 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rise and Down of Babel Tower: Investigating the Evolution Process of Multilingual Code Large Language Model
Dec 10, 2024



Large language models (LLMs) have shown significant multilingual capabilities. However, the mechanisms underlying the development of these capabilities during pre-training are not well understood. In this paper, we use code LLMs as an experimental platform to explore the evolution of multilingual capabilities in LLMs during the pre-training process. Based on our observations, we propose the Babel Tower Hypothesis, which describes the entire process of LLMs acquiring new language capabilities. During the learning process, multiple languages initially share a single knowledge system dominated by the primary language and gradually develop language-specific knowledge systems. We then validate the above hypothesis by tracking the internal states of the LLMs through identifying working languages and language transferring neurons. Experimental results show that the internal state changes of the LLM are consistent with our Babel Tower Hypothesis. Building on these insights, we propose a novel method to construct an optimized pre-training corpus for multilingual code LLMs, which significantly outperforms LLMs trained on the original corpus. The proposed Babel Tower Hypothesis provides new insights into designing pre-training data distributions to achieve optimal multilingual capabilities in LLMs.
StructEval: Deepen and Broaden Large Language Model Assessment via Structured Evaluation
Aug 07, 2024Evaluation is the baton for the development of large language models. Current evaluations typically employ a single-item assessment paradigm for each atomic test objective, which struggles to discern whether a model genuinely possesses the required capabilities or merely memorizes/guesses the answers to specific questions. To this end, we propose a novel evaluation framework referred to as StructEval. Starting from an atomic test objective, StructEval deepens and broadens the evaluation by conducting a structured assessment across multiple cognitive levels and critical concepts, and therefore offers a comprehensive, robust and consistent evaluation for LLMs. Experiments on three widely-used benchmarks demonstrate that StructEval serves as a reliable tool for resisting the risk of data contamination and reducing the interference of potential biases, thereby providing more reliable and consistent conclusions regarding model capabilities. Our framework also sheds light on the design of future principled and trustworthy LLM evaluation protocols.
Towards Scalable Automated Alignment of LLMs: A Survey
Jun 03, 2024Alignment is the most critical step in building large language models (LLMs) that meet human needs. With the rapid development of LLMs gradually surpassing human capabilities, traditional alignment methods based on human-annotation are increasingly unable to meet the scalability demands. Therefore, there is an urgent need to explore new sources of automated alignment signals and technical approaches. In this paper, we systematically review the recently emerging methods of automated alignment, attempting to explore how to achieve effective, scalable, automated alignment once the capabilities of LLMs exceed those of humans. Specifically, we categorize existing automated alignment methods into 4 major categories based on the sources of alignment signals and discuss the current status and potential development of each category. Additionally, we explore the underlying mechanisms that enable automated alignment and discuss the essential factors that make automated alignment technologies feasible and effective from the fundamental role of alignment.
Learning or Self-aligning? Rethinking Instruction Fine-tuning
Mar 02, 2024



Instruction Fine-tuning~(IFT) is a critical phase in building large language models~(LLMs). Previous works mainly focus on the IFT's role in the transfer of behavioral norms and the learning of additional world knowledge. However, the understanding of the underlying mechanisms of IFT remains significantly limited. In this paper, we design a knowledge intervention framework to decouple the potential underlying factors of IFT, thereby enabling individual analysis of different factors. Surprisingly, our experiments reveal that attempting to learn additional world knowledge through IFT often struggles to yield positive impacts and can even lead to markedly negative effects. Further, we discover that maintaining internal knowledge consistency before and after IFT is a critical factor for achieving successful IFT. Our findings reveal the underlying mechanisms of IFT and provide robust support for some very recent and potential future works.
AI for social science and social science of AI: A Survey
Jan 22, 2024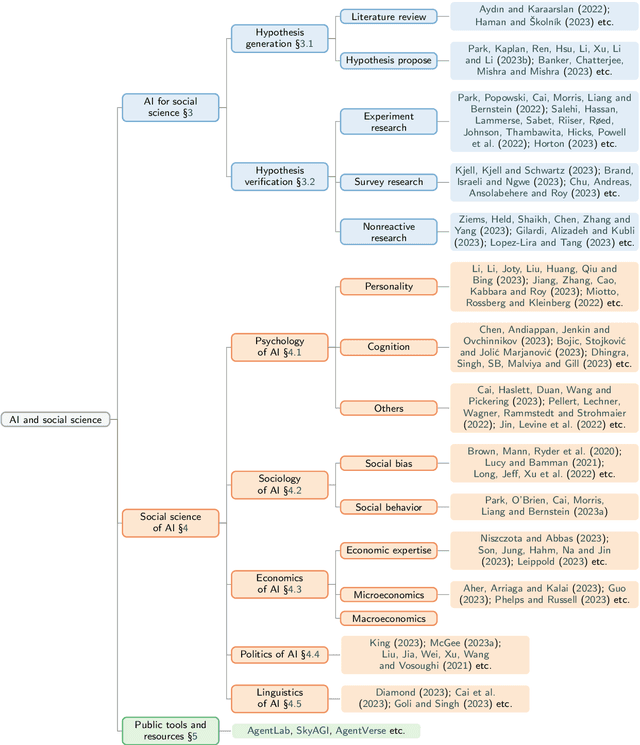
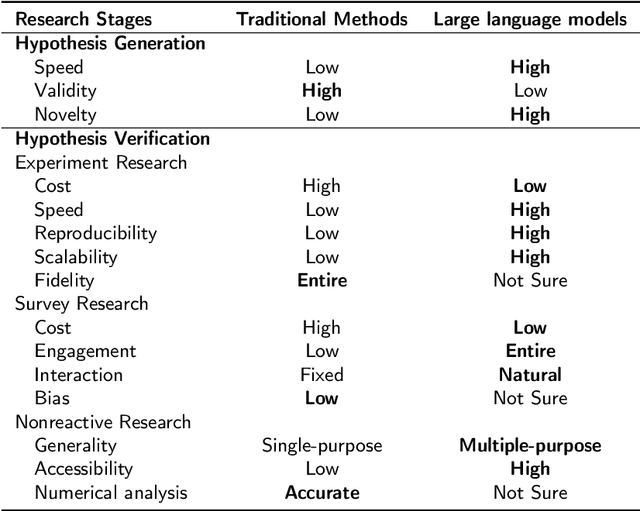
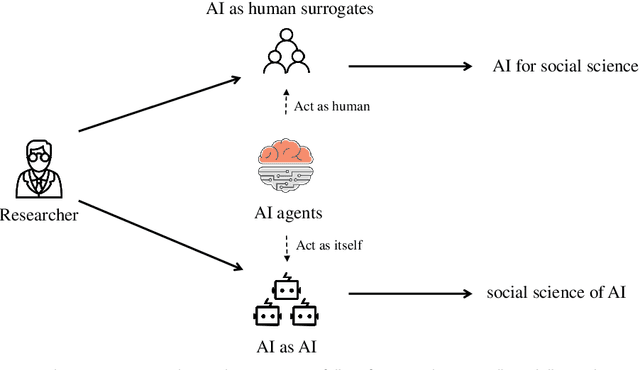
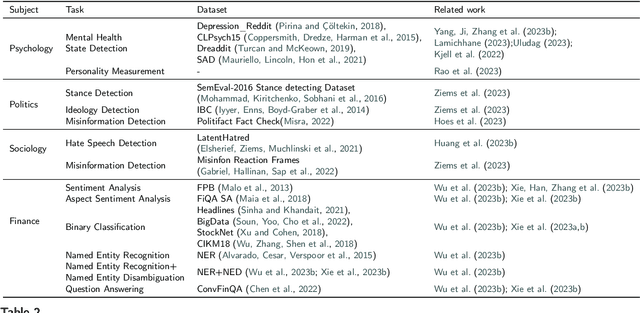
Recent advancements in artificial intelligence, particularly with the emergence of large language models (LLMs), have sparked a rethinking of artificial general intelligence possibilities. The increasing human-like capabilities of AI are also attracting attention in social science research, leading to various studies exploring the combination of these two fields. In this survey, we systematically categorize previous explorations in the combination of AI and social science into two directions that share common technical approaches but differ in their research objectives. The first direction is focused on AI for social science, where AI is utilized as a powerful tool to enhance various stages of social science research. While the second direction is the social science of AI, which examines AI agents as social entities with their human-like cognitive and linguistic capabilities. By conducting a thorough review, particularly on the substantial progress facilitated by recent advancements in large language models, this paper introduces a fresh perspective to reassess the relationship between AI and social science, provides a cohesive framework that allows researchers to understand the distinctions and connections between AI for social science and social science of AI, and also summarized state-of-art experiment simulation platforms to facilitate research in these two directions. We believe that as AI technology continues to advance and intelligent agents find increasing applications in our daily lives, the significance of the combination of AI and social science will become even more prominent.