 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context or Local Detail? Adaptive Visual Grounding for Hallucination Mitigation
Apr 27, 2026Vision-Language Models (VLMs) are frequently undermined by object hallucination--generating content that contradicts visual reality--due to an over-reliance on linguistic priors. We introduce Positive-and-Negative Decoding (PND), a training-free inference framework that intervenes directly in the decoding process to enforce visual fidelity. PND is motivated by our key finding of a critical attention deficit in VLMs, where visual features are empirically under-weighted. Our framework corrects this via a dual-path contrast: The positive path amplifies salient visual evidence using multi-layer attention to encourage faithful descriptions, directly counteracting the attention deficit. Simultaneously, the negative path identifies and degrades the core object's features to create a strong counterfactual, which penalizes ungrounded, prior-dominant generation. By contrasting the model's outputs from these two perspectives at each step, PND steers generation towards text that is not just linguistically probable, but visually factual. Extensive experiments on benchmarks like POPE, MME, and CHAIR show that PND achieves state-of-the-art performance with up to 6.5% accuracy improvement, substantially reducing object hallucination while also enhancing descriptive detail--all without requiring any model retraining. The method generalizes effectively across diverse VLM architectures including LLaVA, InstructBLIP, InternVL, and Qwen-VL.
V-tableR1: Process-Supervised Multimodal Table Reasoning with Critic-Guided Policy Optimization
Apr 22, 2026We introduce V-tableR1, a process-supervised reinforcement learning framework that elicits rigorous, verifiable reasoning from multimodal large language models (MLLMs). Current MLLMs trained solely on final outcomes often treat visual reasoning as a black box, relying on superficial pattern matching rather than performing rigorous multi-step inference. While Reinforcement Learning with Verifiable Rewards could enforce transparent reasoning trajectories, extending it to visual domains remains severely hindered by the ambiguity of grounding abstract logic into continuous pixel space. We solve this by leveraging the deterministic grid structure of tables as an ideal visual testbed. V-tableR1 employs a specialized critic VLM to provide dense, step-level feedback on the explicit visual chain-of-thought generated by a policy VLM. To optimize this system, we propose Process-Guided Direct Alignment Policy Optimization (PGPO), a novel RL algorithm integrating process rewards, decoupled policy constraints, and length-aware dynamic sampling. Extensive evaluations demonstrate that V-tableR1 explicitly penalizes visual hallucinations and shortcut guessing. By fundamentally shifting multimodal inference from black-box pattern matching to verifiable logical derivation, V-tableR1 4B establishes state-of-the-art accuracy among open-source models on complex tabular benchmarks, outperforming models up to 18x its size and improving over its SFT baseline
Silo-Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi-Agent LLM Systems
Mar 01, 2026Large language models are increasingly deployed in multi-agent systems to overcome context limitations by distributing information across agents. Yet whether agents can reliably compute with distributed information -- rather than merely exchange it -- remains an open question. We introduce Silo-Bench, a role-agnostic benchmark of 30 algorithmic tasks across three communication complexity levels, evaluating 54 configurations over 1,620 experiments. Our experiments expose a fundamental Communication-Reasoning Gap: agents spontaneously form task-appropriate coordination topologies and exchange information actively, yet systematically fail to synthesize distributed state into correct answers. The failure is localized to the reasoning-integration stage -- agents often acquire sufficient information but cannot integrate it. This coordination overhead compounds with scale, eventually eliminating parallelization gains entirely. These findings demonstrate that naively scaling agent count cannot circumvent context limitations, and Silo-Bench provides a foundation for tracking progress toward genuinely collaborative multi-agent systems.
TRIP-Bench: A Benchmark for Long-Horizon Interactive Agents in Real-World Scenarios
Feb 02, 2026As LLM-based agents are deployed in increasingly complex real-world settings, existing benchmarks underrepresent key challenges such as enforcing global constraints, coordinating multi-tool reasoning, and adapting to evolving user behavior over long, multi-turn interactions. To bridge this gap, we introduce \textbf{TRIP-Bench}, a long-horizon benchmark grounded in realistic travel-planning scenarios. TRIP-Bench leverages real-world data, offers 18 curated tools and 40+ travel requirements, and supports automated evaluation. It includes splits of varying difficulty; the hard split emphasizes long and ambiguous interactions, style shifts, feasibility changes, and iterative version revision. Dialogues span up to 15 user turns, can involve 150+ tool calls, and may exceed 200k tokens of context. Experiments show that even advanced models achieve at most 50\% success on the easy split, with performance dropping below 10\% on hard subsets. We further propose \textbf{GTPO}, an online multi-turn reinforcement learning method with specialized reward normalization and reward differencing. Applied to Qwen2.5-32B-Instruct, GTPO improves constraint satisfaction and interaction robustness, outperforming Gemini-3-Pro in our evaluation. We expect TRIP-Bench to advance practical long-horizon interactive agents, and GTPO to provide an effective online RL recipe for robust long-horizon training.
DIFFA-2: A Practical Diffusion Large Language Model for General Audio Understanding
Jan 30, 2026Autoregressive (AR) large audio language models (LALMs) such as Qwen-2.5-Omni have achieved strong performance on audio understanding and interaction, but scaling them remains costly in data and computation, and strictly sequential decoding limits inference efficiency. Diffusion large language models (dLLMs) have recently been shown to make effective use of limited training data, and prior work on DIFFA indicates that replacing an AR backbone with a diffusion counterpart can substantially improve audio understanding under matched settings, albeit at a proof-of-concept scale without large-scale instruction tuning, preference alignment, or practical decoding schemes. We introduce DIFFA-2, a practical diffusion-based LALM for general audio understanding. DIFFA-2 upgrades the speech encoder, employs dual semantic and acoustic adapters, and is trained with a four-stage curriculum that combines semantic and acoustic alignment, large-scale supervised fine-tuning, and variance-reduced preference optimization, using only fully open-source corpora. Experiments on MMSU, MMAU, and MMAR show that DIFFA-2 consistently improves over DIFFA and is competitive to strong AR LALMs under practical training budgets, supporting diffusion-based modeling is a viable backbone for large-scale audio understanding. Our code is available at https://github.com/NKU-HLT/DIFFA.git.
Reflecting Twice before Speaking with Empathy: Self-Reflective Alternating Inference for Empathy-Aware End-to-End Spoken Dialogue
Jan 26, 2026End-to-end Spoken Language Models (SLMs) hold great potential for paralinguistic perception, and numerous studies have aimed to enhance their capabilities, particularly for empathetic dialogue. However, current approaches largely depend on rigid supervised signals, such as ground-truth response in supervised fine-tuning or preference scores in reinforcement learning. Such reliance is fundamentally limited for modeling complex empathy, as there is no single "correct" response and a simple numerical score cannot fully capture the nuances of emotional expression or the appropriateness of empathetic behavior. To address these limitations, we sequentially introduce EmpathyEval, a descriptive natural-language-based evaluation model for assessing empathetic quality in spoken dialogues. Building upon EmpathyEval, we propose ReEmpathy, an end-to-end SLM that enhances empathetic dialogue through a novel Empathetic Self-Reflective Alternating Inference mechanism, which interleaves spoken response generation with free-form, empathy-related reflective reasoning. Extensive experiments demonstrate that ReEmpathy substantially improves empathy-sensitive spoken dialogue by enabling reflective reasoning, offering a promising approach toward more emotionally intelligent and empathy-aware human-computer interactions.
Learning or Self-aligning? Rethinking Instruction Fine-tuning
Mar 02, 2024



Instruction Fine-tuning~(IFT) is a critical phase in building large language models~(LLMs). Previous works mainly focus on the IFT's role in the transfer of behavioral norms and the learning of additional world knowledge. However, the understanding of the underlying mechanisms of IFT remains significantly limited. In this paper, we design a knowledge intervention framework to decouple the potential underlying factors of IFT, thereby enabling individual analysis of different factors. Surprisingly, our experiments reveal that attempting to learn additional world knowledge through IFT often struggles to yield positive impacts and can even lead to markedly negative effects. Further, we discover that maintaining internal knowledge consistency before and after IFT is a critical factor for achieving successful IFT. Our findings reveal the underlying mechanisms of IFT and provide robust support for some very recent and potential future works.
Generative Calibration for In-context Learning
Oct 16, 2023



As one of the most exciting features of large language models (LLMs), in-context learning is a mixed blessing. While it allows users to fast-prototype a task solver with only a few training examples, the performance is generally sensitive to various configurations of the prompt such as the choice or order of the training examples. In this paper, we for the first time theoretically and empirically identify that such a paradox is mainly due to the label shift of the in-context model to the data distribution, in which LLMs shift the label marginal $p(y)$ while having a good label conditional $p(x|y)$. With this understanding, we can simply calibrate the in-context predictive distribution by adjusting the label marginal, which is estimated via Monte-Carlo sampling over the in-context model, i.e., generation of LLMs. We call our approach as generative calibration. We conduct exhaustive experiments with 12 text classification tasks and 12 LLMs scaling from 774M to 33B, generally find that the proposed method greatly and consistently outperforms the ICL as well as state-of-the-art calibration methods, by up to 27% absolute in macro-F1. Meanwhile, the proposed method is also stable under different prompt configurations.
Interpreting Sentiment Composition with Latent Semantic Tree
Aug 31, 2023
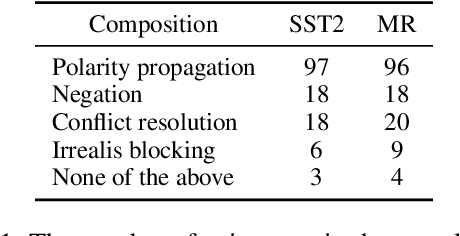
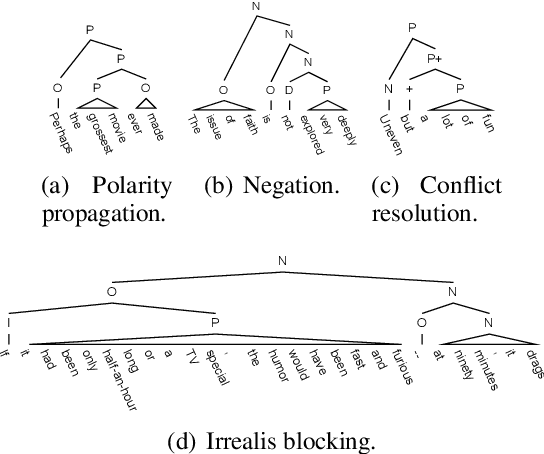

As the key to sentiment analysis, sentiment composition considers the classification of a constituent via classifications of its contained sub-constituents and rules operated on them. Such compositionality has been widely studied previously in the form of hierarchical trees including untagged and sentiment ones, which are intrinsically suboptimal in our view. To address this, we propose semantic tree, a new tree form capable of interpreting the sentiment composition in a principled way. Semantic tree is a derivation of a context-free grammar (CFG) describing the specific composition rules on difference semantic roles, which is designed carefully following previous linguistic conclusions. However, semantic tree is a latent variable since there is no its annotation in regular datasets. Thus, in our method, it is marginalized out via inside algorithm and learned to optimize the classification performance. Quantitative and qualitative results demonstrate that our method not only achieves better or competitive results compared to baselines in the setting of regular and domain adaptation classification, and also generates plausible tree explanations.
MME-CRS: Multi-Metric Evaluation Based on Correlation Re-Scaling for Evaluating Open-Domain Dialogue
Jun 19, 2022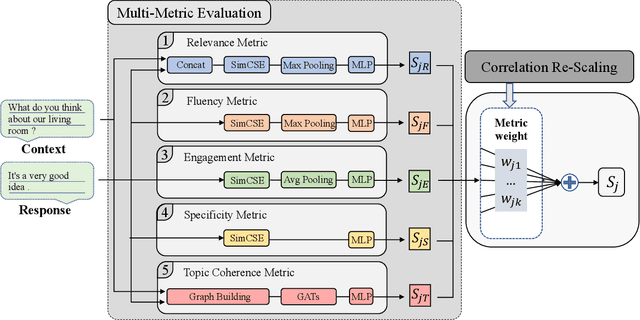
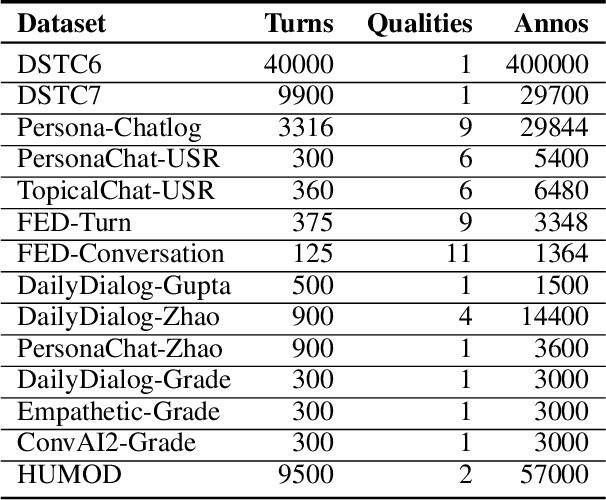

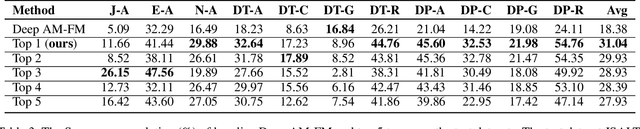
Automatic open-domain dialogue evaluation is a crucial component of dialogue systems. Recently, learning-based evaluation metrics have achieved state-of-the-art performance in open-domain dialogue evaluation. However, these metrics, which only focus on a few qualities, are hard to evaluate dialogue comprehensively. Furthermore, these metrics lack an effective score composition approach for diverse evaluation qualities. To address the above problems, we propose a Multi-Metric Evaluation based on Correlation Re-Scaling (MME-CRS) for evaluating open-domain dialogue. Firstly, we build an evaluation metric composed of 5 groups of parallel sub-metrics called Multi-Metric Evaluation (MME) to evaluate the quality of dialogue comprehensively. Furthermore, we propose a novel score composition method called Correlation Re-Scaling (CRS) to model the relationship between sub-metrics and diverse qualities. Our approach MME-CRS ranks first on the final test data of DSTC10 track5 subtask1 Automatic Open-domain Dialogue Evaluation Challenge with a large margin, which proved the effectiveness of our proposed approach.