 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTxRay: Agentic Postmortem of Live Blockchain Attacks
Feb 01, 2026Decentralized Finance (DeFi) has turned blockchains into financial infrastructure, allowing anyone to trade, lend, and build protocols without intermediaries, but this openness exposes pools of value controlled by code. Within five years, the DeFi ecosystem has lost over 15.75B USD to reported exploits. Many exploits arise from permissionless opportunities that any participant can trigger using only public state and standard interfaces, which we call Anyone-Can-Take (ACT) opportunities. Despite on-chain transparency, postmortem analysis remains slow and manual: investigations start from limited evidence, sometimes only a single transaction hash, and must reconstruct the exploit lifecycle by recovering related transactions, contract code, and state dependencies. We present TxRay, a Large Language Model (LLM) agentic postmortem system that uses tool calls to reconstruct live ACT attacks from limited evidence. Starting from one or more seed transactions, TxRay recovers the exploit lifecycle, derives an evidence-backed root cause, and generates a runnable, self-contained Proof of Concept (PoC) that deterministically reproduces the incident. TxRay self-checks postmortems by encoding incident-specific semantic oracles as executable assertions. To evaluate PoC correctness and quality, we develop PoCEvaluator, an independent agentic execution-and-review evaluator. On 114 incidents from DeFiHackLabs, TxRay produces an expert-aligned root cause and an executable PoC for 105 incidents, achieving 92.11% end-to-end reproduction. Under PoCEvaluator, 98.1% of TxRay PoCs avoid hard-coding attacker addresses, a +24.8pp lift over DeFiHackLabs. In a live deployment, TxRay delivers validated root causes in 40 minutes and PoCs in 59 minutes at median latency. TxRay's oracle-validated PoCs enable attack imitation, improving coverage by 15.6% and 65.5% over STING and APE.
Large Language Models for Cryptocurrency Transaction Analysis: A Bitcoin Case Study
Jan 30, 2025



Cryptocurrencies are widely used, yet current methods for analyzing transactions heavily rely on opaque, black-box models. These lack interpretability and adaptability, failing to effectively capture behavioral patterns. Many researchers, including us, believe that Large Language Models (LLMs) could bridge this gap due to their robust reasoning abilities for complex tasks. In this paper, we test this hypothesis by applying LLMs to real-world cryptocurrency transaction graphs, specifically within the Bitcoin network. We introduce a three-tiered framework to assess LLM capabilities: foundational metrics, characteristic overview, and contextual interpretation. This includes a new, human-readable graph representation format, LLM4TG, and a connectivity-enhanced sampling algorithm, CETraS, which simplifies larger transaction graphs. Experimental results show that LLMs excel at foundational metrics and offer detailed characteristic overviews. Their effectiveness in contextual interpretation suggests they can provide useful explanations of transaction behaviors, even with limited labeled data.
New Bounds on the Accuracy of Majority Voting for Multi-Class Classification
Sep 18, 2023Majority voting is a simple mathematical function that returns the value that appears most often in a set. As a popular decision fusion technique, the majority voting function (MVF) finds applications in resolving conflicts, where a number of independent voters report their opinions on a classification problem. Despite its importance and its various applications in ensemble learning, data crowd-sourcing, remote sensing, and data oracles for blockchains, the accuracy of the MVF for the general multi-class classification problem has remained unknown. In this paper, we derive a new upper bound on the accuracy of the MVF for the multi-class classification problem. More specifically, we show that under certain conditions, the error rate of the MVF exponentially decays toward zero as the number of independent voters increases. Conversely, the error rate of the MVF exponentially grows with the number of independent voters if these conditions are not met. We first explore the problem for independent and identically distributed voters where we assume that every voter follows the same conditional probability distribution of voting for different classes, given the true classification of the data point. Next, we extend our results for the case where the voters are independent but non-identically distributed. Using the derived results, we then provide a discussion on the accuracy of the truth discovery algorithms. We show that in the best-case scenarios, truth discovery algorithms operate as an amplified MVF and thereby achieve a small error rate only when the MVF achieves a small error rate, and vice versa, achieve a large error rate when the MVF also achieves a large error rate. In the worst-case scenario, the truth discovery algorithms may achieve a higher error rate than the MVF. Finally, we confirm our theoretical results using numerical simulations.
TxAllo: Dynamic Transaction Allocation in Sharded Blockchain Systems
Dec 22, 2022


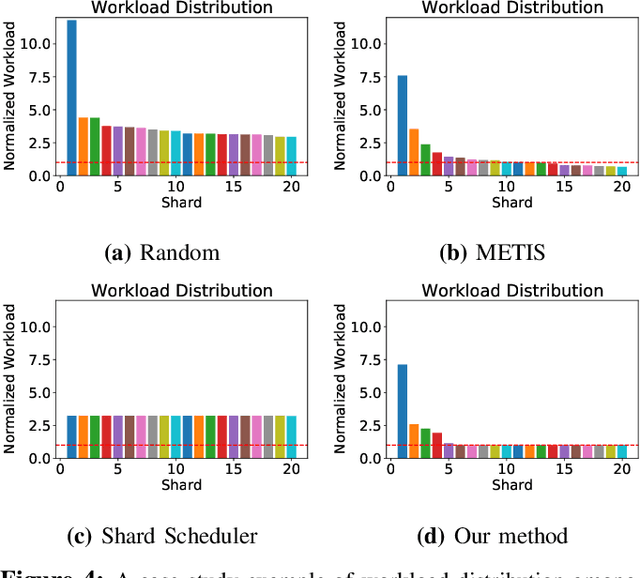
The scalability problem has been one of the most significant barriers limiting the adoption of blockchains. Blockchain sharding is a promising approach to this problem. However, the sharding mechanism introduces a significant number of cross-shard transactions, which are expensive to process. This paper focuses on the transaction allocation problem to reduce the number of cross-shard transactions for better scalability. In particular, we systematically formulate the transaction allocation problem and convert it to the community detection problem on a graph. A deterministic and fast allocation scheme TxAllo is proposed to dynamically infer the allocation of accounts and their associated transactions. It directly optimizes the system throughput, considering both the number of cross-shard transactions and the workload balance among shards. We evaluate the performance of TxAllo on an Ethereum dataset containing over 91 million transactions. Our evaluation results show that for a blockchain with 60 shards, TxAllo reduces the cross-shard transaction ratio from 98% (by using traditional hash-based allocation) to about 12%. In the meantime, the workload balance is well maintained. Compared with other methods, the execution time of TxAllo is almost negligible. For example, when updating the allocation every hour, the execution of TxAllo only takes 0.5 seconds on average, whereas other concurrent works, such as BrokerChain (INFOCOM'22) leveraging the classic METIS method, require 422 seconds.
Semantic Code Search for Smart Contracts
Nov 28, 2021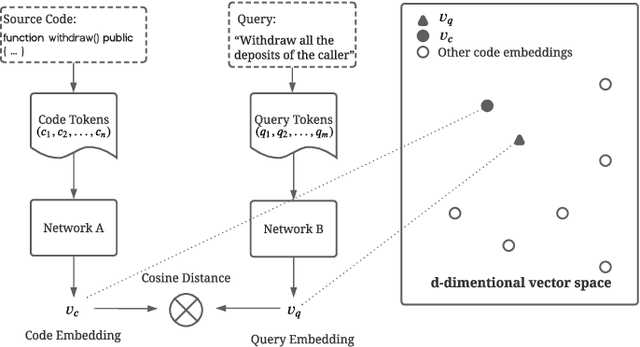
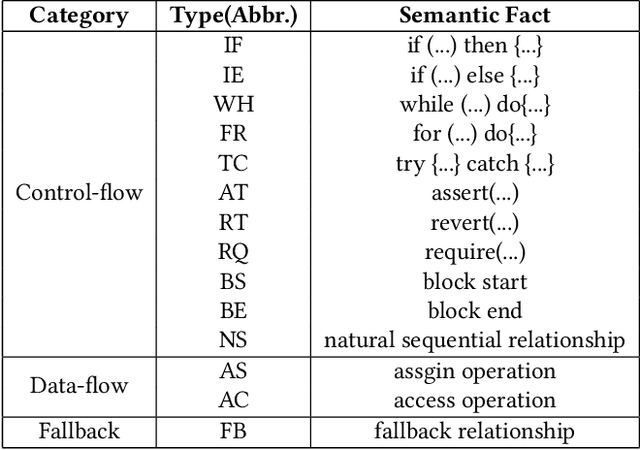
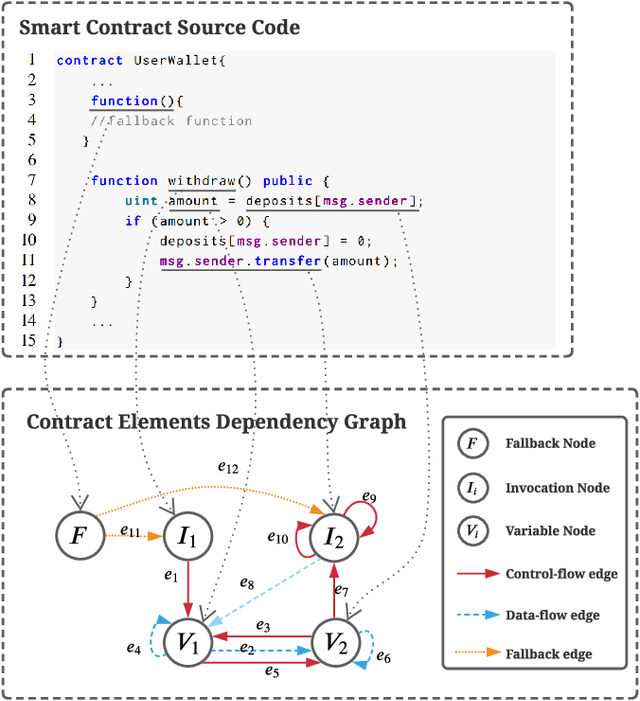
Semantic code search technology allows searching for existing code snippets through natural language, which can greatly improve programming efficiency. Smart contracts, programs that run on the blockchain, have a code reuse rate of more than 90%, which means developers have a great demand for semantic code search tools. However, the existing code search models still have a semantic gap between code and query, and perform poorly on specialized queries of smart contracts. In this paper, we propose a Multi-Modal Smart contract Code Search (MM-SCS) model. Specifically, we construct a Contract Elements Dependency Graph (CEDG) for MM-SCS as an additional modality to capture the data-flow and control-flow information of the code. To make the model more focused on the key contextual information, we use a multi-head attention network to generate embeddings for code features. In addition, we use a fine-tuned pretrained model to ensure the model's effectiveness when the training data is small. We compared MM-SCS with four state-of-the-art models on a dataset with 470K (code, docstring) pairs collected from Github and Etherscan. Experimental results show that MM-SCS achieves an MRR (Mean Reciprocal Rank) of 0.572, outperforming four state-of-the-art models UNIF, DeepCS, CARLCS-CNN, and TAB-CS by 34.2%, 59.3%, 36.8%, and 14.1%, respectively. Additionally, the search speed of MM-SCS is second only to UNIF, reaching 0.34s/query.
How to Democratise and Protect AI: Fair and Differentially Private Decentralised Deep Learning
Jul 18, 2020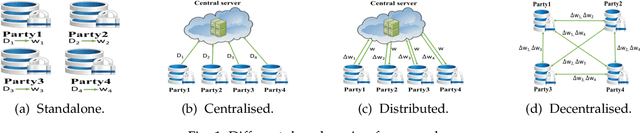


This paper firstly considers the research problem of fairness in collaborative deep learning, while ensuring privacy. A novel reputation system is proposed through digital tokens and local credibility to ensure fairness, in combination with differential privacy to guarantee privacy. In particular, we build a fair and differentially private decentralised deep learning framework called FDPDDL, which enables parties to derive more accurate local models in a fair and private manner by using our developed two-stage scheme: during the initialisation stage, artificial samples generated by Differentially Private Generative Adversarial Network (DPGAN) are used to mutually benchmark the local credibility of each party and generate initial tokens; during the update stage, Differentially Private SGD (DPSGD) is used to facilitate collaborative privacy-preserving deep learning, and local credibility and tokens of each party are updated according to the quality and quantity of individually released gradients. Experimental results on benchmark datasets under three realistic settings demonstrate that FDPDDL achieves high fairness, yields comparable accuracy to the centralised and distributed frameworks, and delivers better accuracy than the standalone framework.
Towards Fair and Decentralized Privacy-Preserving Deep Learning with Blockchain
Jun 04, 2019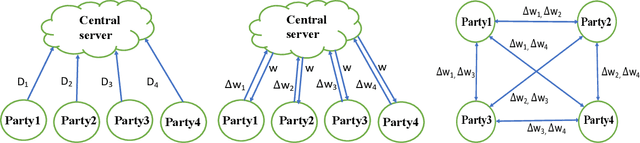
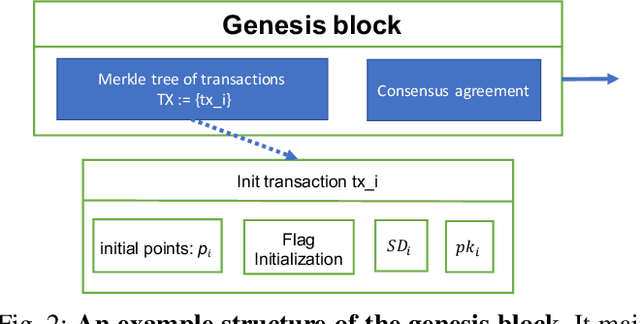
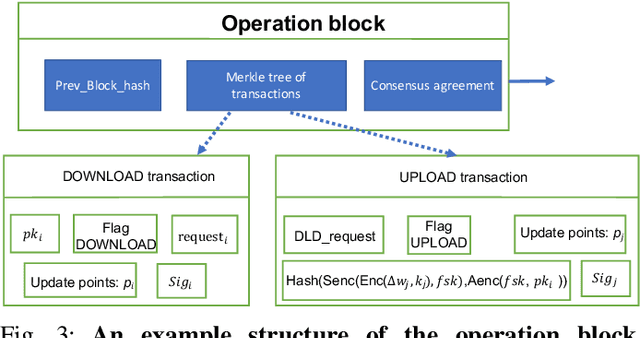

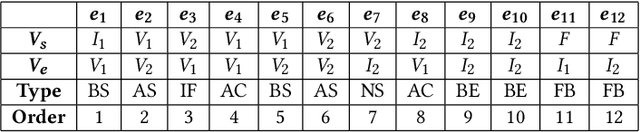
In collaborative deep learning, current learning frameworks follow either a centralized architecture or a distributed architecture. Whilst centralized architecture deploys a central server to train a global model over the massive amount of joint data from all parties, distributed architecture aggregates parameter updates from participating parties' local model training, via a parameter server. These two server-based architectures present security and robustness vulnerabilities such as single-point-of-failure, single-point-of-breach, privacy leakage, and lack of fairness. To address these problems, we design, implement, and evaluate a purely decentralized privacy-preserving deep learning framework, called DPPDL. DPPDL makes the first investigation on the research problem of fairness in collaborative deep learning, and simultaneously provides fairness and privacy by proposing two novel algorithms: initial benchmarking and privacy-preserving collaborative deep learning. During initial benchmarking, each party trains a local Differentially Private Generative Adversarial Network (DPGAN) and publishes the generated privacy-preserving artificial samples for other parties to label, based on the quality of which to initialize local credibility list for other parties. The local credibility list reflects how much one party contributes to another party, and it is used and updated during collaborative learning to ensure fairness. To protect gradients transaction during privacy-preserving collaborative deep learning, we further put forward a three-layer onion-style encryption scheme. We experimentally demonstrate, on benchmark image datasets, that accuracy, privacy and fairness in collaborative deep learning can be effectively addressed at the same time by our proposed DPPDL framework. Moreover, DPPDL provides a viable solution to detect and isolate the cheating party in the system.