 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWPGRec: Wavelet Packet Guided Graph Enhanced Sequential Recommendation
Apr 23, 2026Sequential recommendation aims to model users' evolving interests from noisy and non-stationary interaction streams, where long-term preferences, short-term intents, and localized behavioral fluctuations may coexist across temporal scales. Existing frequency-domain methods mainly rely on either global spectral operations or filter-based wavelet processing. However, global spectral operations tend to entangle local transients with long-range dependencies, while filter-based wavelet pipelines may suffer from temporal misalignment and boundary artifacts during multi-scale decomposition and reconstruction. Moreover, collaborative signals from the user-item interaction graph are often injected through scale-inconsistent auxiliary modules, limiting the benefit of jointly modeling temporal dynamics and structural dependencies. To address these issues, we propose Wavelet Packet Guided Graph Enhanced Sequential Recommendation (WPGRec), a unified time-frequency and graph-enhanced framework that aligns multi-resolution temporal modeling with graph propagation at matching scales. WPGRec first applies a full-tree undecimated stationary wavelet packet transform to generate equal-length, shift-invariant subband sequences. It then performs subband-wise interaction-graph propagation to inject high-order collaborative information while preserving temporal alignment across resolutions. Finally, an energy- and spectral-flatness-aware gated fusion module adaptively aggregates informative subbands and suppresses noise-like components. Extensive experiments on four public benchmarks show that WPGRec consistently outperforms sequential and graph-based baselines, with particularly clear gains on sparse and behaviorally complex datasets, highlighting the effectiveness of band-consistent structure injection and adaptive subband fusion for sequential recommendation.
Self-Awareness before Action: Mitigating Logical Inertia via Proactive Cognitive Awareness
Apr 22, 2026Large language models perform well on many reasoning tasks, yet they often lack awareness of whether their current knowledge or reasoning state is complete. In non-interactive puzzle settings, the narrative is fixed and the underlying structure is hidden; once a model forms an early hypothesis under incomplete premises, it can propagate that error throughout the reasoning process, leading to unstable conclusions. To address this issue, we propose SABA, a reasoning framework that explicitly introduces self-awareness of missing premises before making the final decision. SABA formulates reasoning as a recursive process that alternates between structured state construction and obstacle resolution: it first applies Information Fusion to consolidate the narrative into a verifiable base state, and then uses Query-driven Structured Reasoning to identify and resolve missing or underspecified premises by turning them into queries and progressively completing the reasoning state through hypothesis construction and state refinement. Across multiple evaluation metrics, SABA achieves the best performance on all three difficulty splits of the non-interactive Detective Puzzle benchmark, and it also maintains leading results on multiple public benchmarks.
PinpointQA: A Dataset and Benchmark for Small Object-Centric Spatial Understanding in Indoor Videos
Apr 10, 2026Small object-centric spatial understanding in indoor videos remains a significant challenge for multimodal large language models (MLLMs), despite its practical value for object search and assistive applications. Although existing benchmarks have advanced video spatial intelligence, embodied reasoning, and diagnostic perception, no existing benchmark directly evaluates whether a model can localize a target object in video and express its position with sufficient precision for downstream use. In this work, we introduce PinpointQA, the first dataset and benchmark for small object-centric spatial understanding in indoor videos. Built from ScanNet++ and ScanNet200, PinpointQA comprises 1,024 scenes and 10,094 QA pairs organized into four progressively challenging tasks: Target Presence Verification (TPV), Nearest Reference Identification (NRI), Fine-Grained Spatial Description (FSD), and Structured Spatial Prediction (SSP). The dataset is built from intermediate spatial representations, with QA pairs generated automatically and further refined through quality control. Experiments on representative MLLMs reveal a consistent capability gap along the progressive chain, with SSP remaining particularly difficult. Supervised fine-tuning on PinpointQA yields substantial gains, especially on the harder tasks, demonstrating that PinpointQA serves as both a diagnostic benchmark and an effective training dataset. The dataset and project page are available at https://rainchowz.github.io/PinpointQA.
Boosting Vision-Language-Action Finetuning with Feasible Action Neighborhood Prior
Apr 02, 2026In real-world robotic manipulation, states typically admit a neighborhood of near-equivalent actions. That is, for each state, there exist a feasible action neighborhood (FAN) rather than a single correct action, within which motions yield indistinguishable progress. However, prevalent VLA training methodologies are directly inherited from linguistic settings and do not exploit the FAN property, thus leading to poor generalization and low sample efficiency. To address this limitation, we introduce a FAN-guided regularizer that shapes the model's output distribution to align with the geometry of FAN. Concretely, we introduce a Gaussian prior that promotes locally smooth and unimodal predictions around the preferred direction and magnitude. In extensive experiments across both reinforced finetuning (RFT) and supervised finetuning (SFT), our method achieves significant improvement in sample efficiency, and success rate in both in-distribution and out-of-distribution (OOD) scenarios. By aligning with the intrinsic action tolerance of physical manipulation, FAN-guided regularization provides a principled and practical method for sample-efficient, and generalizable VLA adaptation.
SSMG-Nav: Enhancing Lifelong Object Navigation with Semantic Skeleton Memory Graph
Mar 02, 2026Navigating to out-of-sight targets from human instructions in unfamiliar environments is a core capability for service robots. Despite substantial progress, most approaches underutilize reusable, persistent memory, constraining performance in lifelong settings. Many are additionally limited to single-modality inputs and employ myopic greedy policies, which often induce inefficient back-and-forth maneuvers (BFMs). To address such limitations, we introduce SSMG-Nav, a framework for object navigation built on a \textit{Semantic Skeleton Memory Graph} (SSMG) that consolidates past observations into a spatially aligned, persistent memory anchored by topological keypoints (e.g., junctions, room centers). SSMG clusters nearby entities into subgraphs, unifying entity- and space-level semantics to yield a compact set of candidate destinations. To support multimodal targets (images, objects, and text), we integrate a vision-language model (VLM). For each subgraph, a multimodal prompt synthesized from memory guides the VLM to infer a target belief over destinations. A long-horizon planner then trades off this belief against traversability costs to produce a visit sequence that minimizes expected path length, thereby reducing backtracking. Extensive experiments on challenging lifelong benchmarks and standard ObjectNav benchmarks demonstrate that, compared to strong baselines, our method achieves higher success rates and greater path efficiency, validating the effectiveness of SSMG-Nav.
An Online Adaptation Method for Robust Depth Estimation and Visual Odometry in the Open World
Apr 16, 2025Recently, learning-based robotic navigation systems have gained extensive research attention and made significant progress. However, the diversity of open-world scenarios poses a major challenge for the generalization of such systems to practical scenarios. Specifically, learned systems for scene measurement and state estimation tend to degrade when the application scenarios deviate from the training data, resulting to unreliable depth and pose estimation. Toward addressing this problem, this work aims to develop a visual odometry system that can fast adapt to diverse novel environments in an online manner. To this end, we construct a self-supervised online adaptation framework for monocular visual odometry aided by an online-updated depth estimation module. Firstly, we design a monocular depth estimation network with lightweight refiner modules, which enables efficient online adaptation. Then, we construct an objective for self-supervised learning of the depth estimation module based on the output of the visual odometry system and the contextual semantic information of the scene. Specifically, a sparse depth densification module and a dynamic consistency enhancement module are proposed to leverage camera poses and contextual semantics to generate pseudo-depths and valid masks for the online adaptation. Finally, we demonstrate the robustness and generalization capability of the proposed method in comparison with state-of-the-art learning-based approaches on urban, in-house datasets and a robot platform. Code is publicly available at: https://github.com/jixingwu/SOL-SLAM.
A Skeleton-Based Topological Planner for Exploration in Complex Unknown Environments
Dec 18, 2024



The capability of autonomous exploration in complex, unknown environments is important in many robotic applications. While recent research on autonomous exploration have achieved much progress, there are still limitations, e.g., existing methods relying on greedy heuristics or optimal path planning are often hindered by repetitive paths and high computational demands. To address such limitations, we propose a novel exploration framework that utilizes the global topology information of observed environment to improve exploration efficiency while reducing computational overhead. Specifically, global information is utilized based on a skeletal topological graph representation of the environment geometry. We first propose an incremental skeleton extraction method based on wavefront propagation, based on which we then design an approach to generate a lightweight topological graph that can effectively capture the environment's structural characteristics. Building upon this, we introduce a finite state machine that leverages the topological structure to efficiently plan coverage paths, which can substantially mitigate the back-and-forth maneuvers (BFMs) problem. Experimental results demonstrate the superiority of our method in comparison with state-of-the-art methods. The source code will be made publicly available at: \url{https://github.com/Haochen-Niu/STGPlanner}.
Explicit Mutual Information Maximization for Self-Supervised Learning
Sep 11, 2024Recently, self-supervised learning (SSL) has been extensively studied. Theoretically, mutual information maximization (MIM) is an optimal criterion for SSL, with a strong theoretical foundation in information theory. However, it is difficult to directly apply MIM in SSL since the data distribution is not analytically available in applications. In practice, many existing methods can be viewed as approximate implementations of the MIM criterion. This work shows that, based on the invariance property of MI, explicit MI maximization can be applied to SSL under a generic distribution assumption, i.e., a relaxed condition of the data distribution. We further illustrate this by analyzing the generalized Gaussian distribution. Based on this result, we derive a loss function based on the MIM criterion using only second-order statistics. We implement the new loss for SSL and demonstrate its effectiveness via extensive experiments.
Analyzing and Bridging the Gap between Maximizing Total Reward and Discounted Reward in Deep Reinforcement Learning
Jul 18, 2024In deep reinforcement learning applications, maximizing discounted reward is often employed instead of maximizing total reward to ensure the convergence and stability of algorithms, even though the performance metric for evaluating the policy remains the total reward. However, the optimal policies corresponding to these two objectives may not always be consistent. To address this issue, we analyzed the suboptimality of the policy obtained through maximizing discounted reward in relation to the policy that maximizes total reward and identified the influence of hyperparameters. Additionally, we proposed sufficient conditions for aligning the optimal policies of these two objectives under various settings. The primary contributions are as follows: We theoretically analyzed the factors influencing performance when using discounted reward as a proxy for total reward, thereby enhancing the theoretical understanding of this scenario. Furthermore, we developed methods to align the optimal policies of the two objectives in certain situations, which can improve the performance of reinforcement learning algorithms.
Symmetry Awareness Encoded Deep Learning Framework for Brain Imaging Analysis
Jul 12, 2024
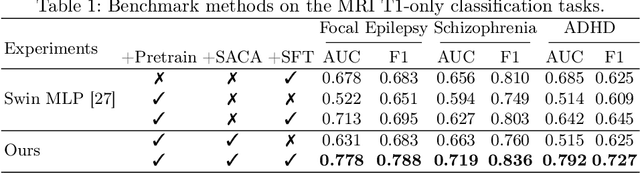


The heterogeneity of neurological conditions, ranging from structural anomalies to functional impairments, presents a significant challenge in medical imaging analysis tasks. Moreover, the limited availability of well-annotated datasets constrains the development of robust analysis models. Against this backdrop, this study introduces a novel approach leveraging the inherent anatomical symmetrical features of the human brain to enhance the subsequent detection and segmentation analysis for brain diseases. A novel Symmetry-Aware Cross-Attention (SACA) module is proposed to encode symmetrical features of left and right hemispheres, and a proxy task to detect symmetrical features as the Symmetry-Aware Head (SAH) is proposed, which guides the pretraining of the whole network on a vast 3D brain imaging dataset comprising both healthy and diseased brain images across various MRI and CT. Through meticulous experimentation on downstream tasks, including both classification and segmentation for brain diseases, our model demonstrates superior performance over state-of-the-art methodologies, particularly highlighting the significance of symmetry-aware learning. Our findings advocate for the effectiveness of incorporating symmetry awareness into pretraining and set a new benchmark for medical imaging analysis, promising significant strides toward accurate and efficient diagnostic processes. Code is available at https://github.com/bitMyron/sa-swin.