 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Efficient Burst HDR and Restoration: Datasets, Methods, and Results
May 17, 2025
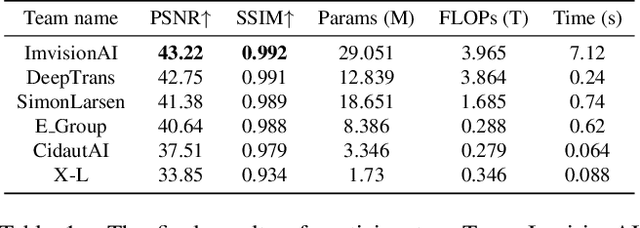

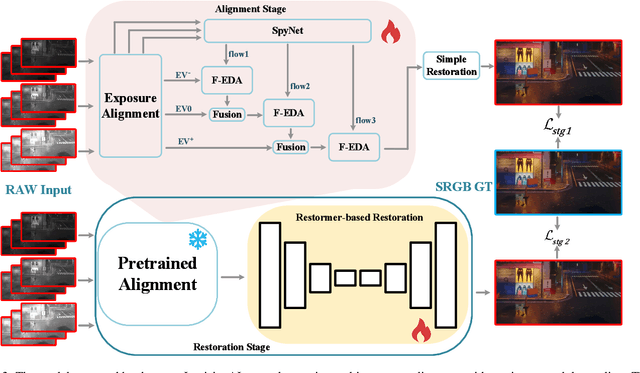
This paper reviews the NTIRE 2025 Efficient Burst HDR and Restoration Challenge, which aims to advance efficient multi-frame high dynamic range (HDR) and restoration techniques. The challenge is based on a novel RAW multi-frame fusion dataset, comprising nine noisy and misaligned RAW frames with various exposure levels per scene. Participants were tasked with developing solutions capable of effectively fusing these frames while adhering to strict efficiency constraints: fewer than 30 million model parameters and a computational budget under 4.0 trillion FLOPs. A total of 217 participants registered, with six teams finally submitting valid solutions. The top-performing approach achieved a PSNR of 43.22 dB, showcasing the potential of novel methods in this domain. This paper provides a comprehensive overview of the challenge, compares the proposed solutions, and serves as a valuable reference for researchers and practitioners in efficient burst HDR and restoration.
CLDA-YOLO: Visual Contrastive Learning Based Domain Adaptive YOLO Detector
Dec 16, 2024



Unsupervised domain adaptive (UDA) algorithms can markedly enhance the performance of object detectors under conditions of domain shifts, thereby reducing the necessity for extensive labeling and retraining. Current domain adaptive object detection algorithms primarily cater to two-stage detectors, which tend to offer minimal improvements when directly applied to single-stage detectors such as YOLO. Intending to benefit the YOLO detector from UDA, we build a comprehensive domain adaptive architecture using a teacher-student cooperative system for the YOLO detector. In this process, we propose uncertainty learning to cope with pseudo-labeling generated by the teacher model with extreme uncertainty and leverage dynamic data augmentation to asymptotically adapt the teacher-student system to the environment. To address the inability of single-stage object detectors to align at multiple stages, we utilize a unified visual contrastive learning paradigm that aligns instance at backbone and head respectively, which steadily improves the robustness of the detectors in cross-domain tasks. In summary, we present an unsupervised domain adaptive YOLO detector based on visual contrastive learning (CLDA-YOLO), which achieves highly competitive results across multiple domain adaptive datasets without any reduction in inference speed.
3DTI-Net: Learn Inner Transform Invariant 3D Geometry Features using Dynamic GCN
Dec 15, 2018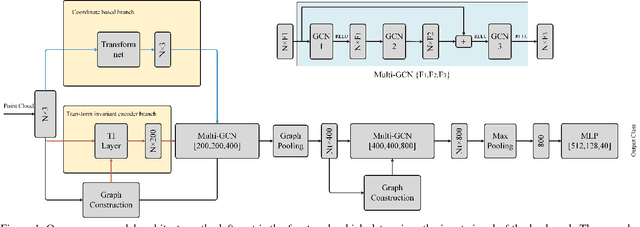
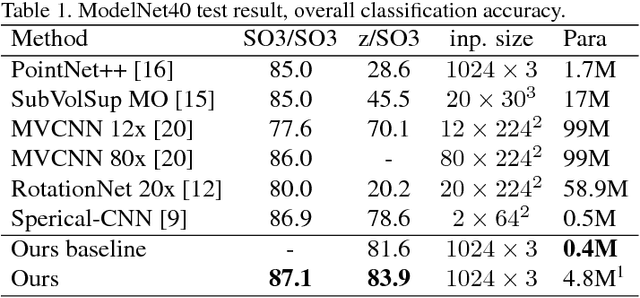
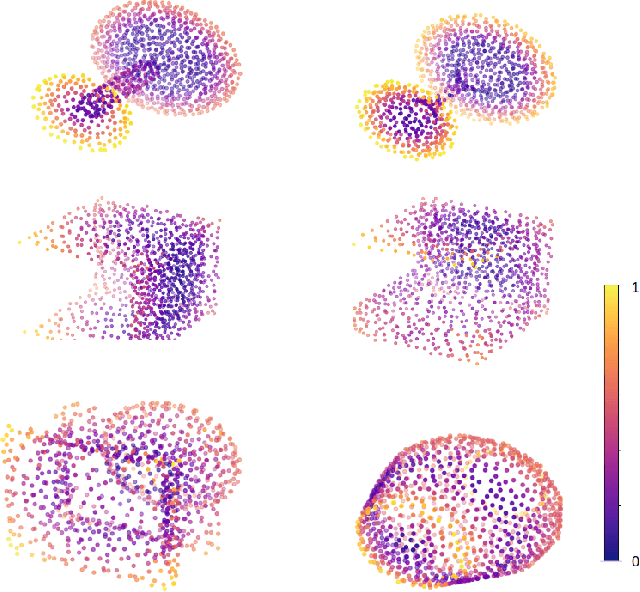
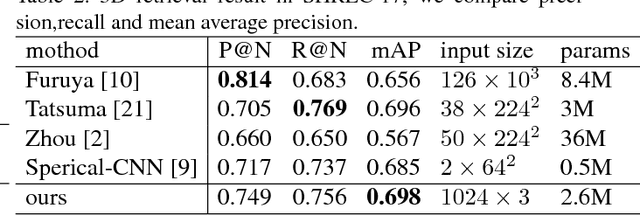
Deep learning on point clouds has made a lot of progress recently. Many point cloud dedicated deep learning frameworks, such as PointNet and PointNet++, have shown advantages in accuracy and speed comparing to those using traditional 3D convolution algorithms. However, nearly all of these methods face a challenge, since the coordinates of the point cloud are decided by the coordinate system, they cannot handle the problem of 3D transform invariance properly. In this paper, we propose a general framework for point cloud learning. We achieve transform invariance by learning inner 3D geometry feature based on local graph representation, and propose a feature extraction network based on graph convolution network. Through experiments on classification and segmentation tasks, our method achieves state-of-the-art performance in rotated 3D object classification, and achieve competitive performance with the state-of-the-art in classification and segmentation tasks with fixed coordinate value.