 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D User Localization for Planar Arrays in LoS Near- and Far-Fields via Summed Phase Differences
Apr 01, 2026This paper presents a phase-difference-based scheme for three-dimensional (3D) line-of-sight (LoS) user localization using a uniform planar array (UPA), applicable to both near-field and far-field regimes under the exact spherical-wave model. Unlike the previously studied two-dimensional (2D) uniform linear array (ULA) case, the 3D UPA case requires jointly exploiting the two array axes in order to recover the user's range, azimuth, and zenith angle. Adjacent-antenna phase-differences are first estimated from uplink pilots and then summed along the array axes to obtain unwrapped phase-differences between widely separated antenna elements. These summed phase-differences enable the construction of multiple three-equation systems whose solutions yield the user's range, azimuth, and zenith angle. We quantify the number of such equation systems, provide a representative closed-form estimator that uses only three phase-difference sums, and propose an all-data nonlinear least-squares estimator that exploits all available sums. Numerical results show that the least-squares estimator, when initialized by the closed-form estimate, achieves Cramér--Rao bound accuracy. Moreover, unlike state-of-the-art baseline schemes, whose performance depends on well-tuned hyperparameters, the proposed estimators are hyperparameter-free.
LO-Free Phase and Amplitude Recovery of an RF Signal with a DC-Stark-Enabled Rydberg Receiver
Mar 31, 2026We present a theoretical framework for recovering the amplitude and carrier phase of a single received RF field with a Rydberg-atom receiver, without injecting an RF local oscillator (LO) into the atoms. The key enabling mechanism is a static DC bias applied to the vapor cell: by Stark-mixing a near-degenerate Rydberg pair, the bias activates an otherwise absent upper optical pathway and closes a phase-sensitive loop within a receiver driven only by the standard probe/coupling pair and the received RF field. For a spatially uniform bias, we derive an effective four-level rotating-frame Hamiltonian of Floquet form and show that the periodic steady state obeys an exact harmonic phase law, so that the $n$th probe harmonic carries the factor $e^{inΦ_S}$. This yields direct estimators for the signal phase and amplitude from a demodulated probe harmonic, with amplitude recovery obtained by inverting an injective harmonic response map. In the high-SNR regime, we derive explicit RMSE laws and use them to identify distinct phase-optimal and amplitude-optimal bias-controlled mixing angles, together with a weighted joint-design criterion and a balanced compromise angle that equalizes the fractional phase and amplitude penalties. We then extend the analysis to nonuniform DC bias through quasistatic spatial averaging and show that bias inhomogeneity reduces coherent gain for phase readout while also reshaping the amplitude-response slope. Numerical examples validate the phase law, illustrate response-map inversion and mixing-angle trade-offs, and quantify the penalties induced by bias nonuniformity. The results establish a minimal route to coherent Rydberg reception of a single RF signal without an auxiliary RF LO in the atoms.
Hybrid Beamforming via Programmable Unitary RF Networks
Mar 18, 2026Conventional hybrid beamforming architectures are often compared with one another and with the fully-digital architecture under the same \emph{radiated} antenna power. However, the physically relevant budget is the power injected by the RF-chain outputs into the passive analog RF network, which is then usually transferred to the antenna ports in a contractive (lossy) manner. This issue is especially pronounced for fully-connected splitter--phase-shifter--combiner networks, whose physical power transfer remains contractive even under ideal passive-component assumptions. Motivated by this injected-power viewpoint, this paper proposes a hybrid beamforming architecture based on a programmable unitary RF network. Under ideal passive-component assumptions, all injected RF-chain power reaches the antenna ports without loss. The analog RF network is realized as an \emph{interlaced mixer--phase} architecture consisting of fixed (non-programmable) mixing layers interleaved with programmable diagonal phase-shifting layers. We derive a closed-form digital beamformer and a low-complexity programming method for the analog beamformer, yielding a hybrid precoder that closely matches the fully-digital precoder. Narrowband simulations with continuous and quantized phases, benchmarked against the fully-digital architecture, the physically modeled fully-connected phase-shifter baselines, and an ideal-lossless Butler/DFT beam-selection baseline under equal total injected RF-chain power, show that the continuous-phase and 6-bit realizations of the proposed architecture are nearly indistinguishable from the fully-digital benchmark and achieve significant gains over the baseline hybrid beamforming architectures.
A Narrowband Fully-Analog Multi-Antenna Transmitter
Feb 03, 2026This paper proposes a narrowband fully-analog $N$-antenna transmitter that emulates the functionality of a narrowband fully-digital $N$-antenna transmitter. Specifically, in symbol interval $m$, the proposed fully-analog transmitter synthesizes an arbitrary complex excitation vector $\bm x[m]\in\mathbb{C}^N$ with prescribed total power $\|\bm x[m]\|_2^2=P$ from a single coherent RF tone, using only tunable phase-control elements embedded in a passive interferometric programmable network. The programmable network is excited through one input port while the remaining $N - 1$ input ports are impedance matched. In the ideal lossless case, the network transfer is unitary and therefore redistributes RF power among antenna ports without dissipative amplitude control. The synthesis task is posed as a unitary state-preparation problem: program a unitary family so that $\bm V(\bm\varphi)\bm e_1=\bm c$, where $\bm c=\bm x/\sqrt{P}$ and $\|\bm c\|_2=1$. We provide a constructive realization and a closed-form programming rule: a binary magnitude-splitting tree allocates the desired per-antenna magnitudes $|c_n|$ using $N -1$ tunable split ratios, and a per-antenna output phase bank assigns the target phases using $N$ tunable phase shifts. The resulting architecture uses $2N-1$ real tunable degrees of freedom and admits a deterministic $O(N)$ programming procedure with no iterative optimization, enabling symbol-by-symbol updates when the chosen phase-control technology supports the required tuning speed. Using representative COTS components, we model the RF-front-end DC power of the proposed fully-analog transmitter and compare it against an equivalent COTS fully-digital array. For $N\le 16$, the comparison indicates significant RF-front-end power savings for the fully-analog architecture. The results in this paper are intended as a proof-of-concept for a narrowband fully-analog transmitter.
A Method For Bounding Tail Probabilities
Feb 22, 2024


We present a method for upper and lower bounding the right and the left tail probabilities of continuous random variables (RVs). For the right tail probability of RV $X$ with probability density function $f_X(x)$, this method requires first setting a continuous, positive, and strictly decreasing function $g_X(x)$ such that $-f_X(x)/g'_X(x)$ is a decreasing and increasing function, $\forall x>x_0$, which results in upper and lower bounds, respectively, given in the form $-f_X(x) g_X(x)/g'_X(x)$, $\forall x>x_0$, where $x_0$ is some point. Similarly, for the upper and lower bounds on the left tail probability of $X$, this method requires first setting a continuous, positive, and strictly increasing function $g_X(x)$ such that $f_X(x)/g'_X(x)$ is an increasing and decreasing function, $\forall x<x_0$, which results in upper and lower bounds, respectively, given in the form $f_X(x) g_X(x)/g'_X(x)$, $\forall x<x_0$. We provide some examples of good candidates for the function $g_X(x)$. We also establish connections between the new bounds and Markov's inequality and Chernoff's bound. In addition, we provide an iterative method for obtaining ever tighter lower and upper bounds, under certain conditions. Finally, we provide numerical examples, where we show the tightness of these bounds, for some chosen $g_X(x)$.
A New Type Of Upper And Lower Bounds On Right-Tail Probabilities Of Continuous Random Variables
Nov 27, 2023In this paper, I present a completely new type of upper and lower bounds on the right-tail probabilities of continuous random variables with unbounded support and with semi-bounded support from the left. The presented upper and lower right-tail bounds depend only on the probability density function (PDF), its first derivative, and two parameters that are used for tightening the bounds. These tail bounds hold under certain conditions that depend on the PDF, its first and second derivatives, and the two parameters. The new tail bounds are shown to be tight for a wide range of continuous random variables via numerical examples.
New Bounds on the Accuracy of Majority Voting for Multi-Class Classification
Sep 18, 2023Majority voting is a simple mathematical function that returns the value that appears most often in a set. As a popular decision fusion technique, the majority voting function (MVF) finds applications in resolving conflicts, where a number of independent voters report their opinions on a classification problem. Despite its importance and its various applications in ensemble learning, data crowd-sourcing, remote sensing, and data oracles for blockchains, the accuracy of the MVF for the general multi-class classification problem has remained unknown. In this paper, we derive a new upper bound on the accuracy of the MVF for the multi-class classification problem. More specifically, we show that under certain conditions, the error rate of the MVF exponentially decays toward zero as the number of independent voters increases. Conversely, the error rate of the MVF exponentially grows with the number of independent voters if these conditions are not met. We first explore the problem for independent and identically distributed voters where we assume that every voter follows the same conditional probability distribution of voting for different classes, given the true classification of the data point. Next, we extend our results for the case where the voters are independent but non-identically distributed. Using the derived results, we then provide a discussion on the accuracy of the truth discovery algorithms. We show that in the best-case scenarios, truth discovery algorithms operate as an amplified MVF and thereby achieve a small error rate only when the MVF achieves a small error rate, and vice versa, achieve a large error rate when the MVF also achieves a large error rate. In the worst-case scenario, the truth discovery algorithms may achieve a higher error rate than the MVF. Finally, we confirm our theoretical results using numerical simulations.
UB3: Best Beam Identification in Millimeter Wave Systems via Pure Exploration Unimodal Bandits
Dec 26, 2022Millimeter wave (mmWave) communications have a broad spectrum and can support data rates in the order of gigabits per second, as envisioned in 5G systems. However, they cannot be used for long distances due to their sensitivity to attenuation loss. To enable their use in the 5G network, it requires that the transmission energy be focused in sharp pencil beams. As any misalignment between the transmitter and receiver beam pair can reduce the data rate significantly, it is important that they are aligned as much as possible. To find the best transmit-receive beam pair, recent beam alignment (BA) techniques examine the entire beam space, which might result in a large amount of BA latency. Recent works propose to adaptively select the beams such that the cumulative reward measured in terms of received signal strength or throughput is maximized. In this paper, we develop an algorithm that exploits the unimodal structure of the received signal strengths of the beams to identify the best beam in a finite time using pure exploration strategies. Strategies that identify the best beam in a fixed time slot are more suitable for wireless network protocol design than cumulative reward maximization strategies that continuously perform exploration and exploitation. Our algorithm is named Unimodal Bandit for Best Beam (UB3) and identifies the best beam with a high probability in a few rounds. We prove that the error exponent in the probability does not depend on the number of beams and show that this is indeed the case by establishing a lower bound for the unimodal bandits. We demonstrate that UB3 outperforms the state-of-the-art algorithms through extensive simulations. Moreover, our algorithm is simple to implement and has lower computational complexity.
Parametric Channel Model Estimation for Large Intelligent Surface-Based Transceiver-assisted Communication System
Apr 05, 2022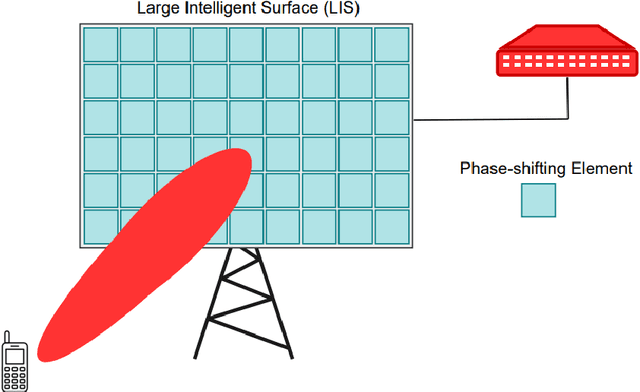
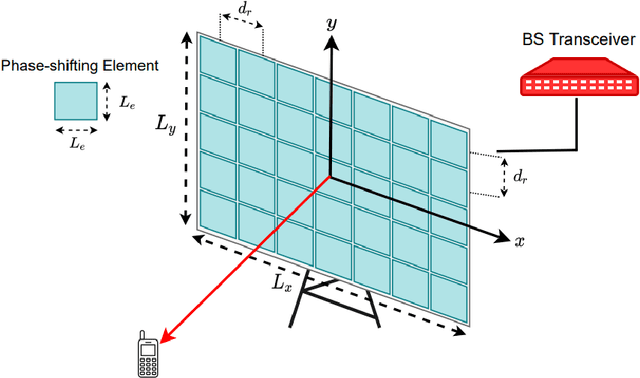

The number of connected mobile devices and the amount of data traffic through these devices are expected to grow many-fold in future communication networks. To support the scale of this huge data traffic, more and more base stations and wireless terminals are required to be deployed in existing networks. Nevertheless, practically deploying a large number of base stations having massive antenna arrays will substantially increase the hardware cost and power consumption of the network. A promising approach for enhancing the coverage and rate of wireless communication systems is the large intelligent surface-based transceiver (LISBT), which uses a spatially continuous surface for signal transmission and receiving. A typical LIS consists of a planar array having a large number of reflecting metamaterial elements (e.g., low-cost printed dipoles), each of which could act as a phase shift. It is also considered to be a cost effective and energy efficient solution. Accurate channel state information (CSI) in LISBT-assisted wireless communication systems is critical for achieving these goals. In this paper, we propose a channel estimation scheme based on the physical parameters of the system. that requires only five pilot signals to perfectly estimate the channel parameters assuming there is no noise at the receiver. In the presence of noise, we propose an iterative estimation algorithm that decreases the channel estimation error due to noise. The proposed scheme's training overhead and computational cost do not grow with the number of antennas, unlike previous work on enormous multiple-input multiple-output (MIMO). The channel estimate scheme based on the physical properties of the Large intelligent surface-based transceiver (LISBT)-assisted wireless communication systems is the subject of our future study.
Channel Estimation for Large Intelligent Surface-Based Transceiver Using a Parametric Channel Model
Dec 06, 2021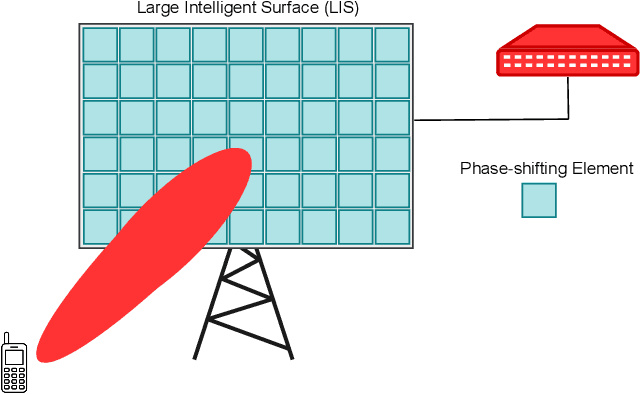
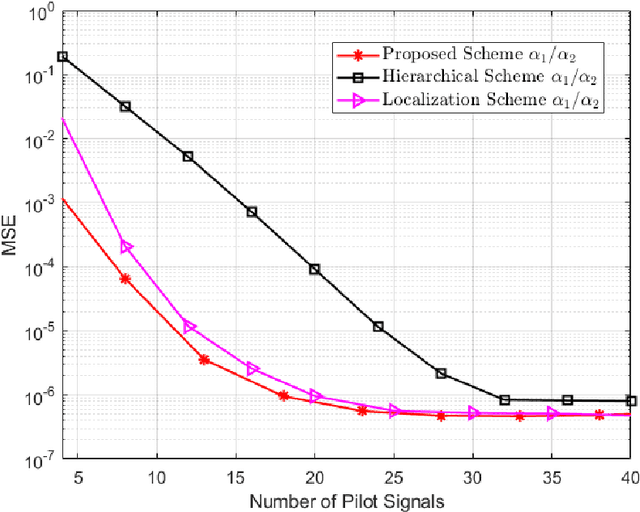
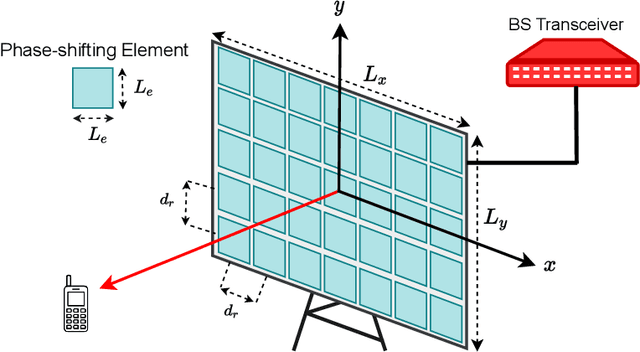
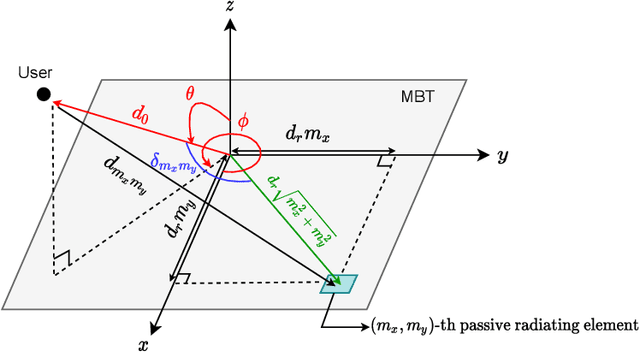
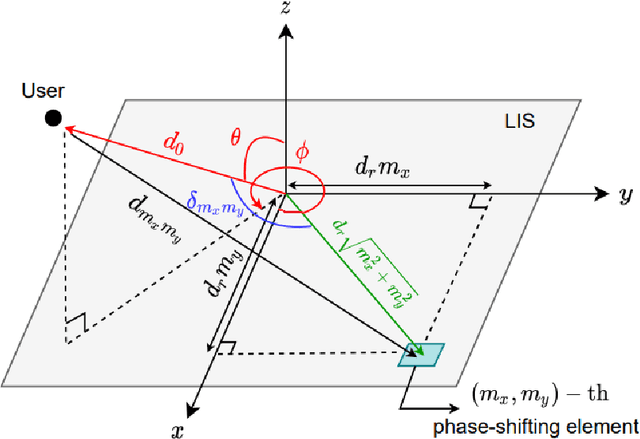
Large intelligent surface-based transceivers (LISBTs), in which a spatially continuous surface is being used for signal transmission and reception, have emerged as a promising solution for improving the coverage and data rate of wireless communication systems. To realize these objectives, the acquisition of accurate channel state information (CSI) in LISBT-assisted wireless communication systems is crucial. In this paper, we propose a channel estimation scheme based on a parametric physical channel model for line-of-sight dominated communication in millimeter and terahertz wave bands. The proposed estimation scheme requires only five pilot signals to perfectly estimate the channel parameters assuming there is no noise at the receiver. In the presence of noise, we propose an iterative estimation algorithm that decreases the channel estimation error due to noise. The training overhead and computational cost of the proposed scheme do not scale with the number of antennas. The simulation results demonstrate that the proposed estimation scheme significantly outperforms other benchmark schemes.