 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Privacy-Preserving Framework for Advertising Personalization Incorporating Federated Learning and Differential Privacy
Jul 16, 2025To mitigate privacy leakage and performance issues in personalized advertising, this paper proposes a framework that integrates federated learning and differential privacy. The system combines distributed feature extraction, dynamic privacy budget allocation, and robust model aggregation to balance model accuracy, communication overhead, and privacy protection. Multi-party secure computing and anomaly detection mechanisms further enhance system resilience against malicious attacks. Experimental results demonstrate that the framework achieves dual optimization of recommendation accuracy and system efficiency while ensuring privacy, providing both a practical solution and a theoretical foundation for applying privacy protection technologies in advertisement recommendation.
Does Knowledge Localization Hold True? Surprising Differences Between Entity and Relation Perspectives in Language Models
Sep 01, 2024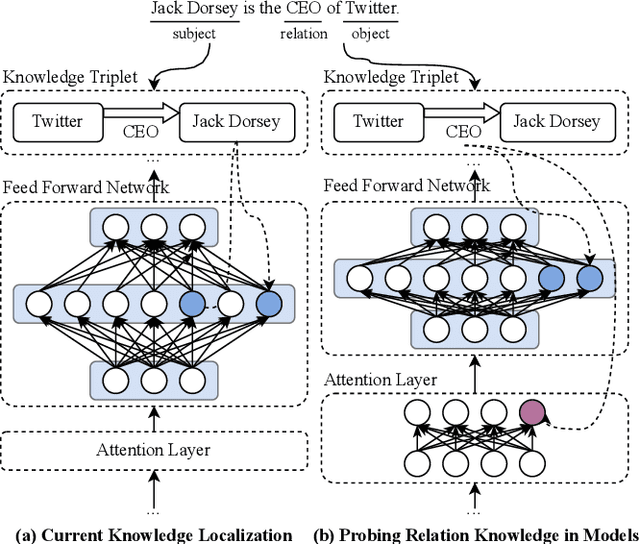
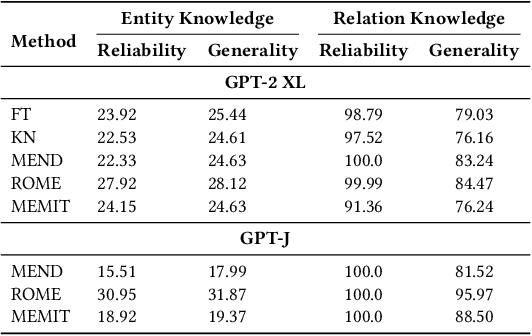

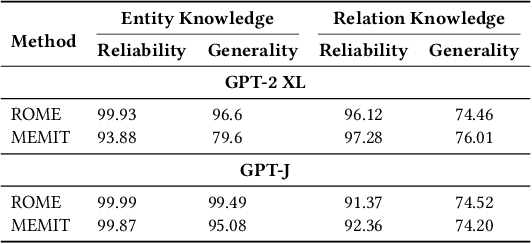
Large language models encapsulate knowledge and have demonstrated superior performance on various natural language processing tasks. Recent studies have localized this knowledge to specific model parameters, such as the MLP weights in intermediate layers. This study investigates the differences between entity and relational knowledge through knowledge editing. Our findings reveal that entity and relational knowledge cannot be directly transferred or mapped to each other. This result is unexpected, as logically, modifying the entity or the relation within the same knowledge triplet should yield equivalent outcomes. To further elucidate the differences between entity and relational knowledge, we employ causal analysis to investigate how relational knowledge is stored in pre-trained models. Contrary to prior research suggesting that knowledge is stored in MLP weights, our experiments demonstrate that relational knowledge is also significantly encoded in attention modules. This insight highlights the multifaceted nature of knowledge storage in language models, underscoring the complexity of manipulating specific types of knowledge within these models.
From Instance Training to Instruction Learning: Task Adapters Generation from Instructions
Jun 18, 2024



Large language models (LLMs) have acquired the ability to solve general tasks by utilizing instruction finetuning (IFT). However, IFT still relies heavily on instance training of extensive task data, which greatly limits the adaptability of LLMs to real-world scenarios where labeled task instances are scarce and broader task generalization becomes paramount. Contrary to LLMs, humans acquire skills and complete tasks not merely through repeated practice but also by understanding and following instructional guidelines. This paper is dedicated to simulating human learning to address the shortcomings of instance training, focusing on instruction learning to enhance cross-task generalization. Within this context, we introduce Task Adapters Generation from Instructions (TAGI), which automatically constructs the task-specific model in a parameter generation manner based on the given task instructions without retraining for unseen tasks. Specifically, we utilize knowledge distillation to enhance the consistency between TAGI developed through Learning with Instruction and task-specific models developed through Training with Instance, by aligning the labels, output logits, and adapter parameters between them. TAGI is endowed with cross-task generalization capabilities through a two-stage training process that includes hypernetwork pretraining and finetuning. We evaluate TAGI on the Super-Natural Instructions and P3 datasets. The experimental results demonstrate that TAGI can match or even outperform traditional meta-trained models and other hypernetwork models, while significantly reducing computational requirements.
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
Mar 28, 2024



Retrieval-Augmented-Generation and Gener-ation-Augmented-Generation have been proposed to enhance the knowledge required for question answering over Large Language Models (LLMs). However, the former depends on external resources, and both require incorporating the explicit documents into the context, which results in longer contexts that lead to more resource consumption. Recent works indicate that LLMs have modeled rich knowledge, albeit not effectively triggered or activated. Inspired by this, we propose a novel knowledge-augmented framework, Imagination-Augmented-Generation (IAG), which simulates the human capacity to compensate for knowledge deficits while answering questions solely through imagination, without relying on external resources. Guided by IAG, we propose an imagine richer context method for question answering (IMcQA), which obtains richer context through the following two modules: explicit imagination by generating a short dummy document with long context compress and implicit imagination with HyperNetwork for generating adapter weights. Experimental results on three datasets demonstrate that IMcQA exhibits significant advantages in both open-domain and closed-book settings, as well as in both in-distribution performance and out-of-distribution generalizations. Our code will be available at https://github.com/Xnhyacinth/IAG.
Generative Calibration for In-context Learning
Oct 16, 2023



As one of the most exciting features of large language models (LLMs), in-context learning is a mixed blessing. While it allows users to fast-prototype a task solver with only a few training examples, the performance is generally sensitive to various configurations of the prompt such as the choice or order of the training examples. In this paper, we for the first time theoretically and empirically identify that such a paradox is mainly due to the label shift of the in-context model to the data distribution, in which LLMs shift the label marginal $p(y)$ while having a good label conditional $p(x|y)$. With this understanding, we can simply calibrate the in-context predictive distribution by adjusting the label marginal, which is estimated via Monte-Carlo sampling over the in-context model, i.e., generation of LLMs. We call our approach as generative calibration. We conduct exhaustive experiments with 12 text classification tasks and 12 LLMs scaling from 774M to 33B, generally find that the proposed method greatly and consistently outperforms the ICL as well as state-of-the-art calibration methods, by up to 27% absolute in macro-F1. Meanwhile, the proposed method is also stable under different prompt configurations.
MenatQA: A New Dataset for Testing the Temporal Comprehension and Reasoning Abilities of Large Language Models
Oct 08, 2023



Large language models (LLMs) have shown nearly saturated performance on many natural language processing (NLP) tasks. As a result, it is natural for people to believe that LLMs have also mastered abilities such as time understanding and reasoning. However, research on the temporal sensitivity of LLMs has been insufficiently emphasized. To fill this gap, this paper constructs Multiple Sensitive Factors Time QA (MenatQA), which encompasses three temporal factors (scope factor, order factor, counterfactual factor) with total 2,853 samples for evaluating the time comprehension and reasoning abilities of LLMs. This paper tests current mainstream LLMs with different parameter sizes, ranging from billions to hundreds of billions. The results show most LLMs fall behind smaller temporal reasoning models with different degree on these factors. In specific, LLMs show a significant vulnerability to temporal biases and depend heavily on the temporal information provided in questions. Furthermore, this paper undertakes a preliminary investigation into potential improvement strategies by devising specific prompts and leveraging external tools. These approaches serve as valuable baselines or references for future research endeavors.
Unsupervised Text Style Transfer with Deep Generative Models
Aug 31, 2023



We present a general framework for unsupervised text style transfer with deep generative models. The framework models each sentence-label pair in the non-parallel corpus as partially observed from a complete quadruplet which additionally contains two latent codes representing the content and style, respectively. These codes are learned by exploiting dependencies inside the observed data. Then a sentence is transferred by manipulating them. Our framework is able to unify previous embedding and prototype methods as two special forms. It also provides a principled perspective to explain previously proposed techniques in the field such as aligned encoder and adversarial training. We further conduct experiments on three benchmarks. Both automatic and human evaluation results show that our methods achieve better or competitive results compared to several strong baselines.
Interpreting Sentiment Composition with Latent Semantic Tree
Aug 31, 2023
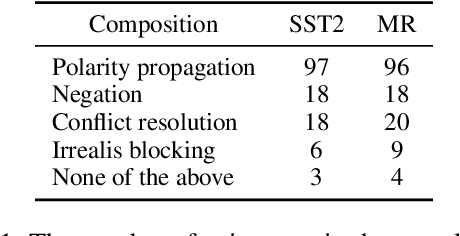
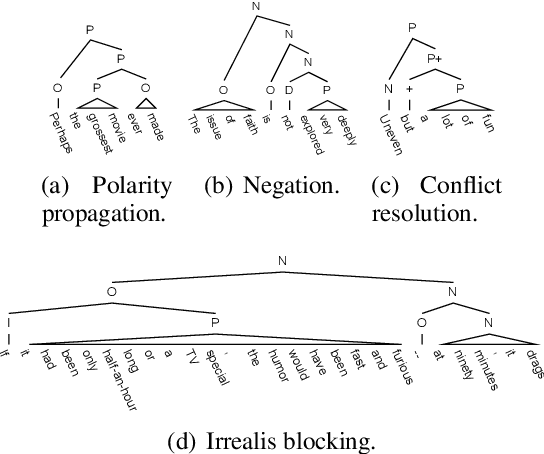

As the key to sentiment analysis, sentiment composition considers the classification of a constituent via classifications of its contained sub-constituents and rules operated on them. Such compositionality has been widely studied previously in the form of hierarchical trees including untagged and sentiment ones, which are intrinsically suboptimal in our view. To address this, we propose semantic tree, a new tree form capable of interpreting the sentiment composition in a principled way. Semantic tree is a derivation of a context-free grammar (CFG) describing the specific composition rules on difference semantic roles, which is designed carefully following previous linguistic conclusions. However, semantic tree is a latent variable since there is no its annotation in regular datasets. Thus, in our method, it is marginalized out via inside algorithm and learned to optimize the classification performance. Quantitative and qualitative results demonstrate that our method not only achieves better or competitive results compared to baselines in the setting of regular and domain adaptation classification, and also generates plausible tree explanations.
Multi-View Graph Representation Learning for Answering Hybrid Numerical Reasoning Question
May 05, 2023



Hybrid question answering (HybridQA) over the financial report contains both textual and tabular data, and requires the model to select the appropriate evidence for the numerical reasoning task. Existing methods based on encoder-decoder framework employ a expression tree-based decoder to solve numerical reasoning problems. However, encoders rely more on Machine Reading Comprehension (MRC) methods, which take table serialization and text splicing as input, damaging the granularity relationship between table and text as well as the spatial structure information of table itself. In order to solve these problems, the paper proposes a Multi-View Graph (MVG) Encoder to take the relations among the granularity into account and capture the relations from multiple view. By utilizing MVGE as a module, we constuct Tabular View, Relation View and Numerical View which aim to retain the original characteristics of the hybrid data. We validate our model on the publicly available table-text hybrid QA benchmark (TAT-QA) and outperform the state-of-the-art model.
TxAllo: Dynamic Transaction Allocation in Sharded Blockchain Systems
Dec 22, 2022


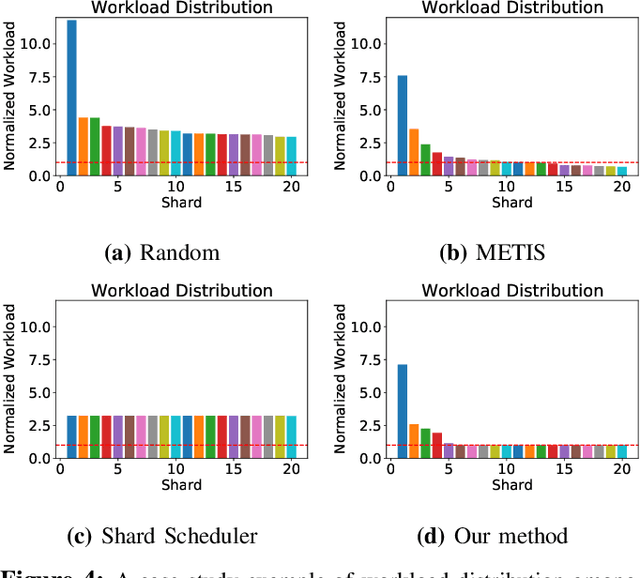
The scalability problem has been one of the most significant barriers limiting the adoption of blockchains. Blockchain sharding is a promising approach to this problem. However, the sharding mechanism introduces a significant number of cross-shard transactions, which are expensive to process. This paper focuses on the transaction allocation problem to reduce the number of cross-shard transactions for better scalability. In particular, we systematically formulate the transaction allocation problem and convert it to the community detection problem on a graph. A deterministic and fast allocation scheme TxAllo is proposed to dynamically infer the allocation of accounts and their associated transactions. It directly optimizes the system throughput, considering both the number of cross-shard transactions and the workload balance among shards. We evaluate the performance of TxAllo on an Ethereum dataset containing over 91 million transactions. Our evaluation results show that for a blockchain with 60 shards, TxAllo reduces the cross-shard transaction ratio from 98% (by using traditional hash-based allocation) to about 12%. In the meantime, the workload balance is well maintained. Compared with other methods, the execution time of TxAllo is almost negligible. For example, when updating the allocation every hour, the execution of TxAllo only takes 0.5 seconds on average, whereas other concurrent works, such as BrokerChain (INFOCOM'22) leveraging the classic METIS method, require 422 seconds.