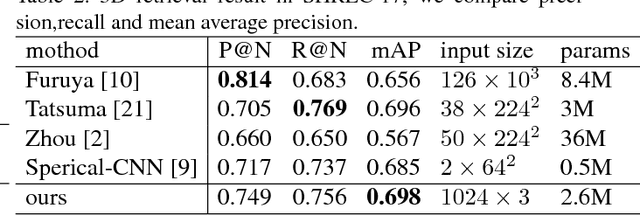
Deep learning on point clouds has made a lot of progress recently. Many point cloud dedicated deep learning frameworks, such as PointNet and PointNet++, have shown advantages in accuracy and speed comparing to those using traditional 3D convolution algorithms. However, nearly all of these methods face a challenge, since the coordinates of the point cloud are decided by the coordinate system, they cannot handle the problem of 3D transform invariance properly. In this paper, we propose a general framework for point cloud learning. We achieve transform invariance by learning inner 3D geometry feature based on local graph representation, and propose a feature extraction network based on graph convolution network. Through experiments on classification and segmentation tasks, our method achieves state-of-the-art performance in rotated 3D object classification, and achieve competitive performance with the state-of-the-art in classification and segmentation tasks with fixed coordinate value.